


其实版本陆陆续续有递交到pypi,只是今天做一个阶段性的总结。当前版本号为v2.5.1,近期的一些修改主要对 OpenAI API 的兼容性做了一些增强,同时更新覆盖实时性、准确率、功能广度、工程稳定性四个维度。 最新版本 v2.5.1,已经上传到pypi,有需要的同学可以下载安装来体验一下。 安装:pip install oddasr运行:oddasr 一、实时转写:首字时延从 1.5~2s 砍到 ~0.5s 在 v2.5.1 更新中最值得关注的性能优化 同时新增配置项 streaming_buffer_chunk_size(默认 4800,即 300ms 缓冲),方便手动调优服务端缓冲策略。 为了方便查看和统计时延,本次还为转写流程中每一个重点功能都加上了时延统计,便于线上观测与回归对比。 二、新功能上线 1. 热词(Hotwords)支持 Paraformer / SenseVoice 后端现已支持热词功能,可在转写时注入业务专有词,显著提升专有名词、人名、术语的识别准确率。 服务端做了优化:只在热词实际发生变化时才记录日志(比较新旧值),避免高频音频传输路径上日志刷屏。 2. diarized_json 返回格式 在 OpenAI 兼容的 response_format 基础上,新增 diarized_json,返回带说话人角色的结构化结果,方便直接消费”谁在什么时候说了什么”。老接口里说话人角色分离的接口依然可用:response_format:spk。 3. 字词级时间戳(word-level timestamps) verbose_json 模式下支持 OpenAI 兼容的 word-level 时间戳请求参数,可控制返回文本是否带每个字的时间戳,并修复了音字对照时间戳错位、英文单词间空格导致解析异常等问题。 4. 多种音频格式 […]
会议室数字孪生:低成本方案探索 最近参加会议时,大佬们聊到了会议室空间智能和数字孪生的方向,让我想起了以前做「小落同学」时研究过的VR看房伪3D技术。周末在家翻出旧代码,搭了个基础框架。 🎯 先看效果 没有专业全景相机,从网上找了两张实景图,用 Gemini 生成了两张效果图,写了个 demo。 核心展示维度: UI是随手搭的,重点看技术可行性~ 实拍图: 会议室1:来自百度图片,侵删 会议室2:来自百度图片,侵删 AI生成图: 会议室3:用 Gemini 生成的图片 会议室4:用 Gemini 生成的图片 🏗️ 两种方案对比 传统方案(高大上但贵) 看完这个周末的成果后,我们再来分析一下,一个常规的数字孪生平台的总体架构应该是什么样子的。 传统方案需要激光雷达、深度相机等专业设备,生成高精度点云模型,再进行纹理映射和材质渲染。效果最佳,但实施成本高、开通流程复杂。 简化方案(轻量级) 参考VR看房思路,用普通全景相机拍摄,拼接成2:1全景图,用three.js,pano2vr或者 CSS3D 渲染成静态3D模型。 🚀 开通流程(设想) 总耗时:约1~1.5小时 对接内容:预约情况、实时状态、历史统计 💡 技术选型思路 方案以最低硬件要求为出发点(最初想在老笔记本上跑),高硬件需求的方案都被我忽视了。目前只是技术可行性验证,后续看领导安排,希望能给有类似需求的小伙伴提供参考~
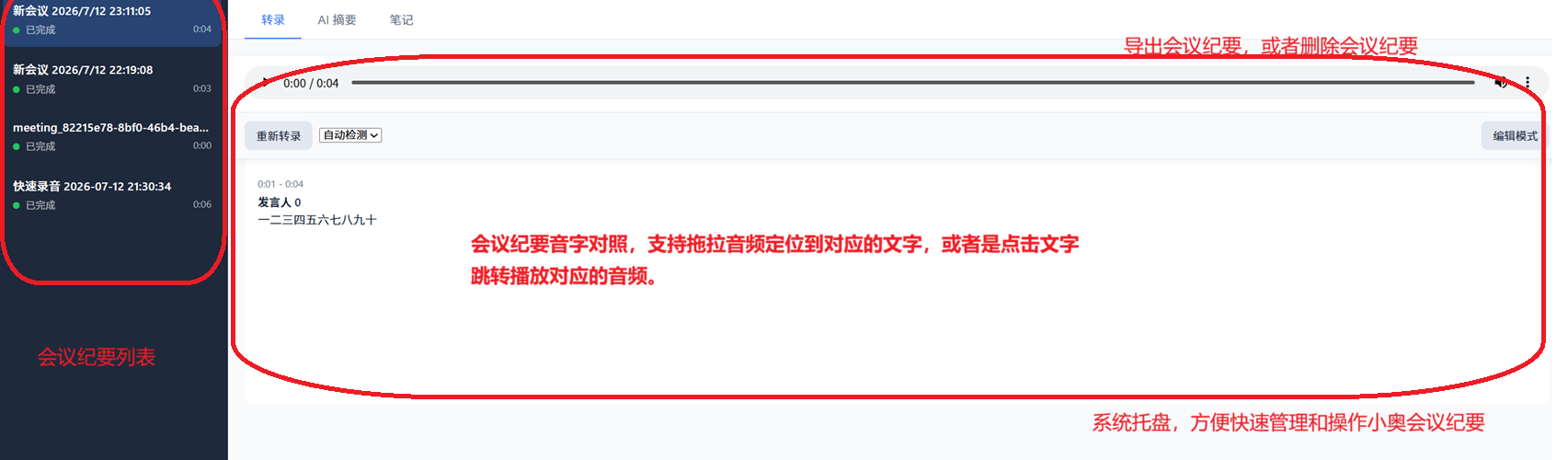
省流精华 小奥录音 OddMinutes 做了许多的功能优化更新,包含大量功能新增、体验优化和 Bug 修复,并正式发布了 v0.1.6 版本。一起来看看都更新了什么吧! 1. 代码仓库 OddMinutes 2. 使用方法 1) 绿色免安装包 直接下载绿色免安装包,下载后解压缩,双击执行 OddMinutes.exe 【国外】github下载: https://github.com/oddmeta/oddminutes/release 【国内】gitee下载: https://gitee.com/oddmeta/oddminutes/releases 2)Pypi安装 在命令行中安装 运行 更详尽的使用说明可以参考之前的文档介绍: https://www.oddmeta.net/archives/10499.html。 一、新功能上线 1. 一键修复音字对齐 在编辑模式按钮旁新增了「修复音字对齐」按钮。点击后,系统会自动对当前会议的音频文件进行静音裁剪处理,并更新会议音频时长。处理完成后会通知前端用户,用户只需手动重新转录即可看到音字对齐效果。 2. 转录前自动静音裁剪 在音频入库后、ASR 转录之前,新增了头尾静音裁剪预处理功能——自动删除音频开头和结尾能量过低、无法被实际转录的内容,提升转录质量。 3. 长音频转写超时可配置 在 oddminutes_config.py 中新增 ODDASR_TIMEOUT 配置项,默认 600 秒(10 分钟),可通过环境变量灵活调整,解决长音频转写超时导致的失败问题。 二、体验优化 1. 转录交互全面升级 2. 音频文件路径统一 录音和导入音频的保存路径统一为 […]
版本信息 更新说明 现有机制下,所有启用的模型都会在 OddASR 启动的时候检测模型是否已下载,若未下载会自动开始下载,而部分模型(如:SenseVoice ONNX)在国内下载不稳定,普通的环境经常下载失败,导致普通的、不会github上网的非技术人员在使用 OddASR 的时候体验不佳。 上周用 OddASR 做了一个录音转写的产品:小奥录音,考虑到产品的用户群主要是普通用户,因此,决定默认禁用一些下载不稳定的模型。 但是 OddASR 的所有模型的功能都还是完整的,知道如何稳定下载各模型的技术人员可以自行修改配置文件,将相应的模型启用起来即可。 详细功能修改 版本特性 2-Pass ASR 架构 OddASR 2.x 采用 2-Pass ASR 策略,结合流式识别和离线识别: 核心特性 快速开始 安装 服务启动后: 无需 config.json 配置文件,服务使用内置 DEFAULT_CONFIG 启动。如需自定义,创建 config.json 覆盖需要修改的项即可。切换模型时若配置文件不存在会自动创建。 Python 客户端 OddAsr支持OpenAI兼容接口,推荐使用OpenAI的API接口来调用。 版本历史 v2.x (当前) 系统要求 常见问题 首次运行需要下载模型吗? 是的,首次运行需要下载 ASR 模型。可以通过设置 HuggingFace 镜像加速: […]
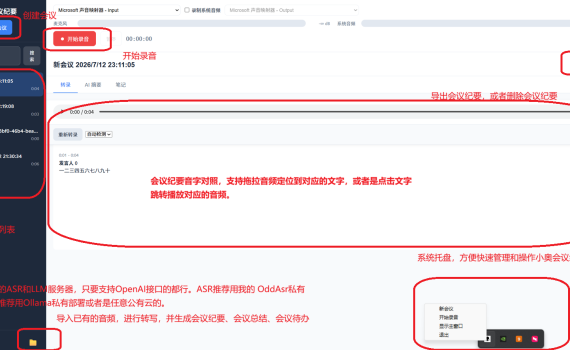
一、前言 前天公司的一位大佬在内部一个大佬群里发了一个某鱼的智能录音卡产品,据宣称该产品某鱼只花了一个星期就做出来了。个人感觉有点不可思议。 再加上前两天原本一直免费的豆包“音频纪要”功能开始收费了,Lucy同学说想自己用opencode做一个音频纪要的功能来接替上去。 我听了后就开始有点手痒痒了,趁这个周末超级台风“巴威”要来,看看能不能在家里vibe coding一下试试。 经过一个周末的努力,我也不知道烧了多少token,反正周六、周日两天我的几个coding plan都提示我上限了。不过感觉基础功能已经差不多了,先放一个版本到 github。 开源的智能会议纪要系统,支持实时录音、AI 转录、智能摘要生成和音字联动功能,基本上我能想到的一些功能都已经支持了。 而且也支持全私有化部署,确保所有数据都只能您自己的电脑上,保护您的隐私。 虽然豆包的音频纪要功能仍然免费可用,但OddMinutes 小奥会议纪要是专门做会议纪要的,可以做到比豆包更专业,可用性、安全性、隐私等方面更强。 当然如果您有一些其他的功能需求、功能建议的话,也欢迎给我提出来,我看看是不是可以加进去。 二、使用步骤 主要有三个外部依赖:ffmpeg: 用于将录制下来的音频、或者是导入的音频转换成mp3格式ASR服务:用于将音频转换成文字LLM服务:用于将会议纪录生成会议纪要、会议总结和会议待办其中ASR服务和LLM服务,对应到小奥会议纪要 Web 界面左下角的配置里的两个配置项。全都支持私有化本地部署。 三、功能特性 四、快速安装 首次运行时,程序会自动初始化数据库并创建用户数据目录。 Windows下会在桌面自动创建两个快捷方式,具体如下图所示: 五、外部服务依赖 主要是两个依赖:一个是ASR服务,另一个是LLM服务。对应到小奥会议纪要 Web 界面左下角的配置里的两个配置项。全都支持私有化本地部署。 1. OddASR 语音识别服务 必需 – 用于音频转录,提供 OpenAI 兼容的 /v1/audio/transcriptions 接口。 安装 OddASR 服务 运行 OddASR 服务 在小奥会议纪要的Web界面左下角配置 OddAsr的地址 2. Ollama / LLM 服务 […]
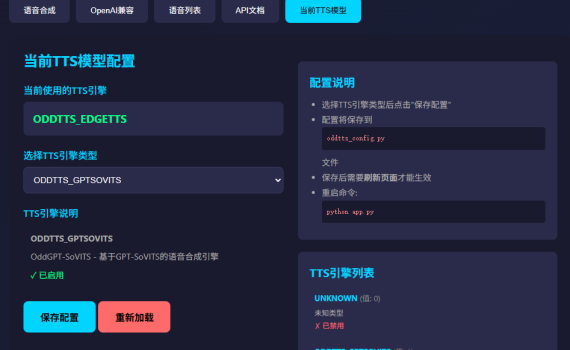
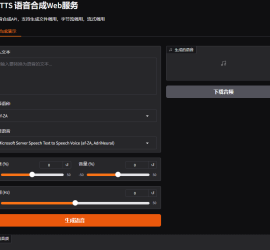
一、项目背景 OddTTS:一个统一多引擎的 TTS 语音合成 API 封装工具,现已支持 OpenAI TTS API 兼容 OddTTS 诞生于作者的一个实际需求——为项目 「小落同学」 提供文字转语音能力。由于受限于99元/年的阿里云ECS服务器硬件条件,最初只能使用 EdgeTTS,但作者本人的电脑配置尚可(十年前买的老笔记本,呵呵),尝试了多种 TTS 引擎后,决定为这些模型创建一个统一的封装层。 于是,OddTTS 应运而生——一个强大的多引擎文本转语音服务,提供统一的 API 接口和友好的 Web 界面,让你用一套接口就能对接多个主流 TTS 引擎。 二、核心功能 支持多种 TTS 引擎: 我自己目前使用的主要是:EdgeTTS和Kokoro-82M-v1.1-zh这两个模型,分别用在阿里云ECS和我自己的十年前老笔记本上。 注:市面上还有许多其他的轻量级的TTS模型,但是由于我自己的使用场景里,主要的语言是中文,所以我选择的都是必须要支持中文的轻量级模型,不支持的一概忽略。 多种调用方式: 在OddTTS自带的Demo的web上都有演示。 好用的 Web 界面: 基于 Flask 构建的可视化操作界面,支持文本输入、语音选择、参数调节、音频生成与下载,开箱即用。 三、近期更新亮点 API 请求耗时日志 — 现在每个 API 请求都会打印时耗日志,启动时也会显示当前运行的 TTS 引擎名称,方便监控和调试。 模型下载异常修复 — […]
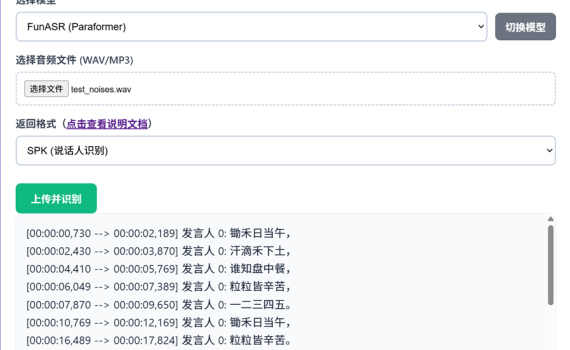
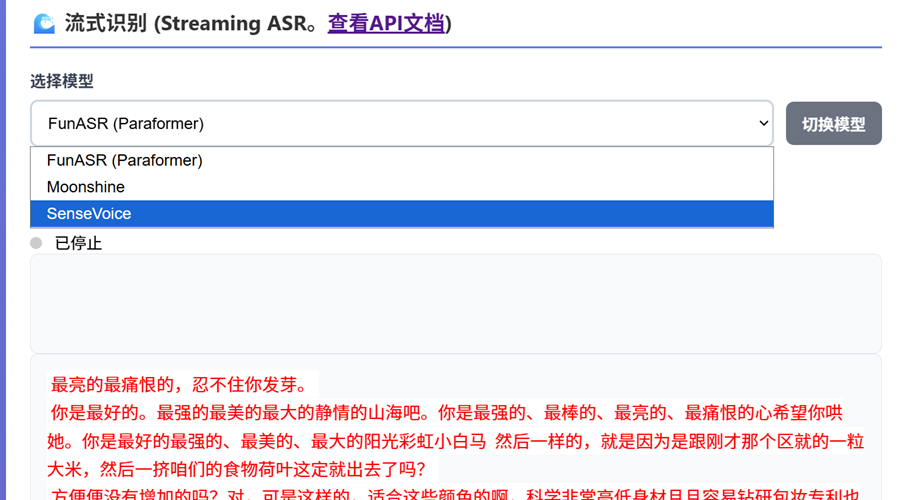
引言 前阵子发现,我五一假期几天搞的小落同学新版本的文章《可用十年前老笔记本纯CPU跑的全套虚拟人方案》被微信判定为违规,一下子打消了我写公众号的积极性,所以这段时间都不太想写公众号。 OddASR 是一个兼容 OpenAI API 的自动语音识别(ASR)服务器,支持离线转录和流式转录。让语音转写更简单。 距离上次发版又过去了几个月,OddASR 陆陆续续发布了一些重要更新。无论是端侧纯 CPU 运行的突破、多音频格式的全面支持,还是前端自由切换模型的灵活体验,每一次更新都为了让语音转写变得更简单、更强大。 昨天,大佬大白菜 反馈了一些问题,我当时在上班没有时间处理,结果他自己直接帮我修复了。 今天我在家也顺便把他帮忙改的代码也合到了主分支,然后顺便也发布了一个新的版本 2.4.6,这里就盘点一下 OddASR 近期的一些更新,顺手把文档也更新了一下(今年一直在忙公司那边的一个智能运维的项目,每天跟产品、测试、需求纠缠不清,包括OddASR、小落同学等项目也都一直没时间搞,更别说是一些文档了)。 一、SenseVoice ONNX 版:端侧 CPU 也能飞 最大的更新莫过于SenseVoice ONNX 版本 的加入,这主要是应对小落同学要在我那个十年前的老笔记本上跑的需求。 借助 sherpa-onnx 框架,SenseVoice 现在可以在纯 CPU 环境下流畅运行,无需 GPU 也能获得出色的识别效果。这对于没有独立显卡的服务器、笔记本乃至边缘设备来说,无疑是个巨大的福音。 功能对应「小落同学」的新版本,特别感谢 大蟑螂 和 大白菜 两位大佬的贡献支持和建议!” SenseVoice 同时支持离线转写和模拟流式输出(基于内置 VAD),成为继 Paraformer、Moonshine 之后的第三大后端引擎。 个人推荐:FunASR > SenseVoice > Moonshine […]

首先,这篇7.5万字的文章我读了三遍(昨天下午第一遍看,第二遍是今天上班在地铁上听的,然后今天下班回家后又看了一遍)。 我认为的金句 看完后最大的感想是作者的复盘写的的确很深入,个人认为最大的一句金句就是:“产品最大的浪费不是偷懒,是全力以赴地做错事”。 必须要强调的是她这句话,我无比的认同,虽然后面可能会有一些但是,凡事总归需要个但是。 先说一下我自己 我自己也有一个经常性、阶段性复盘的习惯,但是我的复盘没有听众,只有我自己(只留在我自己的知识库,没有给任何人看过),唯二例外的是去年的两次复盘,一次是关于公司产品效率的吐槽,另一次则是入职十二年的一个总结,但也只发给过我的直属领导一个人。 无招要求的是一天一包,是敏捷到了极致。我们公司相比于阿里是一个小公司,我吐槽的都只是组织架构、决策路径上问题,是毫无敏捷可言的问题,我们的问题是过于臃肿,由于分工细,一旦牵涉多个部门、团队,基本上啥事都动不了。 我个人性子比较急,如果事情推不动我会很焦虑,今天要做的事情,如果明天还没做好,我会饭不香睡不着。多年来一直在用我自己的方式去处理:一个需要我做但会涉及其他团队的功能,如果别的团队忙,没时间来做,那就我自己来做。 在早些年公司的一些大功能迭代的时候都是这么一个路子(比如:早些年公司第一代的量子加密会议、32位转64位、IPv4转IPv6等等),更有甚之的则是几年前的公司第一代智能产品。 我的态度一言概之就是:你们都很忙,那好,全部我自己来搞定。纯粹一介草蛮。 可能当时我也压迫的下面的兄弟们,但是自认为我向下管理还是可以的(向上管理则是完全相反),因为所有离开了的兄弟们跟我都还一直有联系,哪怕只是过年过节问候一下。” 写本文的目的 最后,这篇文章的主要目的不是想继续我自己的吐槽,是为了给大家推荐阅读一下《置身钉内》,一篇直接让CEO下台的小作文,让一个极具战斗力的、能破局的人黯然出局的小作文。 个人观点 但是,当看到网上的人几乎全是骂无招的,甚至还传闻钉钉一堆人放烟花的时候,个人感觉都有点过了。 个人观点1:关于作者 个人感觉作者的叙事方式也是存在一些问题的(个人观点哈,不喜可喷)。 因为我相信这个ONE项目可能会存在的问题,在项目初期必然是考虑过后面可能会出现的各种场景: 我一个普通牛马都能想到的一些简单推演,像阿里、钉钉这种大厂在做一个大项目的时候,决无可能在项目初期没有考虑过这些可能的场景。 但是该文的作者在这篇小作文里的叙事感觉就完全是以爽文的方式来演进,一开始抬高大家对ONE项目的预期,后面完全反转,并且把无数打工人抵抗的996、内卷、加班文化将这个项目的成败放在一起,自然就一下子让绝大多数人爽了。 所以,幽素同学的文采不得不西服,与此同时,一点感想,千万不要得罪文科生(据说哈,我也不知道她是不是文科生)。 个人观点2:关于无招 你可以不认同他的行事方式,你可以对这个产品的结果吐口水,但是你不能不认同他想做事、想做成事的信心、决心和勇气,并可以为之全力以赴的行动力、执行力。” 但是经过这一摊子沸沸扬扬的事,无招同学后面可能无法再像上一次离开钉钉再回到钉钉那样,可以轻松的东山再起了,无论是继续在阿里体系(估计以他的个性已经不可能了),还是再起第二个HHO。当然,像无招这样的、早已财务自由的大佬的事,也不是我一个牛马需要操心和担心的。 个人观点3:关于选择 一切都只在于你的抉择,选择东就会牺牲西,选择西就会牺牲东,选择付费方(老板们)必然会让使用者(打工人)厌恶,选择一家996的公司也必然会让生活上的时间被压缩。 个人观点4:客户第一,还是老板第一? 有阿里的同学说阿里的文化之一是:老板第一(与之相对应的是客户第一),有人说想笑,有什么好笑的呢?在军团作战的时代,尤其是在这个快速变化、叠加信息不对称的AI时代,老板的决策就代表了整体的作战目标,如果你有不同的看法,可以表达你的看法和意见,但是如果你的想法不能影响老板的决策,那就是老板第一,这也是普通人要想在这个时代杀出血路的不二方案。 更何况,从ONE这个产品的定位来说,实际上一个真正意义上的、变革的产品,因为它改变的是整个范式:让“人找事”,变成“事找人”。
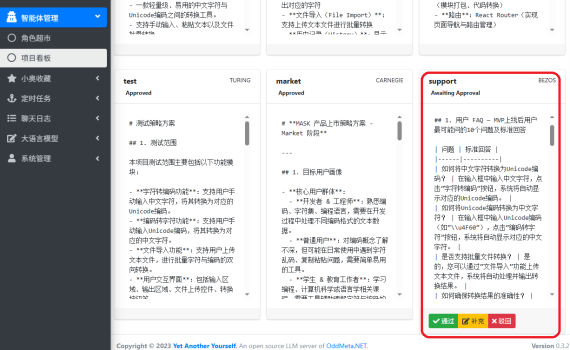
## 一、前言 前两天在哪个新闻上看到有人做了一个OPC,然后招了一些名人来帮他打工,挺美的,那篇文章一下子找不到了。 这个周末在家,我也给我的[小落同学](https://www.oddmeta.net/project-xl “小落同学”)招了几个员工,分别是 Musk, Jobs, Linus, Turing, Carnegie, Zezos,分别负责和担任小落同学的CEO,UCX,Developer, Test, Marketing, Support。 今天找了半天,想找之前看到的文章,并借鉴一下他的具体方案,但死活就是没找到,于是就先自己硬着头毛先实现一个版本试试。 这个月没有买token plan,然后前两天白嫖的小米MiMo大模型的token也过期了,所以我又回到了open code。 实现后,我让这些员工一起协同给小落同学设计了一个 `中文字符unicode转换的工具`,并跑通了整个流程。下面是整个流程全记录。 ## 二、思路及Spec探索 一些客套、扯蛋、吹牛的废话就省略了,直接上整个流程。 ### 1、思路探索 在opencode里打开小落同学的代码目录,输入提示词 #### INPUT:提出我的计划 “`bash 我在小落同学数据库中新增了几个角色,Musk, Jobs, Linus, Turing, Carnegie, Bezos等,希望让他们成为生产力工具,我跟Musk交待任务(MVP产品开发任务),然后Musk让Jobs设计,Linus开发, Turing测试, Carnegie市场销售推广,Bezos技术支持。 在现有的代码基础上设计一套agent框架流程,来实现这些角色的串联。 “` #### OUTPUT: 协作方式 “`bash 从项目探索来看,当前架构是单角色单轮对话模式,还没有任何多Agent编排能力。 我的第一个问题是理解交互流程: 你希望的协作方式是哪种? A. 全自动编排 — 你给Musk下达任务后,Musk自动拆解、依次分派给Jobs→Linus→Turing→Carnegie→Bezos,每个Agent的输出自动传递给下一个,最终返回完整结果给你 […]
## 一、前言 之前聊了三篇了。Embedding 搜索、Reranker 精排、向量索引加速。文本侧的 RAG 管线基本捋顺了。但有读者问了一个现阶段我还没法回答的问题:**小落同学能不能听懂人话?** 不是 NLP 层面的”理解”,是物理意义上的。你对着手机说一句话,它翻译成另一种语言,再读出来。实时的那种。 小落同学目前跑在一台十年前的笔记本和一台 99 块的 ECS 上,2GB 内存,纯 CPU。这个硬件跑 Whisper 语音识别?想都不用想。但手机就不一样了——现在的 Android 手机,哪怕是个中端机,也塞了 8GB 内存和一堆 NPU/DSP 加速单元。 RTranslator 就是干这个的。开源的,离线的,实时的,一个 Android 翻译 App。翻译用 Meta 的 NLLB,语音识别用 OpenAI 的 Whisper。全在手机上跑,不联网,没服务器。 RTranslator 在 GitHub 上 10k+ stars 了,v2.1.5 已经发了,v3.0 还在搞。这篇就是想看看它能不能帮小落同学实现同声传译——能不能把手机变成小落同学的耳朵和嘴巴。 ## 二、方案介绍 先把概念拉出来: | 概念 […]