
会议室数字孪生:低成本方案探索 最近参加会议时,大佬们聊到了会议室空间智能和数字孪生的方向,让我想起了以前做「小落同学」时研究过的VR看房伪3D技术。周末在家翻出旧代码,搭了个基础框架。 🎯 先看效果 没有专业全景相机,从网上找了两张实景图,用 Gemini 生成了两张效果图,写了个 demo。 核心展示维度: UI是随手搭的,重点看技术可行性~ 实拍图: 会议室1:来自百度图片,侵删 会议室2:来自百度图片,侵删 AI生成图: 会议室3:用 Gemini 生成的图片 会议室4:用 Gemini 生成的图片 🏗️ 两种方案对比 传统方案(高大上但贵) 看完这个周末的成果后,我们再来分析一下,一个常规的数字孪生平台的总体架构应该是什么样子的。 传统方案需要激光雷达、深度相机等专业设备,生成高精度点云模型,再进行纹理映射和材质渲染。效果最佳,但实施成本高、开通流程复杂。 简化方案(轻量级) 参考VR看房思路,用普通全景相机拍摄,拼接成2:1全景图,用three.js,pano2vr或者 CSS3D 渲染成静态3D模型。 🚀 开通流程(设想) 总耗时:约1~1.5小时 对接内容:预约情况、实时状态、历史统计 💡 技术选型思路 方案以最低硬件要求为出发点(最初想在老笔记本上跑),高硬件需求的方案都被我忽视了。目前只是技术可行性验证,后续看领导安排,希望能给有类似需求的小伙伴提供参考~
ProjectXL
26 posts
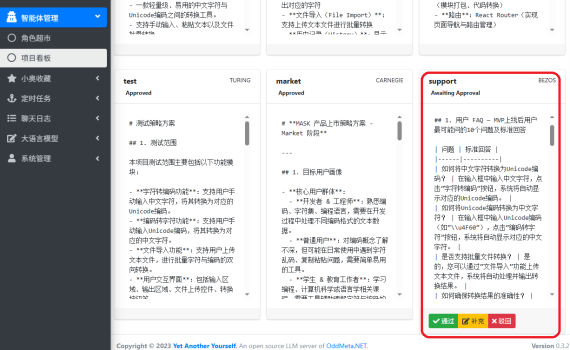
## 一、前言 前两天在哪个新闻上看到有人做了一个OPC,然后招了一些名人来帮他打工,挺美的,那篇文章一下子找不到了。 这个周末在家,我也给我的[小落同学](https://www.oddmeta.net/project-xl “小落同学”)招了几个员工,分别是 Musk, Jobs, Linus, Turing, Carnegie, Zezos,分别负责和担任小落同学的CEO,UCX,Developer, Test, Marketing, Support。 今天找了半天,想找之前看到的文章,并借鉴一下他的具体方案,但死活就是没找到,于是就先自己硬着头毛先实现一个版本试试。 这个月没有买token plan,然后前两天白嫖的小米MiMo大模型的token也过期了,所以我又回到了open code。 实现后,我让这些员工一起协同给小落同学设计了一个 `中文字符unicode转换的工具`,并跑通了整个流程。下面是整个流程全记录。 ## 二、思路及Spec探索 一些客套、扯蛋、吹牛的废话就省略了,直接上整个流程。 ### 1、思路探索 在opencode里打开小落同学的代码目录,输入提示词 #### INPUT:提出我的计划 “`bash 我在小落同学数据库中新增了几个角色,Musk, Jobs, Linus, Turing, Carnegie, Bezos等,希望让他们成为生产力工具,我跟Musk交待任务(MVP产品开发任务),然后Musk让Jobs设计,Linus开发, Turing测试, Carnegie市场销售推广,Bezos技术支持。 在现有的代码基础上设计一套agent框架流程,来实现这些角色的串联。 “` #### OUTPUT: 协作方式 “`bash 从项目探索来看,当前架构是单角色单轮对话模式,还没有任何多Agent编排能力。 我的第一个问题是理解交互流程: 你希望的协作方式是哪种? A. 全自动编排 — 你给Musk下达任务后,Musk自动拆解、依次分派给Jobs→Linus→Turing→Carnegie→Bezos,每个Agent的输出自动传递给下一个,最终返回完整结果给你 […]
## 一、前言 之前聊了三篇了。Embedding 搜索、Reranker 精排、向量索引加速。文本侧的 RAG 管线基本捋顺了。但有读者问了一个现阶段我还没法回答的问题:**小落同学能不能听懂人话?** 不是 NLP 层面的”理解”,是物理意义上的。你对着手机说一句话,它翻译成另一种语言,再读出来。实时的那种。 小落同学目前跑在一台十年前的笔记本和一台 99 块的 ECS 上,2GB 内存,纯 CPU。这个硬件跑 Whisper 语音识别?想都不用想。但手机就不一样了——现在的 Android 手机,哪怕是个中端机,也塞了 8GB 内存和一堆 NPU/DSP 加速单元。 RTranslator 就是干这个的。开源的,离线的,实时的,一个 Android 翻译 App。翻译用 Meta 的 NLLB,语音识别用 OpenAI 的 Whisper。全在手机上跑,不联网,没服务器。 RTranslator 在 GitHub 上 10k+ stars 了,v2.1.5 已经发了,v3.0 还在搞。这篇就是想看看它能不能帮小落同学实现同声传译——能不能把手机变成小落同学的耳朵和嘴巴。 ## 二、方案介绍 先把概念拉出来: | 概念 […]
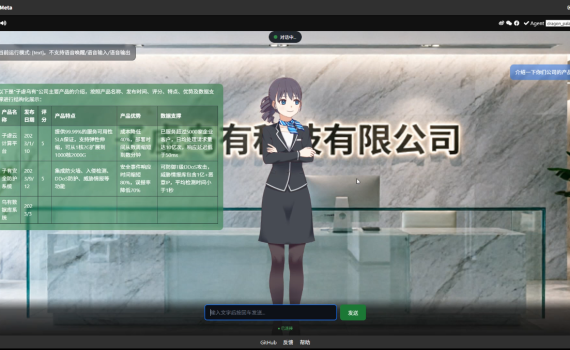
一、前言 半个多月前,计划着给我的小落同学做个改版,当时的目标是在一张消费级3060的GPU上跑全套虚拟人ASR+TTS+3DAvatar。 当时是计划着搞一台电脑,再去买一张3060的GPU,然后在上面跑全套的KWS+ASR+TTS+3DAvatar,但是后来想想现在去买3060实在有点过时,而如果要买新的50系列的卡呢又实在太贵,犹豫了几天后啥也没买,然后五一假期就到了。 于是,没办法,我只能继续在我这台10年前的老笔记本上折腾。于是,整个五一我就门也没出,一个人在家折腾这个东西了。于是,经过几天的折腾,现在终于有一个基础版本了。 市面上各种虚拟人方案多如牛毛,但是基本上清一色都需要GPU,咱买不起带GPU的电脑,所以自己手搓了这么一个方案。 简单汇总一下小落同学的优点如下: 百度网盘下载地址:https://pan.baidu.com/s/1y7ifkopK5ZesSgPUqxTY5A?pwd=vifz 提取码: vifz 二、先看效果 不废话,先直接看效果。简单录了两个视频, 一个是纯文本交互模式的, 另一个是全语音交互模式。 1. 在99元/年的2H2G阿里云ECS上跑产品知识问答(文本交互) https://www.bilibili.com/video/BV1htRvBWEfM 2. 十年前老笔记本(无GPU)上可跑全套语音交互,稍卡 https://www.bilibili.com/video/BV1xfReBVEQr 三、下载安装 1. 从github代码仓库下载 仓库地址:https://github.com/oddmeta/yay 克隆代码 安装依赖 运行服务 2. Windows绿色免安装包 无需安装python环境,无法安装依赖包/下载安装模型等繁杂的操作,解压缩后即可直接运行,使用的是硅基流动的免费API。私信:MetaYAY,即可获取。 四、进阶玩法 1. 完全本地运行(可断网运行) 若要完全本地运行,需自行下载ollama,并下载模型,然后修改根目录下的环境变量配置文件.env,将模型切换为本地的ollama,然后关闭运行中的metayay,再双击start.bat重新运行。 自行搜索教程。 根据你自己的硬件配置,下载不同尺寸的模型,具体什么模型适合你的硬件,可以把自己的硬件输入进去,问一下千问、豆包、Deepseek。 打开.env文件,将下面的三个变量设置成下面这样: LLM模型: Embedding模型: 注:若有多个设置,最终实际生效的是最下面的一个。 若已有启动YAY,先关闭,然后再双击 start.bat 重新启动。 浏览器打开:http://localhost:8000 ,测试验证。 2. 更新你自己的知识库 1)偷懒的办法 直接修改现有角色的知识库。 (1) 修改角色信息 […]

前言 我从去年开始就一直在零零碎碎的自己搞一个小落同学的项目,我的目标是: 给自己做一个专属的虚拟人,把 TA 当作我自己的树洞。每天或者隔一段时间,把想说的话、想吐槽的事都告诉 TA。等哪天想咨询点什么事的时候,去问 TA,看看 TA 记住的东西多了之后,会不会比我自己还了解我。 然后今天看到一个Pika的项目,于是就去研究、学习了一下。 一、它是什么? 当大多数 AI 厂商还在忙着卷工具的时候,Pika 突然发了条推:算了,不卷了,我们来”造人”。 2026 年 2 月,Pika 出了个叫 AI Selves 的产品。官方说法是:一个由你”孕育,培养并放手”的 AI 分身,成为你的一个活生生的延伸。 说人话就是:不是那种只会答题的聊天机器人,而是一个有记忆、会学你说话风格、能同时在好几个平台帮你跑业务的数字分身。 消息一出,科技媒体全在转。腾讯、网易、搜狐的标题都差不多——”不卷视频卷造人”。国外更热闹,评价两极分化,有人说是 AI 的下一个未来,也有人直接管这叫”AI 奴隶制”。 我看到的时候愣了一秒:这不就是我正在搞的”小落同学”吗? 今天来扒一扒这东西,顺便对比一下我的项目。 二、怎么用? 第一步:加入候补 现在还没全量开放,得先去官网排队: 官网入口:https://pika.me 支持 Google 账号和邮箱登录。邮箱注册可能要收个验证码,也可能直接进候补名单等通知。 第二步:设置你的分身 点 “Birth Your AI Self” 开始创建。 这一步决定你的分身有多像你: 官方原话:”一切由你决定。” 第三步:定外观 三个选项: […]

七个配置文件:SOUL、USER、AGENTS、HEARTBEAT、IDENTITY、BOOTSTRAP、TOOLS,三种使用场景:个人助手、个人知识库、数字分身(跟我的小落同学一样,复刻一个数字版本的你自己),加上 MEMORY 让你的 OpenClaw 从「傻白甜」变成「专属智能体」 很多人装了 OpenClaw,也接了飞书/Telegram,却总觉得它还是个”有记忆的 ChatGPT”——每次对话像在和陌生人聊天。 其实决定 AI 智商的,不是插件有多少,而是藏在 ~/.openclaw/workspace/ 目录下的 7 个 Markdown 文件。 这篇文章带你从零搞懂这套配置体系,并用个人助手、个人知识库、数字分身三个场景,手把手教你配置。 一、前言 OpenClaw 是 2026 年最火的开源 AI Agent 框架之一,GitHub 星标突破 25 万。它的核心理念是:AI 不应该是云端的黑盒,而应该跑在你自己的机器上,接入你日常使用的工具。 但问题来了——装好 OpenClaw 之后,很多人发现它和其他聊天机器人没什么区别。问什么答什么,没有主动性,不了解你的偏好,甚至每次对话都像失忆了一样。 原因很简单:你没有给它注入”灵魂”。 OpenClaw 的灵魂,藏在工作区目录下的 7 个 Markdown 文件里。搞懂它们,你的 AI 就能从”通用工具”进化成”专属搭档”。 二、方案介绍:7 个文件各管什么 OpenClaw 的工作区默认位于 ~/.openclaw/workspace/,所有配置都是纯 Markdown 文件,不需要懂代码就能编辑。 核心文件一览 文件 回答的问题 类比 […]

想不想拥有一个完全属于你自己的”小爱同学”或”小艺”?今天我来教你用开源项目 OddAgent,从零开始搭建一套智能家居意图识别系统。 一、前言 清晨,你刚睁开眼,窗帘自动缓缓拉开,温暖的阳光洒进房间。你随口说一句”我起床了”,灯光从暗淡的夜灯模式切换到柔和的晨光,咖啡机已经启动——这不是科幻电影,而是智能家居正在实现的未来。 然而,当你想要DIY一套完全可控的智能家居系统时,往往面临两难:要么选择米家、HomeKit 等封闭生态,功能受限于平台;要么自研整个系统,从设备协议到AI对话,技术门槛高得离谱。 今天要介绍的 OddAgent 项目,为我们提供了一条中间路线——它专注于意图识别,你可以对接任意品牌的设备,只需专注于实现具体的业务逻辑。 二、方案介绍 2.1 什么是 OddAgent 概念 定义 OddAgent 一个通用的意图、指令识别框架,基于 LLM 实现自然语言理解 Intent(意图) 用户想要完成的操作,如”打开客厅灯” Slot(槽位) 意图中的关键参数,如房间”客厅”、设备”灯” Tool(工具) 实际执行操作的接口,如控制灯的 API 配图 1 展示 OddAgent 识别用户语音/文字指令的流程图 OddAgent 的核心能力可以用一句话概括:“只负责听懂你要什么,不负责具体怎么干。” 它把意图识别做到极致,把功能实现交给开发者。 2.2 核心特性 2.3 为什么选择 OddAgent 对比自研 NLU 系统: 维度 自研 NLU OddAgent 开发周期 3-6 个月 1 […]

序言 想象这样一个场景:你花了半小时向 AI 助手解释你的项目架构、编码偏好和团队规范,得到了一次满意的协作体验。第二天你带着新问题回来,它却一脸茫然——「请问您的项目使用什么技术栈?」 这不是科幻,这是无数 OpenClaw「养成」过程中最常见的阵痛。 这不是科幻,这是无数 OpenClaw 用户每天都在经历的现实。 「OpenClaw 又忘了!」——这是 GitHub Issue 区最常见的抱怨。就在今年 1 月,一位开发者在 Issue #5429 中诉说了自己的遭遇:他花 45 小时与 Agent 协作积累的配置、技能集成、任务优先级,在一次静默的压缩(compaction)操作后全部消失。原因很简单:OpenClaw 在上下文窗口满载时,会自动对历史对话进行摘要和压缩,而这个过程没有任何警告。 这不是孤例。另一位用户报告说,他正在处理一个重要的代码重构任务,当对话进行到第 72 分钟时,compaction 触发了无限循环,整个 Agent 被锁死了 72 分钟。再重启时,之前的工作成果荡然无存。 本文将带你从痛点出发,遍历官方与社区方案,最终选定 lily-memory 这套「本地化 + 混合搜索 + 零成本」的方案,手把手教你从零养成 OpenClaw 的持久记忆能力。 一、前言:问题本质——三层失效 要理解 OpenClaw 为什么会「失忆」,我们需要理解它的记忆架构。在实际使用中,记忆失效发生在三个层面: 失效层一:从未存储。这是最常见的情况。用户在与 Agent 对话时,会自然地给出一些重要信息:「我习惯用 Tab 缩进」「上次那个 […]
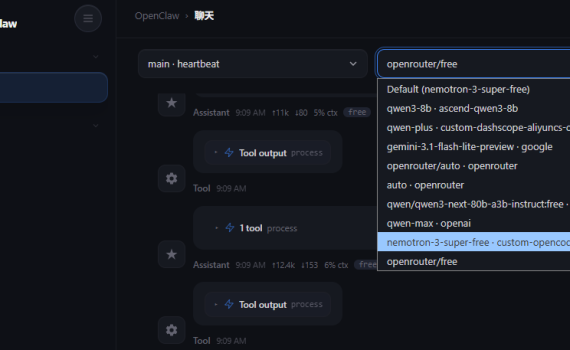
一、前言 养了三个星期的龙虾,由于可以在手机上就能指挥它干活,相比电脑上用ClaudeCode/OpenCode或者其它IDE带来了很大的便利,但是带来便利的同时就是这家伙的胃口太好,太吃token了。 前天3月18日,阿里云与百度智能云同一天宣布涨价。阿里云涨幅最高达34%;百度智能云则上调约5%—30%,并行文件存储等价格上调约30%。两家云厂商均将涨价归因于“全球AI需求爆发”。 腾讯云一周前已宣布上调两款自研模型Tencent HY2.0 Instruct和Tencent HY2.0 Think的价格,上涨463%。同时,腾讯云结束对GLM 5、MiniMax 2.5、Kimi 2.5 三款模型的免费公测,转为正式商用服务。 1、阿里云百炼 阿里云百炼 Coding plan套餐:https://bailian.console.aliyun.com/cn-beijing 前两天还有7.9元和39.9元的coding plan套餐,当时只是没抢到。 现在你再打开阿里云百炼的 Coding plan,会发现原先的7.9元和39.9元的两个套餐已经没有了,只剩下那个200元的套餐了。 2、百度云 百度千帆 Coding plan套餐:https://console.bce.baidu.com/qianfan/resource/subscribe 同阿里云百炼,40元的套餐已经买不到,只有200元的套餐还可以买。 二、寻找各种可白嫖的API Token方案 网上一搜免费API,你会发现:卧草,各种可以白嫖的API,什么Googe Gemini,OpenRouter, Nvidia的,但是我试了一下,在国内Gemini和Nvidia都无法使用,创建了API后,直接报401。 OpenRouter的可以用,但是额度太少,像我的小落同学的使用场景,三两下就把额度花完了。 最后找到OpenCode Zen的方案,目前是给小落同学还有我本机的OpenClaw给配置上去了。 三、如何白嫖OpenCode Zen的API token 步骤很简单:注册账号,复制自动创建的API Key,选择免费模型并测试,配置到你的OpenClaw。 1. 注册并登录OpenCode账号 登录你的OpenCode账号(如果还没有的话,那就注册一个),然后点击上面菜单项中的 Zen,或者直接打开链接:https://opencode.ai/zen ,Get Started With Zen, 进入你的workspace,这个时候opencode就已经给你自动创建了一个api key。如: 2. […]

前言:我想玩龙虾,但我不想掏钱 最近,OpenClaw 这个项目火遍了圈子,我也迫不及待地在自己的电脑上部署了一套,想让它成为我的 24 小时智能助理,也顺便想学习一下看看能给我的小落同学带来一些什么样的新思路。 然而,兴奋劲还没过,我就遇到了一个尴尬的现实问题:想要让它具备“联网搜索”能力,官方推荐的方案大多需要注册 API Key,要么有严格的免费额度限制,要么就得绑卡付费。 作为一个只想在本地跑跑实验、查查资料,既不想注册一堆账号,更不想每个月为几个搜索请求掏腰包的人,我觉得这很不爽。我的原则很简单:既然是本地部署的开源项目,那就应该尽可能地把控制权和数据隐私掌握在自己手里,而且——必须免费! 于是,我花了一个下午,调研了市面上所有的免费搜索方案,从阿里云百炼的免费额度,到 Tavily 的每月限额,再到 Google Serper 的试用陷阱。最终,我锁定并成功实施了一个完全免费、无需注册、纯本地运行的终极方案:DuckDuckGo + 自建 Python 脚本。 现在,我的 OpenClaw 已经可以帮我查新闻、搜论文、核实事实,而我不需要花一分钱,也不用担心配额用完。 这篇文档就是我整个折腾过程的复盘。如果你也像我一样,想用 OpenClaw 又想极致省钱,那么请跟随我的脚步,我们一起把这个“免费永动机”装上去。 1. 我的方案选型心路历程 在动手之前,我像做侦探一样对比了所有可能的路径。以下是我当时的思考过程: 方案 我的评价 为什么我没选它? A. 阿里云百炼/百度等大厂 API 稳定是稳定,但太麻烦。 我得注册账号、实名认证、创建应用、获取 Key。而且免费额度用完了怎么办?还要绑定支付宝?算了,太重了。 B. Tavily / Serper 等专用 API 专为 AI 设计,很好用。 每月只有几百次免费调用。对于我这种喜欢让 Agent 疯狂测试的人来说,两天就爆表了。还得时刻盯着配额,心累。 C. […]