一、导言
***牵头组织了一个会议,对Deepseek在视讯方案的可能性进行了一番讨论,讨论后的结论是对Deepseek先做一番技术上的预研,然后再上产品路标。后来**和**也针对此事做了一些交待。再后来就是撸起袖子了。
二、预研目标
《Deepseek在视讯方案的可能性》:一句话表示:在消费级的GPU上跑满血版Deepseek R1
1、GPU:结合公司的实际情况(还躺在米国政府的黑名单上),预研所针对的硬件必须是我们有可能买得到的硬件。
2、Deepseek R1满血版:预研初期确定的目标是满血版Deepseek R1 671B(实际测下来发现可能存在一些问题)

三、预研情况说明
在曾哥租到GPU服务器之后,有了硬件资源后,主要利用这个GPU服务器做了以下几部分预研。
一是包括Deepseek/QwQ32-B/Gemma3等等在内的大模型安装、部署与测试。
二是有了大模型之后,视讯这边可能的一些应用,包括:Chat API, Agent等。
三是与KIS做了一些集成测试。
四是视讯智能产品KIS相关的一些周边技术,包括:ASR, TTS等。
一)预研设定的环境
1. 软件环境
PyTorch 2.5.1
Python 3.12(ubuntu22.04)
Cuda 12.4
2. 硬件环境
○GPU:RTX 4090(24GB) * 2
○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430
○内存:480G(至少需要382G)
○硬盘:1.8T(实际使用需要380G左右)
参考:京东上GPU 4090 x2+CPU 6330 +内存64G+硬盘2T报价约为:69500。https://item.jd.com/10106874216614.html
二)大模型测试
直接上结论。
测试结果
| 大模型 | 框架 | max_new_tokens | context | GPU数量 | TPS(单连接) | TPS(多连接) |
|---|---|---|---|---|---|---|
| ds-r1-671b Q4 | KT | 8192 | 32768 | 1 | 6~8 tps | 排队 |
| ds-r1-671b unslosh Q4 | KT | 8192 | 32768 | 1 | 6~8 tps | 排队 |
| ds-r1-671b nvidia Q4 | ? | ? | ? | ? | ? | ? |
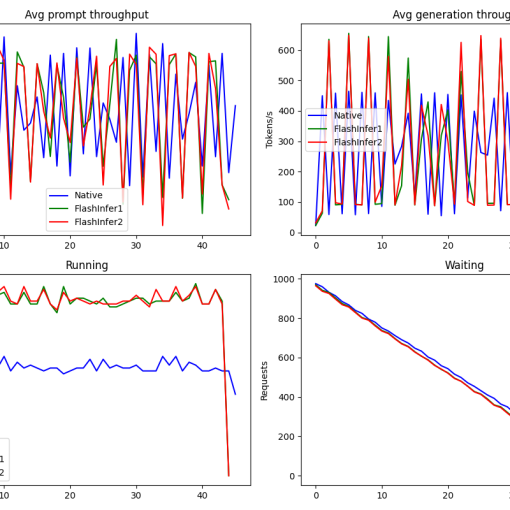
| qwq-32b-awq(q4) | vllm | 5168 | 32768 | 1 | 40~60 tps | 2x(30~50)=60~100tps |
| qwq-32b-awq(q4) | vllm | 16384 | 32768 | 2 | 40~60 tps | 4x(40~60)=160~240tps |
| gemma3-27B | ollama | 8192 | 32768 | 1 | 40~60 tps | ? |
| gemma3-27B | ollama | 8192 | 32768 | 1 | 40~60 tps | ? |
注:
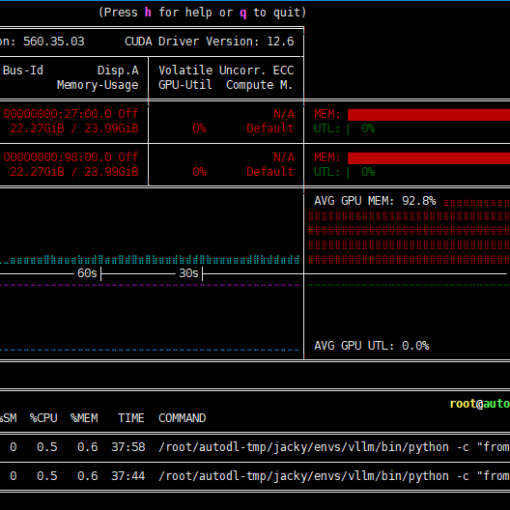
- 由于租用AutoDL上的GPU服务器是共享出来的虚机,因此性能测试数据时常会有挺大的波动,通常晚上跑的数据会比较好,白天一般都会比较差。
- KTransformers 0.2.3(及以下版本) + Deepseek的测试下,会有一个冷启动的过程,初次使用时think可能会花几分钟时间,体验不佳。
- KTransformers + Deepseek方案下并发存在问题。
- QwQ-32B-AWQ版本后期在跟KIS联调的时候,在跑单GPU的情况下可能会出来因new token数超限而中途被截断问题。建议配置要求4090*2。
初步结论1(产品建议)
- 测试指标:在当前有限的测试中,QwQ-32B在性能、并发等方面相对表现突出。
- 产品化建议:建议选择Deepseek R1 671B + QwQ-32B。其中Deepseek R1 671B作为处理复杂问题(研发及代码)较好,且有概念光环对产品及宣传多有裨益;而QwQ-32B对公司内部多并发场景下的实际使用及体验更有友好。
初步结论2(研发参考)
- GPU单卡或者多卡对实际运行效率的影响
GPU对实际运行效率提升不大,单卡3090、单卡4090、或者是多卡GPU服务器都没有太大影响,只需要留足20G以上显存(最小可行性实验的话只需要14G显存)即可; - 权重规则的运行效率tps的影响
若是多卡服务器,则可以进一步尝试手动编写模型权重卸载规则,使用更多的GPU进行推理,可以一定程度减少内存需求,但对于实际运行效率提升不大。最省钱的方案仍然是单卡GPU+大内存配置; - 资源利用率不高的问题
KT在运行时,相较于vllm而言,CPU和GPU的利用率都不高,中间曾对optimize rule(DeepSeek-V3-Chat.yaml / DeepSeek-V3-Chat-multi-gpu.yaml)中的多项参数做过一些调整,希望将inference的任务更偏GPU或更偏CPU,但未见明显改善。 - KTransformers版本对性能的影响
KTransformer目前有V0.2.0、V0.2.1、V0.2.2和V0.3.0,其中V0.3.0目前只有预览版,只支持二进制文件下载和安装,而V0.2.0和V0.2.1支持各类CPU。从V0.3.0开始,只支持AMX CPU,也就是最新几代的Intel CPU。
这几个版本实际部署流程和调用指令没有任何区别,若当前CPU支持AMX,则可以考虑使用V3.0进行实验,推理速度会提升40%左右。
三)WebUI、API及Function Call
针对Open WebUI及其与后端的KTransformers, Ollama, llama.cpp, vllm等不同的框架做了一些配置及接口测试,包括附件聊天(知识库)功能,联网搜索功能,语音(ASR+TTS)功能等等。
各项功能皆正常。
在QwQ-32B模型下测试简单OpenAI API、Agent及Agentic RAG功能可正常解析、运行和响应。
注:测试涉及的各模型都可兼容OpenAI的API接口,这意味着我们用一套接口即可实现跟不同LLM的对接,不需要关心后端运行的到底是哪一家的LLM。
四)与KIS集成后测试效果截图
跟春哥一起初步把功能接口调试通过。效果直接看截图或者自行上测试环境体验。测试环境在后面有列,欢迎测试和意见。
豆包效果

官方Deepseek效果


开源Deepseek效果


千问MAX效果



开源QwQ-32B-AWQ效果


开源QwQ-32B-AWQ效果2



KIS上使用Deepseek和QwQ 32B的对比




五)智能周边技术
- 开源ASR引擎
主要针地Wisper, FunAsr, FireRedAsr 做了一些简单的对比测试,测试仅限于长语音,短语音和实时语音时间关系未涉及。
测试序列用的是早先KIS做的那10个测试集。
最终与KIS 现有的阿里2.7引擎对比下来,阿里2.7引擎明显要比Wisper, FunAsr, FireRedAsr要好一些。最终在这个测试集里跑下来的结果如下:
阿里2.7 > FireRedAsr > FunAsr > Wisper - 开源TTS引擎
由于视讯目前对TTS的需求相对比较简单,不涉及语音克隆,以及对语色、语调、情绪、语速及一些俚语相关的专门处理,因此TTS引擎可用就行。微软的
四、常见关注项说明
简单列几个大家可能会关注的一些问题,若有其他问题随便打断我,提出来。
Q: 公有云 vs 私有云
A: 技术维度而言,两种模式都可以做到,具体需由产品部门根据实际的需求来定。
Q:会议结束后,多久可以出会议摘要?
A: 在KIS生成了会议纪要后,KIS调用大模型来生成摘要,
如果用的是Deepseek R1 671B Q4版本的模型的话,至少需要十几分钟。
如果用的是QwQ-32B的模型,可以控制在2分钟以内;
- 具体时间跟实际会议纪要的长度直接相关。
Q: Deepseek R1满血版速度太慢了,是否可以搞快点?
A: 时间关系配置优化测试还做的不够,但硬件限制了理论上限。两个办法可提速,升硬件,降参数(不用满血版)
五、测试及体验环境
目前GPU服务还在租用中,欢迎大家实际体验,并提出意见。
大模型测试地址:
http://172.16.129.127:3000
admin1@localhost 123456
admin2@localhost 123456
user1@localhost 123456
user2@localhost 123456
会议概要测试环境:
http://10.67.20.38
HCH 888888

{kind=link}
{kind=link}
{kind=link}
{kind=link}