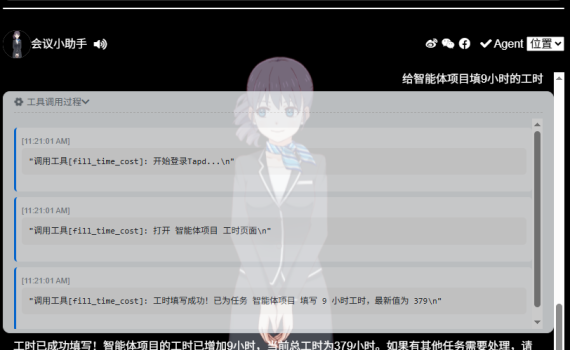
一、前言 前前后后的给小落同学加了许多的MCP。 但是这些功能之前一直在我本地的小落同学上跑,部署在阿里云ECS上的小落同学因为买的ECS配置太低(99元一年的2H2G特惠主机)跑不动,这个周末在家没事做,想想是不是干脆用frp让公网上的小落同学也可以把这些MCP也都给支持起来。 所以这个周末的任务就是:把原先一直在我本地电脑上跑的小落同学的MCP Server部署到公网,并让阿里云上的小落同学来访问和使用。 目前小落同学支持的MCP包括: 既然想了,那不管有没有人用小落同学,咱先给它配上去再说。 二、MCP Server可配置化 1. 新增ODDMCP配置 在小落同学的.env环境变量里新增mcp相关环境变量配置 2. 同步调整MCP Server和MCP Client中与MCP相关的配置 把原先固定的localhost的地址,改成从环境变量中获取。 1)代码:oddmcp_server.py 2)代码:oddmcp_client.py 3)代码:oddmcp_status_callback.py 4)oddagent 同步的时候发现几个新的MCP Server功能还没同步到小落同学上的oddagent,也顺手改了一下。 三、利用frp来做跳转 ODDMCP用了两个端口,一个是MCP Server所绑定的9600端口,另一个是每个在MCP运行过程中的一些实时进展状态回调时所使用的redis。 1. 客户端配置 代码:frpc-https.toml 杀掉并重新启动 frpc 2. 服务端口配置 客户端修改并新增了这两个端口,并且重启了frpc之后,先到ECS服务器端查看一下,端口状态是否都正常。 如果都有正常绑定了,说明frp已经可以工作了。 需要注意的是:服务绑定地址应该是 0.0.0.0:9600,而不是 127.0.0.1:9600(后者只允许本地访问)。 四、阿里云ECS配置 配置好frp后,还需要让阿里云ECS放行这两个端口。 1. 修改ECS安全组配置 打开浏览器,登录阿里云控制台,进入安全组配置,并在其中新增、放行9600和63579这两个TCP的端口。 阿里云控制台上的功能比较多,不常用的话,可能要找地址找半天。由于忘记功能名字了,搜索也不好搜索,呵呵。 为方便记录,特把安全组的链接地址也贴一下:https://ecs.console.aliyun.com/securityGroup/region/cn-shanghai 2. 放行防火墙 打开xshell,ssh登录上ECS服务器,查看是否放行 9600/tcp 如果是centos/openEuler操作系统: […]
Utilities

一、前言 昨天用OpenCode Desktop做了下书签管理的SKILL,今天就想去看看这个“早就想去看看的”、“国内第一个支持SKILL”的扣子。 于是,今天我就把昨天在Open Code Desktop上做的事情原封不动的在扣子上做了一遍。下面的完整的过程。 具体的SKILL的原理什么的我就不讲了,网上随处可见,咱们来实操。 为省流,直接上结论: 总的来说,单纯对于我这个书签管理功能来说,生成的SKILL的确还可以,但是SKILL描述和references还是需要自己仔细分析一下改一下。 除此之外,简单列一下我个人的一点经历和看法 也为扣子加一把油,为国内的开发者搭建了一个更好的平台和环境。 二、在扣子上创建skill 1. 创建skill 进入扣子网站( www.coze.cn ),输入提示词如下: 快速出了一个版本,但是自测验证报错,但是扣子会自己修改代码重测。a little monments later(约二十来分钟),终于完成。 2. 上传skill 作为一个懒人,只想动嘴,不想动手,所以第一个尝试是让扣子直接把它写好的这个skill安装到扣子上。 1)自动安装:失败 但是,扣子实际上只是给了一个帮助文档,还是让我自己上传安装。 那好吧,那我先下载一下扣子生成的skill及代码。 2)手动安装:成功 下载下来后,到扣子技能商店:https://www.coze.cn/skills?tab=my 然后点击右上角的“创建技能”,把下载下来的这个zip文件上传,扣子就会自动按照标准流程帮你适配这个 Skill。 但是扣子会将原先的 MCP 服务器实现重写为纯函数式工具,这说明扣子不会在上面自己开一个MCP Server来让Skill调用。 3. 部署Skill 点击右上角的“部署”按钮,跳过变量设定,秒级完成部署。 三、Skill的使用 通过上面的步骤,我的扣子版的书签管理Skill就完成了,并且可以直接在扣子上使用了。使用方法也很简单,在聊天框里输入 @ ,然后在跳出来的选项框里选择技能,技能列表里会包括所有你安装的和创建的技能列表,在那里选择“书签管理技能”。 四、进一步完善 希望收藏下来的文章的可以按我的要求来命名文件,保存的路径,以及图片的路径,那就让它再来改一下吧。 最后,扣子再输出了一版SKILL,并简单测试了一下包括新浪新闻,今日头条,CSDN,博客园,知乎等网站的文章都可成功抓取。收工! 五、完整代码 考虑到未来SKILL无限的可能性,我准备再建一个仓库,然后把一些自己实现的SKILL都放到这个仓库里。今天的扣子版本的书签功能的SKILL是第一个。 仓库地址: https://github.com/oddmeta/odd-skills 感兴趣的大佬可以直接到这里下载完整的代码。也可私信我,我发你。

一、前言 上周四下午领导说公司的某个助手项目准备启用自研的备用方案,然后我的 OddAgent 项目就开始从备胎出现转机,有可能会成为正式方案了。 原先我没有为 OddAgent 设定开源授权方案,大家都可以继续在 OddAgent 现有的开源代码基础上自行演进,而公司的产品一旦正式使用了 OddAgent,那可能日后的一些功能实现就不方便放到我的github上了。 不过,以我自己在小落同学项目中一些实际功能的测试体验,现有的 OddAgent 已经足以应付各种个人/企业场景下的意图识别功能。 为了避免日后大家在授权问题上出现顾虑,我特别将 OddAgent 的授权从GPL改成了MIT。 二、关于新的开源协议MIT MIT协议允许你任意的使用、复制、修改原MIT代码库,随便你是选择跟我一样继续开源,还是选择闭源甚至商用,唯一需要遵循的原则就是在你的软件中声明你也使用的是MIT协议就行了。 MIT 协议 三、OddAgent的安装与使用 1. 安装 2. 配置 项目配置样例:https://oddmeta.net/tools/oddagent/config.json.sample智能体配置样例:https://oddmeta.net/tools/oddagent/conference_config.json 下载好后放在你前面创建的目录下。然后复制config.json.sample,并将其改名为config.json 然后开始调整设置 config.json 里配置你自己的系统配置 下面是一个系统配置的示例。 1)大模型配置 2)智能体功能配置 根据你自己的业务需求,配置你的功能意图和槽位的语料。OddAgent自带了一个视频会议场景的示例 conference_config.json ,可供您的参考。 具体的配置方法可参考这里:https://pypi.org/project/oddagent/ 3. 运行 启动命令:oddagent -c config.json 4. 测试后台 默认的测试后台地址是:http://localhost:5050 5. API接口 OddAgent只做意图、指令的识别,所以实际场景里基本上都是在你自己的产品里用API来调用OddAgent识别意图指令,然后自行去实现相应的功能。 以下是一个API调用OddAgent的完整示例代码: 运行测试代码:python […]

一、前言 为简化 OddAgent 的安装、使用流程,准备将OddAgent打成一个包,上传到pypi,这样后面只要pip install oddagent就可以直接安装使用了,方便大家利用OddAgent来实现自己的智能体。 不废话,直奔主题。 二、打包工具安装及配置 1. 安装打包和上传工具 打包和上传工具的安装,走强制升级更新模式。 2. 注册 PyPI 账号 如果你还没有注册PyPI,那就先去注册一下,注册地址: https://pypi.org/account/register/建议同时注册 TestPyPI 用于测试发布。PyPI和TestPyPI是两套独立的环境,账号系统也是独立的,所以需要分别注册,包括后面会提到的用于上传包的API token也需要分别申请。 3. 准备项目结构 一个典型的 Python 包结构如下: 4. 编写 pyproject.toml 5. 构建发行包 在项目根目录下运行: 6. 配置 .pypirc 登录 PyPI → Account Settings → API tokens创建一个 token(建议选择设置为全局token) 复制 token(只显示一次!你要自己保存好) .pypirc 是一个配置文件,用于存储Python包仓库的认证信息,通常位于用户主目录下: 内容如下: 三、发布及测试 打包好的包,建议先发布到 […]
一、缘起 想给小落同学加一些功能,但是小落同学买的是99元/年的阿里云ECS,配置很烂,基本上只能跑跑网页应用(还动不动内存不足,CPU超标)。 而我家里的电脑虽然是十年前的老电脑,至少有16G内存,比这个ECS强多了,因此想在这台电脑上部署一些服务,然后让这些服务通过ECS穿透到家里这台私网下的电脑,一方面让这台电脑可以继续发光发热,另一方面也可以再给小落同学加点功能特性。 二、缘倾FRP 晚上一个人在家没事,就去找了一下私网穿透的解决方案,Google出来一大堆,经筛选拟选用FRP来实现此需求。 FRP 是一个专注于内网穿透的高性能反向代理应用,支持 TCP、UDP、HTTP、HTTPS 等多种协议,可以将内网服务通过具有公网 IP 节点的中转暴露到公网。 FRP 项目地址:https://github.com/fatedier/frp 三、一些准备工作 小落同学所在的ECS安装的是Linux操作系统,而家里的电脑安装的则是Windows操作系统,因此需要将FRP服务端安装在Linux上,而FRP客户端则安装在Windows上。 1.配置ECS安全组 登录阿里云控制台,找到你的云服务器 ECS,并在该ECS的安全组里添加你需要放开的端口,暂定需要的端口区间为9000~9020。 2.配置ECS上的防火墙 需有公网 IP(阿里云ECS具备),开放所需端口。拟使用: 如果你用ufw 如果你用firewalld 3.下载FRP 程序 从 GitHub Releases 下载对应版本: SSH登陆上阿里云ECS,开始下载、安装、配置。 你可以直接在浏览器上下载,浏览器上输入下面这个地址即可。也可以命令行里用wget来下载。 注:如果你的windows没安装wget的话,可以到这里下载 https://eternallybored.org/misc/wget/ 将下载的 Windows 版本压缩包解压到任意目录(如e:\tools\utility\frp),目录中包含frpc.exe(客户端程序)和frpc.ini(配置文件)。 四、【成功】测试http配置 1.配置http 1)服务端配置 修改frps.toml如下: 2)客户端配置 修改frpc.toml如下: 2. 测试http模式 1)启动服务端 2)验证服务端控制台 访问 http://47.116.14.194:9020 输入面板用户名密码,能看到界面即启动成功。 3)启动客户端 […]

Forwarded from: https://howdoesinternetwork.com/2016/quantum-key-distribution ——————————- QKD – Quantum key distribution is the magic part of quantum cryptography. Every other part of this new cryptography mechanism remains the same as in standard cryptography techniques currently used. By using quantum particles which behave under rules of quantum mechanics, keys can be generated and distributed to […]
I like this words: “There’s never a perfect time for anything—you just have go for it and keep your eyes on your goal.” Written by Anne Kreamer August 25, 2015 In the US, where only 11% of working engineers are women and fewer than 5% of the CEOs of the […]
This post’s goal is to guide a starter to analysis a crash by reading into the assemble code. But the example listed here is not a good one, because the crash point is not an obvious one, the real reason of the crash for this example is still remain uncovered. […]
Encountered an issue of extreme long time compiling days ago, so we tried to add a time cost output in the Makefile to locate what on earth happened during the compilation. There are two Makefiles need to be modified, one is Linux based Makefile, another is Android based Makefile Linux […]
The mechanism is simple like this: 1. Pull/Clone your own repository(which was forked from another repository) to a local PC. 2. Add remote source repository to a tag of the local copy. 3. Do local merge for the two repositories. 4. Resolve the conflications if exists. 5. Commit the local […]