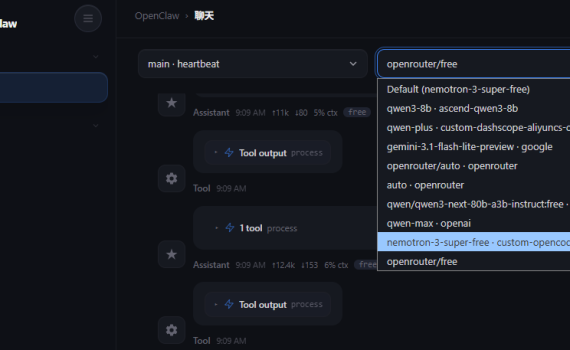
一、前言 养了三个星期的龙虾,由于可以在手机上就能指挥它干活,相比电脑上用ClaudeCode/OpenCode或者其它IDE带来了很大的便利,但是带来便利的同时就是这家伙的胃口太好,太吃token了。 前天3月18日,阿里云与百度智能云同一天宣布涨价。阿里云涨幅最高达34%;百度智能云则上调约5%—30%,并行文件存储等价格上调约30%。两家云厂商均将涨价归因于“全球AI需求爆发”。 腾讯云一周前已宣布上调两款自研模型Tencent HY2.0 Instruct和Tencent HY2.0 Think的价格,上涨463%。同时,腾讯云结束对GLM 5、MiniMax 2.5、Kimi 2.5 三款模型的免费公测,转为正式商用服务。 1、阿里云百炼 阿里云百炼 Coding plan套餐:https://bailian.console.aliyun.com/cn-beijing 前两天还有7.9元和39.9元的coding plan套餐,当时只是没抢到。 现在你再打开阿里云百炼的 Coding plan,会发现原先的7.9元和39.9元的两个套餐已经没有了,只剩下那个200元的套餐了。 2、百度云 百度千帆 Coding plan套餐:https://console.bce.baidu.com/qianfan/resource/subscribe 同阿里云百炼,40元的套餐已经买不到,只有200元的套餐还可以买。 二、寻找各种可白嫖的API Token方案 网上一搜免费API,你会发现:卧草,各种可以白嫖的API,什么Googe Gemini,OpenRouter, Nvidia的,但是我试了一下,在国内Gemini和Nvidia都无法使用,创建了API后,直接报401。 OpenRouter的可以用,但是额度太少,像我的小落同学的使用场景,三两下就把额度花完了。 最后找到OpenCode Zen的方案,目前是给小落同学还有我本机的OpenClaw给配置上去了。 三、如何白嫖OpenCode Zen的API token 步骤很简单:注册账号,复制自动创建的API Key,选择免费模型并测试,配置到你的OpenClaw。 1. 注册并登录OpenCode账号 登录你的OpenCode账号(如果还没有的话,那就注册一个),然后点击上面菜单项中的 Zen,或者直接打开链接:https://opencode.ai/zen ,Get Started With Zen, 进入你的workspace,这个时候opencode就已经给你自动创建了一个api key。如: 2. […]
LLM
一、前言 前前后后的给小落同学加了许多的MCP。 但是这些功能之前一直在我本地的小落同学上跑,部署在阿里云ECS上的小落同学因为买的ECS配置太低(99元一年的2H2G特惠主机)跑不动,这个周末在家没事做,想想是不是干脆用frp让公网上的小落同学也可以把这些MCP也都给支持起来。 所以这个周末的任务就是:把原先一直在我本地电脑上跑的小落同学的MCP Server部署到公网,并让阿里云上的小落同学来访问和使用。 目前小落同学支持的MCP包括: 既然想了,那不管有没有人用小落同学,咱先给它配上去再说。 二、MCP Server可配置化 1. 新增ODDMCP配置 在小落同学的.env环境变量里新增mcp相关环境变量配置 2. 同步调整MCP Server和MCP Client中与MCP相关的配置 把原先固定的localhost的地址,改成从环境变量中获取。 1)代码:oddmcp_server.py 2)代码:oddmcp_client.py 3)代码:oddmcp_status_callback.py 4)oddagent 同步的时候发现几个新的MCP Server功能还没同步到小落同学上的oddagent,也顺手改了一下。 三、利用frp来做跳转 ODDMCP用了两个端口,一个是MCP Server所绑定的9600端口,另一个是每个在MCP运行过程中的一些实时进展状态回调时所使用的redis。 1. 客户端配置 代码:frpc-https.toml 杀掉并重新启动 frpc 2. 服务端口配置 客户端修改并新增了这两个端口,并且重启了frpc之后,先到ECS服务器端查看一下,端口状态是否都正常。 如果都有正常绑定了,说明frp已经可以工作了。 需要注意的是:服务绑定地址应该是 0.0.0.0:9600,而不是 127.0.0.1:9600(后者只允许本地访问)。 四、阿里云ECS配置 配置好frp后,还需要让阿里云ECS放行这两个端口。 1. 修改ECS安全组配置 打开浏览器,登录阿里云控制台,进入安全组配置,并在其中新增、放行9600和63579这两个TCP的端口。 阿里云控制台上的功能比较多,不常用的话,可能要找地址找半天。由于忘记功能名字了,搜索也不好搜索,呵呵。 为方便记录,特把安全组的链接地址也贴一下:https://ecs.console.aliyun.com/securityGroup/region/cn-shanghai 2. 放行防火墙 打开xshell,ssh登录上ECS服务器,查看是否放行 9600/tcp 如果是centos/openEuler操作系统: […]

一、前言 昨天用OpenCode Desktop做了下书签管理的SKILL,今天就想去看看这个“早就想去看看的”、“国内第一个支持SKILL”的扣子。 于是,今天我就把昨天在Open Code Desktop上做的事情原封不动的在扣子上做了一遍。下面的完整的过程。 具体的SKILL的原理什么的我就不讲了,网上随处可见,咱们来实操。 为省流,直接上结论: 总的来说,单纯对于我这个书签管理功能来说,生成的SKILL的确还可以,但是SKILL描述和references还是需要自己仔细分析一下改一下。 除此之外,简单列一下我个人的一点经历和看法 也为扣子加一把油,为国内的开发者搭建了一个更好的平台和环境。 二、在扣子上创建skill 1. 创建skill 进入扣子网站( www.coze.cn ),输入提示词如下: 快速出了一个版本,但是自测验证报错,但是扣子会自己修改代码重测。a little monments later(约二十来分钟),终于完成。 2. 上传skill 作为一个懒人,只想动嘴,不想动手,所以第一个尝试是让扣子直接把它写好的这个skill安装到扣子上。 1)自动安装:失败 但是,扣子实际上只是给了一个帮助文档,还是让我自己上传安装。 那好吧,那我先下载一下扣子生成的skill及代码。 2)手动安装:成功 下载下来后,到扣子技能商店:https://www.coze.cn/skills?tab=my 然后点击右上角的“创建技能”,把下载下来的这个zip文件上传,扣子就会自动按照标准流程帮你适配这个 Skill。 但是扣子会将原先的 MCP 服务器实现重写为纯函数式工具,这说明扣子不会在上面自己开一个MCP Server来让Skill调用。 3. 部署Skill 点击右上角的“部署”按钮,跳过变量设定,秒级完成部署。 三、Skill的使用 通过上面的步骤,我的扣子版的书签管理Skill就完成了,并且可以直接在扣子上使用了。使用方法也很简单,在聊天框里输入 @ ,然后在跳出来的选项框里选择技能,技能列表里会包括所有你安装的和创建的技能列表,在那里选择“书签管理技能”。 四、进一步完善 希望收藏下来的文章的可以按我的要求来命名文件,保存的路径,以及图片的路径,那就让它再来改一下吧。 最后,扣子再输出了一版SKILL,并简单测试了一下包括新浪新闻,今日头条,CSDN,博客园,知乎等网站的文章都可成功抓取。收工! 五、完整代码 考虑到未来SKILL无限的可能性,我准备再建一个仓库,然后把一些自己实现的SKILL都放到这个仓库里。今天的扣子版本的书签功能的SKILL是第一个。 仓库地址: https://github.com/oddmeta/odd-skills 感兴趣的大佬可以直接到这里下载完整的代码。也可私信我,我发你。
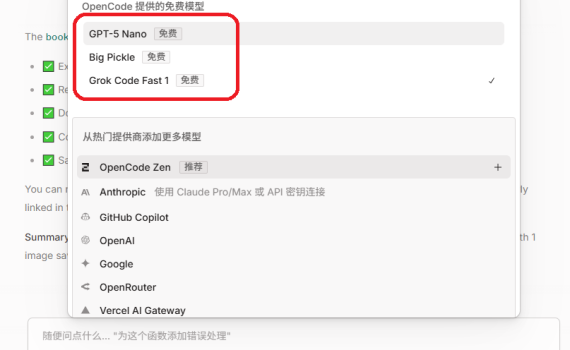
一、前言 上周扣子成为第一个支持skills的国内的大模型,但是这阵子公司这边的事情一直很忙,项目急,领导们都盯着,所以一直没有没时间去测试。 但是事实上之前我已经用open code desktop试过来实现一个skills,只是文章写了一半,一直没发,今天晚上再重新整理了一下,让open code实际来写一个skills,并将完整的过程给大家做一个演示,相信看了之后,任何一个小白(不需要编程知识)都可以来实现自己想要的功能了。 我一直想给小落同学做一个书签功能。原因如下: 当你看到一篇好文章,想保存下来慢慢看,结果网页上广告横幅、导航栏、推荐阅读啥的占了一大半空间。等到真正想看的时候,还得翻半天找正文。更烦人的是,现在很多网站都是单页应用,用JavaScript动态加载内容。直接用浏览器保存或复制粘贴,往往只能拿到个加载动画,完全看不了内容。于是我就想,能不能做一个工具,自动抓取网页,去掉那些乱七八糟的东西,把正文提取出来,保存成干净的Markdown格式?图片也能一并保存下来。 现在刚好用OpenCode Desktop来演示一下,如何实现一个书签功能的Skills,而且可以通过MCP协议接入外部服务。 二、测试运行环境 1. 测试环境 依旧在我这个超过十年的老笔记本上,我的操作系统是Windows 7。如果你是新版本的Windows,或者是Mac OS,或者Linux,整个流程基本上也没什么差别(理论如此哈,我还没验证过,若真在安装使用open code时,有什么问题也可提出来)。 2. 测试使用的版本 Open Code Desktop 的下载安装我就快速跳过了,大家随便哪儿搜一下都能下载到。 安装完成OpenCode Desktop后,启动,完成基础登录 / 初始化配置,比如:选择使用的大模型。 三、从零开始实现书签功能Skills 1. 给OpenCode的提示词 直接在OpenCode Desktop里,告诉他你想要一个什么样的东西,一些具体的要求。 注:这里的描述很重要,而且最好是描述能够一次成型。但是实际上一次成型是不可能的。不过你可以生成一次后,看下效果是否跟你预期一致,如果不一致,那就直接左上角:新建会话(+ New session),然后再一步步完善你的描述,然后一次次重试直到你基本满意。 以下是我的提示词: 2. OpenCode Desktop的输出 输入提示词之后,OpenCode就开始工作了,大概等待了两三分钟,它给我输出了一个结果,同时也创建好了整个书签Skills,书签的MCP Server:bookmark_it_server.py,以及这个MCP Server的Python依赖,具体项目目录结构如下: 3. 关键代码 1)MCP服务器配置 代码位置: .opencode/opencode.json 2)MCP服务器主要代码 代码位置:bookmark_it_server.py 3)Skills配置 […]

一、前言 前阵子写了几篇大模型开发相关的入门的文章,然后有同学私信说自己训练或者微调出来的模型效果不如预期,对于这一点,我在前面的文章里也反复强调过多次,对于大模型来说,唯一真正有价值的只有:数据。脸书扎克伯格花大价钱ScaleAI的底层逻辑也在于此。 在现在这个时代,完全可以说,大部分的技术都是没有什么价值的,因为大部分的技术都是有手就行。真正的价值都在数据,而且最有价值的数据往往都是一个个的专业领域的数据,决定大模型微调效果的是数据,决定你整个产品成败的也是数据,这个事情一定要搞清楚。所以呢,建议大家从现在开始,给自己好好做积累吧,把你的行业数据、专业领域的数据一点点积累好,这才是你的未来。 而数据中最重要的还是实际的业务数据,并不是让大模型帮你生成的数据,但是如果你是为了做一些项目的测试的话,让大模型来帮忙丰富一下你的数据集也是一个不错的选项。这里就用我自己的一个实际的用于语音助手的案例,来手把手教你如何利用大模型来帮你生成一些数据。 【有手就行】大模型开发入门系列 二、让大模型帮忙生成训练集 之前用的更多的是利用ChatGPT来生成数据,但是为了写这篇文章,我又专门用千问、文心、豆包、ChatGPT走了一遍完整流程。这篇文章主要有用的就是生成数据的提示词,顺便用这个实例介绍对比一下几个主流模型的表现,供大家参考。 从这一轮次的的测试生成数据集的情况来看,印象分最好的要算Qwen3-Max,而ChatGPT则垫底了。看来中文还是得选中国的大模型。另外,犹记当年第一届世界人工智能大会时,马云跟马斯克吹牛:AI就是Alibaba Intelligent,这牛吹的当年所有人都想笑,再过几年看看Alibaba到底能不能笑傲江湖,让咱们座目以待。 此外,具体每个大模型生成的数据由于太大,在这里我就不列了,不过我保存到了云盘,感兴趣的可以后台私聊我:【测试集】,会自动回复下载链接,同时你也可以自行生成。 1. 千问 使用模型:Qwen3-Max 秒级响应。刺溜一下就给生成好了。而且是一步到位,不像豆包、文心那样,先生成数据,再自己写代码把数据保存到一个json文件。千问牛逼格拉斯。不过,生成的json文件在公司不能下载(在家里正常),可能跟公司网络DNS有关。 生成的文字多样性佳: 2. 百度文心一言 使用模型:文心大模型X1.1 为每个意图生成50条数据很快,但是文心一言为了将结果保存到json文件费了老大的劲,因为它是自己写代码来实现的,而它写的代码执行的报错了好多次,然后它自己一直在改它自己的代码,结果浪费了很多时间,XD 生成的文字多样性: 但是它在这个请求里自己生成的代码出问题,扣掉了我对它的印象分。 3. 豆包 使用模型:豆包上没写版本号,公有云的反正是最新的。 豆包-同文心,也是自己写代码生成json,比百度好一点,保存json的代码一次成功,没有改半天代码。生成的文字多样性也不错。槽位的准确率100%。它相比文心好的地方就是保存json的代码一次成功,没让我等半天。 生成的文字多样性: 4. ChatGPT 使用模型:普通版本(非Business版本) For quick tasks & answers 速度跟豆包差不多。思考过程在生成后不能查看,所以不清楚是跟千问一样,一步到位,还是跟豆包、文心一样,先生成数据,再写代码存文件。 生成的文字的多样性: 三、注意事项 如果你生成数据的目的是为了训练的话,建议的做法还是要用一些实际的数据,而不是找大模型来帮你生成数据,这一点很重要。但是如果你是为了学习大模型训练或者大模型微调的话,可以考虑让大模型帮你生成一些数据,但仅限于学习。毕竟,大模型生成的数据都不一定是真正你的产品、业务所需要的数据。 四、广而告之 新建了一个技术交流群,欢迎大家一起加入讨论。扫码加入AI技术交流群(微信)关注我的公众号:奥德元让我们一起学习人工智能,一起追赶这个时代。

一、前言 1. 本文目标 你有没有问过大模型“你是谁”?问了的话,拿到的答案清一色都是大模型厂商的名字。而如果你自己部署了一个模型的话,通常都希望有人在你的应用里问你是谁的时候能给出一个“你的答案”。这篇文章就是干这个事情的,20分钟让大模型的名字变成你自己的名字。 2. 大模型入门系列介绍 前阵子介绍了两个【有手就行】的大模型基础知识,今天是大模型开发【有手就行】的第三篇。 前两部在这里: 这个是入门三步曲最后一步:MS-SWIFT认知微调,把大模型的名字改成你的名字。 上手学习大模型、人工智能相关的开发并没有什么太过高深的门槛,真的很简单,真的就是【有手就行】。 二、SWIFT认知微调相关的一些废话 1. 什么是ms-swift ms-swift(全称 Scalable lightWeight Infrastructure for Fine‑Tuning)是阿里的魔搭社区(ModelScope) 推出的一个大模型全流程工程化框架,是 “大模型轻量微调与部署的基础设施”,在消费级 GPU 与国产硬件也都可用,我有在4090,PPU平头哥、Ascend昇腾上都用过。 2. 为什么要做ms-swift微调 就像之前讲的那样:自己从头开始训练一个基座大模型是不现实的,只能以学习目的来了解大模型是如何训练出来的,有哪些步骤,会有一些什么样的训练参数、每个参数的意义和影响是什么等。所以大家更多会涉及的是利用一些现有的开源大模型来做微调,用自己的个人数据、行业数据来微调训练大模型,然后让这个大模型变成你自己的私人大模型或者行业大模型。可惜我自己觉得最重要的LoRA微调的那篇文章反而看的人比较少(一如既往的不太懂,呵呵),可能是我取的标题不够“标题党”(求大佬们指教),也可能跟公众号推荐规则有关。而一旦你自己微调训练了一个大模型,那随后必做的一件事情就是把这个大模型的名字变成你自己,当有人问它:“你是谁?”的时候,它回答的应该是:它是xxx(你给它取的名字),是由yyy(你的名字)开发出来的。比如: 我是小落,是由落鹤生开发的个人智能助手。我主要的目的是通过记录落鹤生每天的日常工作、生活的点点滴滴,然后希望在数据足够的某一天,我可以成为一个数字复刻版本的落鹤生。如果您对小落同学有任何疑问或需要帮助,请随时提出,我会尽力为您解答。 三、开始 ms-swift支持 600 多个纯文本大型模型和 300 多个多模态大型模型的训练。为方便同学们复现,我以 Qwen3-4B-Instruct模型为例 ,从模型下载开始介绍整个流程。如果有问题可以直接在下面留言,或者加一下AI技术学习交流群一起讨论。 1. 模型下载 从modelscope下载需要的模型(huggingface不太稳定,当然也可以用镜像站:https://hf-mirror.com ) 2. 原始模型部署 原则上,你的服务器上有多少GPU就都给你用上先。 3. 原始模型测试 4. 微调Qwen3-4B-Instruct-2507模型 这里在我原先的OddAgent项目基础上训练一个会议语音指令助手。这里使用官方的示例对Qwen3-4B-Instruct-2507模型进行自我认知微调。 1)安装ms-swift框架 pip 源码方式 […]
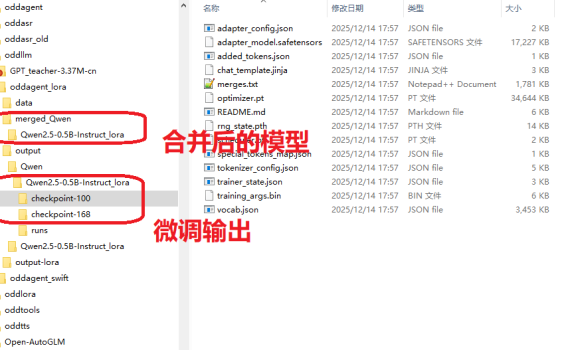
一、前言 上上周的周末无事在家,然后写了一篇《【有手就行】自己花20分钟从0开始训练一个“大模型”》,结果发现这两个星期涨了几十个关注,比我前面写了几个月文章得到的关注还多,看来这种浅显易懂的、入门级的技术文章相对来说会有更多人爱看一些。既然如此,我再把早先在做OddAgent时候,微调语音助手功能的流程也简单理一下,然后放出来给大家做一个参考吧。 事实上,上手学习大模型、人工智能相关的开发并没有什么太过高深的门槛,真的很简单,真的就是【有手就行】。 二、大模型微调概述 微调(Fine-tuning)有很多种不同的方法,但是使用的场景以及代价也都是不一样的。作为一个没什么资源(数据缺缺,GPU缺缺)的普通人来说,考虑的肯定是低成本方案。 方法类型 参数更新范围 计算成本 适用场景 典型工具框架 全参数微调 全部参数 极高 大数据集、高资源场景 Hugging Face Transformers Adapter Tuning 适配器参数 低 多任务、资源受限 AdapterHub、PEFT LoRA/QLoRA 低秩矩阵参数 极低 大模型单卡微调、小样本 LoRA、QLoRA(PEFT 库集成) 指令微调 全量 / 部分参数 中 – 高 通用对话模型、多任务泛化 Alpaca-LoRA、FastChat 领域适配微调 全量 / 部分参数 中 垂直领域任务 自定义领域数据集 + Transformers 三、LoRA微调全流程 前阵子在将小落同学项目的智能体代码摘成独立的OddAgent项目时,实践的是一个会议相关的语音助手功能,该功能有针对Qwen2.5-0.5B-Instruct模型和Qwen3-4B-Instruct-2507这两个模型重点做了一些测试和验证,用的就是其中成本最低的LoRA微调。最后跑下来Qwen3-4B-Instruct-2507的效果要显著好于Qwen2.5-0.5B-Instruct(有同时针对这两个模型用同一套数据集去做了LoRA微调)。因此,本文的重点就放在了Qwen2.5-0.5B-Instruct的LoRA微调上,因为后面我还准备再继续针对这个模型再补充一些训练集来做一下微调,目标是在这个模型上也能做到100%的意图/槽位准确率。 跟之前训练大模型一样,还是在我家里的这个10年前的老笔记本上进行的。 […]
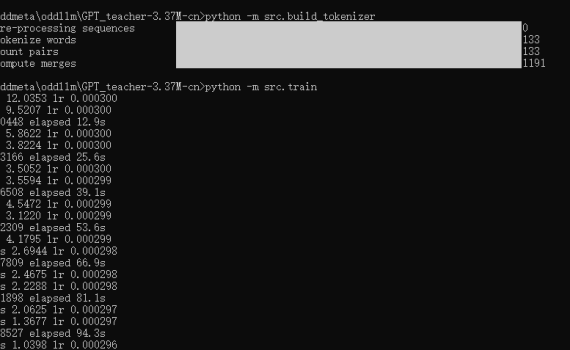
一、说在前面 训练基座大模型那都是大公司们的事情,普通人、普通公司肯定是玩不起的,但是作为一个技术人,你可以不去做真正的大模型训练,但是你还是有必要知道和了解一下一个大模型是如何训练出来的。 而GPT_teacher-3.37M-cn 是一个很好的示例项目,让你可以用一台普通的PC,用CPU来训练一个3.37M的中文GPT模型,整个训练耗时不到20分钟,回答训练集里的问题的效果也还是挺不错的。感兴趣的同学可以用这个项目来练手、实操复现一下“自己动手从0开始训练一个大模型”的完整流程。 二、项目概述 一个轻量级中文GPT模型项目,专为在CPU上快速训练和演示而设计: 模型参数量:3.37M架构:4层Transformer解码器特点:使用RMSNorm、RoPE位置编码、权重共享等优化技术目标:45分钟内在普通CPU上训练出可用的中文问答模型 参考训练时长: 三、完整复现流程 介绍完了,就让我们来实操整个从0到1的训练吧。 先下载代码: 1. 环境准备 依赖项包括: 2. 构建中文分词器 这将: 3. 配置文件确认 config.yaml包含了所有必要配置,我在这里给每个参数加了个说明,以便于理解每个参数的意义。 4. 执行训练 5. 测试模型 训练完成后,根据src/train.py中的代码,最终会在config.yaml指定的目录下(checkpoints)生成一个标准的模型,以及一个量化的模型,分别是: 然后你可以用下面的命令来测试一下训练集(位于data/train.jsonl)里的一些问题: 四、关键技术点解析 在这个示例的大模型训练里,我们基于Decoder-only的Transformer(因果语言模型),使用下三角掩码确保每次只关注历史信息,这正是GPT系列模型能够生成连贯文本的核心。 1. 训练参数说明 具体的训练参数我在上面的config.yaml里给每个参数都写了一个注释,用于说明每个参数的意义。而总结概括一下这个配置参数的话,主要如下: 2. 关键代码 五、补充说明 1. 仅3.37M参数远达不到scale law 这个项目只是一个演示项目,教你如何自己动手从0到1来训练一个大模型,但是必须要知道的是大模型有个别称是 scale law,所以走传统transfomer路线的话,注意力是非常吃参数的,这么一个参数量,其输出完全肯定不会非常好(除非你问的就是训练集里的知识)。同时在这个项目的训练集(位于data/train.jsonl)里你也可以看到,虽然有510条训练数据,但实际上里面的内容全是Ctrl C + Ctrl V出来的,真正的prompt和completion就几条。 2. 为什么问一些不在训练集里的问题时,返回乱七八糟的东西,而不是“不知道” 大模型的本质是一个词语接龙游戏,每出一个字,根据概率去预测下一个字是什么。其目标是生成流畅的文本,而不是正确的文本,它只是在模仿训练集里的文本概率,而不是真正的理解内容,所以最终的效果完全取决于你给它的训练数据。因此,当你去问不在训练集里的问题的时候,大模型就只能随便的去猜下一个字可能是什么字,而不是直接给你回答一个“不知道”,这也是大模型“幻觉”的由来。 3. 关于大模型幻觉 大模型幻觉主要有四种幻觉类型:前后矛盾,提示词误解,事实性幻觉,逻辑错误。幻觉主要有三大成因:数据质量问题,生成机制缺陷,模糊指令。幻觉通常有五种解决方案:精准提示词、示例学习、调参、RAG技术、幻觉检测方案,并让大模型学会给答案标注“参考文献”(溯源)。 […]

一、前言 昨天晚上想给oddtts项目的启动命令行里加一个OddMeta的ASCII art文字的代码输出。 一如既往,想让我自己写那是坚决不可能的,这种事情有大模型了,为什么还要自己来写呢。 但是,(省去一万字),无奈的发现国内外的各个大模型全部翻车了,包括(一定要把它们的大名列出来,恨!!!): 为了这个ASCII码字体,浪费了我一下午,加半个晚上,整个过程只能说用”无语”一词来形容,本来想算了,但是又实在有点气不过,心中默念了 @#¥%……&O()~!无数遍,最后决定还是将整个过程跟大家分享一下。 二、悲伤历程 1. TRAE AI 平时用的比较多的TRAE AI,我就信心满满的打开平时用的TRAE,Come on baby, let’s go. 1)Round 1:信心满满 我让它生成OddMeta,它这给了个啥玩意??? 2)Round 2:要让再次修改 3)Round 3/4/5/6/7/8 对于上面的结果,我很不满意,然后又用各种方式让它重新修改,但是没有一个结果是正确的。咒骂了TRAE无数次之后,我想TMD你不行,幸亏除了你之外,哥还有通义灵码。 2. 通义灵码 1) 给通义灵码一个示例让它改 2) 这个结果看上去比TRAE稍好一点,文字有点像了,但还是不对。 不对,然后我又尝试了包括但不仅限于下面这些输入。 结果还是不对! 还是不对!! 还是不对!!! 还是不对!!!! 3) 评价:咒骂x2,放弃通义灵码 口中念念有词:~!@#¥%…………&()¥ 3. 豆包: https://www.doubao.com/chat 豆包也是个不错的大模型,还是让它来试试吧。 1)重走TRAE的流程 2)重走通义灵码的流程 4. Deepseek 5. 文心一言 6. ChatGPT […]

一、前言 这段时间,在非工作时间我一直在致力于做一个在低配置的硬件上可实际运行的个人智能助理:小落同学。然而前两天谷歌的2025 Google I/O大会发布的Gemma 3n真的让我震撼了。 二、关于Gemma 3n 2025年5月21日,在一年一度的谷歌I/O大会上,谷歌推出了Gemma 3n – Gemma 3系列开放式人工智能模型的新成员。谷歌表示,该模型旨在在智能手机、笔记本电脑和平板电脑等日常设备上高效运行。Gemma 3n与下一代Gemini Nano共享其架构,Gemini Nano是一种轻量级的AI模型,已经为Android设备上的几个设备上的AI功能提供了支持,例如Pixel智能手机上的录音机摘要。 详细信息 谷歌表示,Gemma 3n使用了一种名为Per-Layer Embeddings(PLE)的新技术,可以让模型比类似大小的其他一些技术的模型消耗更少的RAM。尽管Gemma 3n有50亿和80亿个参数(5B和8B),但PLE技术让它的内存占用仅相当于2B或4B模型。这意味着Gemma 3n可以在2GB到3GB的RAM下运行,使其适用于更广泛的设备。 图片来自Google Blog:https://developers.googleblog.com/en/introducing-gemma-3n/ 图片来自Google Blog:https://developers.googleblog.com/en/introducing-gemma-3n/ 关键功能 可用性 作为Gemma开放模型系列的一部分,Gemma 3n提供了可访问的权重,并获得了商业使用许可,允许开发人员在各种应用程序中对其进行调优、调整和部署。Gemma 3n现在可以在Google AI Studio中预览。 三、如何获取Gemma 3n? Gemma 3n预览版可在谷歌人工智能工作室(Google AI Studio)、谷歌GenAI SDK和MediaPipe(Huggingface和Kaggle)中使用。 下面是在Google AI Studio中使用Gemma 3n的具体步骤: Step 1: 登录 Google AI studioStep 2: […]