
其实版本陆陆续续有递交到pypi,只是今天做一个阶段性的总结。当前版本号为v2.5.1,近期的一些修改主要对 OpenAI API 的兼容性做了一些增强,同时更新覆盖实时性、准确率、功能广度、工程稳定性四个维度。 最新版本 v2.5.1,已经上传到pypi,有需要的同学可以下载安装来体验一下。 安装:pip install oddasr运行:oddasr 一、实时转写:首字时延从 1.5~2s 砍到 ~0.5s 在 v2.5.1 更新中最值得关注的性能优化 同时新增配置项 streaming_buffer_chunk_size(默认 4800,即 300ms 缓冲),方便手动调优服务端缓冲策略。 为了方便查看和统计时延,本次还为转写流程中每一个重点功能都加上了时延统计,便于线上观测与回归对比。 二、新功能上线 1. 热词(Hotwords)支持 Paraformer / SenseVoice 后端现已支持热词功能,可在转写时注入业务专有词,显著提升专有名词、人名、术语的识别准确率。 服务端做了优化:只在热词实际发生变化时才记录日志(比较新旧值),避免高频音频传输路径上日志刷屏。 2. diarized_json 返回格式 在 OpenAI 兼容的 response_format 基础上,新增 diarized_json,返回带说话人角色的结构化结果,方便直接消费”谁在什么时候说了什么”。老接口里说话人角色分离的接口依然可用:response_format:spk。 3. 字词级时间戳(word-level timestamps) verbose_json 模式下支持 OpenAI 兼容的 word-level 时间戳请求参数,可控制返回文本是否带每个字的时间戳,并修复了音字对照时间戳错位、英文单词间空格导致解析异常等问题。 4. 多种音频格式 […]
FunASR
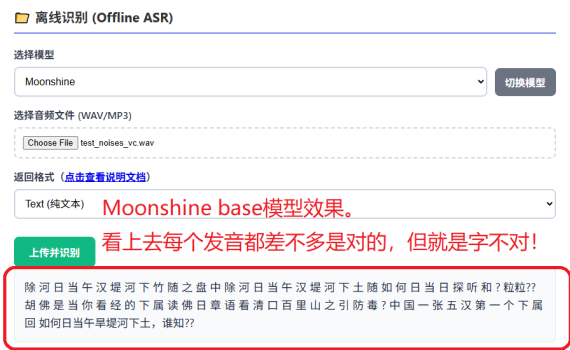
前两天研究了一下Moonshine Voice,当时拿了几个简单的音频文件测试了一下,感觉效果还可以,所以我就开始将其整合到了OddASR项目里。 但是在完成了整合后,再进行测试的时候发现一些比较严重的问题,所以,我又赶紧把我刚刚上传到pypi的OddASR给撤了,然后重新将主力模型改回到paraformer-zh-streaming和paraformer-zh。 当前OddAsr最新版本:v2.1.0,已恢复paraformer模型。 以下是在OddAsr自带的测试界面上分别跑paraformer-zh和moonshine base模型的效果 测试音频 具体的声音情况可以看这个视频: https://mp.weixin.qq.com/s/y4l-YtaUhayV9k9EDatCzw 注:这个视频中并未使用我的OddASR,效果差不是我OddAsr项目的锅。相反,下面我后来有将这个视频中的音频提取出来,专门作为OddAsr的一个测试集,每次测试不同的ASR模型的时候都会来测试一下这种场景。比如:这次的Moonshine base中文模型的测试。 测试效果 测试使用的音频就是上面那个视频里提取出来的音频。 paraformer模型效果 只想用一个字来形容:bravo! moonshine base模型效果 看上去转写出来的每个发音都是对的,但是。。。。这些个字呢。。。。好像就没几个是对的。 总结 唉,如果不是因为我这个用了超过十年的老笔记本CPU不太够用,我也完全不想去折腾一些其他的轻量级的ASR模型。
由于我在做的小落同学(https://x.oddmeta.net)项目需要用到ASR功能,之前针对 FunASR、FireRedAsr、Vosk等ASR项目也做了一些评测,但是总体跑下来发现还是FunASR的整体表现最好,所以我就将FunASR给封装了一下,做了一个OddAsr的项目。 而考虑到ASR功能的用途广泛,之前也有一些朋友私下问过我相关的一些使用和封装的问题,尤其是流式ASR的支持(github上有好多FunASR的API封装,但是全是离线文件转写的,没有一个同时支持离线文件转写和流式转写的API封装项目),想了一下干脆直接把它开源出来吧。希望对有ASR需求的同学有帮助。 项目地址: https://github.com/oddmeta/oddasr 之前关于ASR相关的一些测试 ASR引擎测试:FireRedASR只能说小红书的诚意不够,https://www.oddmeta.net/archives/144ASR引擎测试:FunASR,必须给阿里点一个赞,https://www.oddmeta.net/archives/165可能是最紧凑、最轻量级的ASR模型:Vosk实战解析,https://www.oddmeta.net/archives/201 项目简介 OddASR是一个简单的ASR API服务器,基于强大的开源语音识别库FunASR构建。FunASR由ModelScope开发,提供了丰富的预训练模型和工具,可用于各种语音识别任务。OddASR的目标是简化FunASR的部署,满足非实时音频处理的需求,同时也为实时流式转写提供了支持。 项目具有以下特点: 安装步骤 1. 克隆仓库 2. 安装依赖 使用方法 1. 启动REST API服务器 服务器将在http://127.0.0.1:12340上启动。 2. 测试文件ASR API 使用testAPI.py脚本测试API: 也可以使用curl命令发送音频文件到REST API: 3. 测试流ASR API 使用testStreamAPI.py脚本测试API: 4. 示例输出 5. Docker部署 项目待办事项 参考资料 如果你对语音识别技术感兴趣,不妨试试OddASR。它简单易用,功能强大,能为你的语音转文字工作带来极大的便利。快来体验吧!

前两天试了一下小红书开源出来的FireRedASR,整体感觉是小红书团队只是把关键的语音识别的模型开放出来了(也只开放了-L的模型),但是由于缺了一些前处理(语音VAD检测)、后处理(标点,多人语音聚类,热词等)相关的功能,普通用户拿到他们这个模型也根本没法直接拿来用,所以个人的观点是对于开源FireRedASR来说,小红书团队的诚意是不够的。 而光嘴巴说他们诚意不够是不能令人信服的,所以咱把阿里在2年多前开源出来的FunASR拿出来介绍一下,诚意够不够让大家自己体会。 一、FunASR介绍 FunASR是一个由阿里巴巴达摩院开发的开源语音识别工具包,旨在为学术研究和工业应用提供桥梁。它支持多种语音识别功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别。FunASR提供了便捷的脚本和教程,支持预训练模型的推理与微调,帮助用户快速构建高效的语音识别服务。 支持各种音视频格式输入,可以把几十个小时的长音频与视频识别成带标点的文字,支持上百路请求同时进行转写 支持中文、英文、日文、粤语和韩语等。 在线体验:https://www.funasr.com/ 注: FunASR是支持GPU推理加速的,不像阿云早先的一个私有云版本的ASR引擎那样,只用CPU来推理的。 二、FunAsr核心功能 1. 功能列表 2. 离线语音识别 拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。 3. 实时听写 FunASR实时语音听写软件包,集成了实时版本的语音端点检测模型、语音识别、语音识别、标点预测模型等。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。依据使用者场景不同,支持实时语音听写服务(online)、非实时一句话转写(offline)与实时与非实时一体化协同(2pass)3种服务模式。 三、安装部署 1. Requirements 2.创建虚拟环境 3. 安装 【必选】torch+torchaudio安装 我本次测试是直接用pip来安装的,省去docker相关安装、拉取的时间。其中需要注意的是如果你是一个全新的环境,没有torch, torchaudio的环境的话,需要先安装一下这两个。 如果是国内的话可以考虑加速一下 建议安装一下。不安装的话用torchaudio也能跑,但是ffmpeg更佳,毕竟是专业做这个的。没安装ffmpeg会有这个Notice: 4. 下载模型 常规的环境变量,指定huggingface和modelscope的cache路径,并为huggingface做个国内的加速。 5. 下载测试音频文件 在开始测试之前,你需要准备一些测试用的音频,可以直接用阿里云提供的先把功能跑通,然后再去用一些公开的测试集,或者是你自己的测试来测试FunASR的效果。 阿里云上的测试文件: 四、测试运行 在安装好FunASR,下载好模型,下载好测试文件后,可以开始跑正式的测试了。 1. ASR转写 从这个结果里可以看到,FunASR的标点、断句都做的非常好。音字对照的时间戳也都可以给你标出来了,基本上就是它所宣称的工业级别的了,有了这些基本上可以让你自行去扩展实现各种你需要的业务了。 2. VAD检测 对于语音转来说的,非常重要的一个前处理,尤其是针对文件转写来说,通常都需要先检测一下VAD,如果没有VAD,那么那一段时间的音频可以直接扔掉;另外,如果需要将大文件做切片的时候也需要根据VAD来做切片。哪怕转写出来文字后,要进行分段处理,那VAD的情况也是一个重要的参考指标。 3. 标点恢复 我相信没人想要一陀没有任何标点符号的文本吧。FunASR的ct-punc模型可以帮你处理标点符号的恢复。 4. 说话人验证 如果你想做一些说话人验证的产品和功能的时候,FunASR的这个speaker-verification模型可以直接拿来用。 […]