相比于ollama, llama.cpp等框架, vllm是一个可以产品化部署的方案,适用于需要大规模部署和高并发推理的场景,采用 PagedAttention 技术,能够有效减少内存碎片,提高内存利用率,从而显著提升推理速度。在处理长序列输入时,性能优势更为明显。因此,今天先用vllm来验证一下QWQ32B 的情况。
硬件环境
租的AutoDL的GPU服务器做的测试
•软件环境
PyTorch 2.5.1、Python 3.12(ubuntu22.04)、Cuda 12.1
•硬件环境
○GPU:RTX 4090(24GB) * 2
○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430
○内存:480G(至少需要382G)
○硬盘:1.8T(实际使用需要380G左右)
一、虚拟环境
conda create –prefix=/root/autodl-tmp/jacky/env/vllm python==3.12.3 conda activate /root/autodl-tmp/jacky/envs/vllm/
pip install vllm
二、安装 vLLM
export VLLM_VERSION=0.6.1.post1 export PYTHON_VERSION=310 pip install https://github.com/vllm-project/vllm/releases/download/v${VLLM_VERSION}/vllm-${VLLM_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux1_x86_64.whl –extra-index-url https://download.pytorch.org/whl/cu118
三、从huggingface下载模型
计划测试 Q4量化版本:QwQ-32B-unsloth-bnb-4bit,但实际成功测试的不是unsloth的这个 Q4版本,而是阿里官方量化的QwQ-32B-AWQ,原因是vllm不支持(曾经支持过unsloth的版本,但后面又不行了)。
用AutoDL自带的代理访问huggingface
https_proxy=http://172.29.51.4:12798 http_proxy=http://172.29.51.4:12798
setproxy.py
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value
执行 python setproxy.py 设置代理环境变量
然后再下载:
huggingface-cli download --resume-download unsloth/QwQ-32B-unsloth-bnb-4bit --include "*" --local-dir /root/autodl-tmp/QwQ-32B-unsloth-bnb-4bit
使用国内的镜像站:https://hf-mirror.com ,速度很快。
一开始下载gguf的:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download unsloth/QwQ-32B-unsloth-bnb-4bit --include "*" --local-dir /root/autodl-tmp/QwQ-32B-unsloth-bnb-4bit
vllm不支持gguf格式的模型,千万不要下gguf模型了,下huggingface原版的
在unsloth网站上(https://unsloth.ai/blog/qwq-32b )看到说vllm支持他们改的dynamic q4的版本。
 他们的dynamic 4-bit quants版本下载地址:https://huggingface.co/unsloth/QwQ-32B-unsloth-bnb-4bit
他们的dynamic 4-bit quants版本下载地址:https://huggingface.co/unsloth/QwQ-32B-unsloth-bnb-4bit
把huggingface.co改成hf-mirror.com, https://hf-mirror.com/unsloth/QwQ-32B-unsloth-bnb-4bit/tree/main 下载
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download unsloth/QwQ-32B-unsloth-bnb-4bit --include "*" --local-dir QwQ-32B-unsloth-bnb-4bit
下载下来后,运行仍然报错: 运行命令:
CUDA_VISIBLE_DEVICES=0 python3 -m vllm.entrypoints.openai.api_server --model ./QwQ-32B-unsloth-bnb-4bit/ --host 0.0.0.0 --port 12344 | tee qwq32b-q4.log1
报错:
KeyError: 'layers.26.mlp.down_proj.weight.absmax'
Loading safetensors checkpoint shards: 0% Completed | 0/5 [00:00<?, ?it/s]
找到vllm官网,宣称支持unsloth dynamic q4的pull request: https://github.com/vllm-project/vllm/pull/12974 修改的文件: bitsandbytes.py: 文件位于: ~/autodl-tmp/jacky/envs/vllm/lib/python3.12/site-packages/vllm/model_executor/layers/quantization
四、功能测试
测试命令
测试一:QWQ32B失败(显存不够)
CUDA_VISIBLE_DEVICES=0,1 \
vllm serve /root/autodl-tmp/jacky/models/QWQ32B \
--tensor-parallel-size 2 \
--port 12344
创建兼容 OpenAI API 接口的服务器。运行以下命令启动服务器
CUDA_VISIBLE_DEVICES=1 \
python3 -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/jacky/models/QWQ32B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-code
测试二:QwQ-32B-AWQ成功
- 启动QWQ
“`shell
CUDA_VISIBLE_DEVICES=0,1
vllm serve /root/autodl-tmp/HF_download/hub/models–Qwen–QwQ-32B-AWQ/snapshots/4e95b98be0332075ac9e4eb144d402a5ea8ad4f0 \
–tensor-parallel-size 2
–port 8000
vllm serve Qwen/QwQ-32B-AWQ --max-model-len 5680
- **请求调用**
```shell
curl http://127.0.0.1:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/QwQ-32B-AWQ",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
启动open webui
ssh转发
ssh -CNg -L 3000:127.0.0.1:3000 root@connect.nmb1.seetacloud.com -p 22305
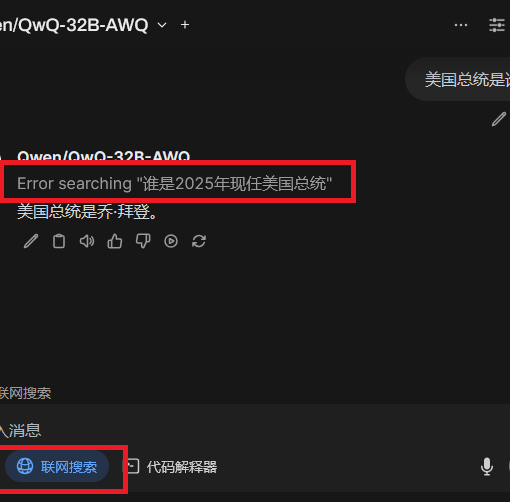
fljuF67Nylm7问题
报错:The model’s max seq len (40960) is larger than the maximum number of tokensERROR 03-12 09:34:39 engine.py:400] The model's max seq len (40960) is larger than the maximum number of tokens that can be stored in KV cache (6368). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
ERROR 03-12 09:34:39 engine.py:400] Traceback (most recent call last):
ERROR 03-12 09:34:39 engine.py:400] File "/root/autodl-tmp/jacky/envs/vllm/lib/python3.12/site-packages/vllm/engine/multiprocessing/engine.py", line 391, in run_mp_engine解决方案:降低–max-model-len到5680
vllm serve Qwen/QwQ-32B-AWQ --max-model-len 5680
五、性能测试
| GPU | max-model-len(token) | GPU | tps | CPU | MEM | 命令 |
|---|---|---|---|---|---|---|
| 1 | 5168 | 0.90 | 40+ | 100% | 0.6% | vllm serve Qwen/QwQ-32B-AWQ --max_model_len=5168 |
| 1 | 12000 | 0.99 | 40+ | 100% | 0.6% | vllm serve Qwen/QwQ-32B-AWQ --max_model_len=12000 gpu_memory_utilization=0.99 |
| 2 | 16384 | 0.99 | 60+ | 100% | 0.6% | vllm serve Qwen/QwQ-32B-AWQ --max_model_len=16384 --gpu_memory_utilization=0.99 --tensor-parallel-size 2 |
| 2 | 32768 | 0.99 | 40+ | 100% | 0.6% | vllm serve Qwen/QwQ-32B-AWQ --max_model_len=32768 --gpu_memory_utilization=0.99 --tensor-parallel-size 2 |
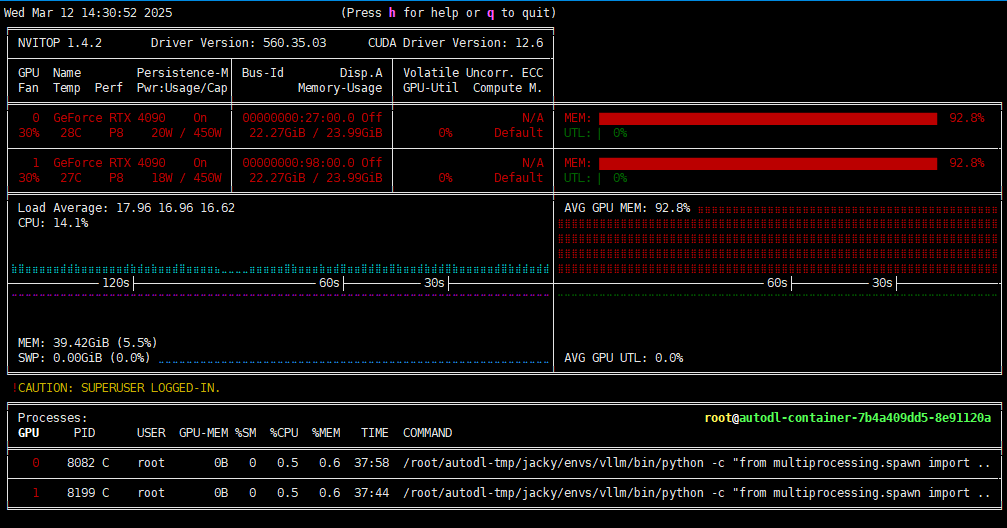
附录
INFO 03-12 13:21:22 api_server.py:913] args: Namespace(
subparser='serve', model_tag='Qwen/QwQ-32B-AWQ',
config='', host=None, port=8000,
uvicorn_log_level='info', allow_credentials=False,
allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'],
api_key=None, lora_modules=None, prompt_adapters=None,
chat_template=None, chat_template_content_format='auto',
response_role='assistant',
ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None,
ssl_cert_reqs=0, root_path=None, middleware=[],
return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False,
enable_request_id_headers=False, enable_auto_tool_choice=False,
enable_reasoning=False, reasoning_parser=None,
tool_call_parser=None, tool_parser_plugin='',
model='Qwen/QwQ-32B-AWQ', task='auto', tokenizer=None,
skip_tokenizer_init=False, revision=None, code_revision=None,
tokenizer_revision=None, tokenizer_mode='auto',
trust_remote_code=False, allowed_local_media_path=None,
download_dir=None, load_format='auto',
config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto',
kv_cache_dtype='auto',
max_model_len=16384, guided_decoding_backend='xgrammar',
logits_processor_pattern=None, model_impl='auto',
distributed_executor_backend=None,
pipeline_parallel_size=1,
tensor_parallel_size=2, max_parallel_loading_workers=None,
ray_workers_use_nsight=False, block_size=None,
enable_prefix_caching=None, disable_sliding_window=False,
use_v2_block_manager=True, num_lookahead_slots=0, seed=0,
swap_space=4, cpu_offload_gb=0,
gpu_memory_utilization=0.99, num_gpu_blocks_override=None,
max_num_batched_tokens=None,
max_num_partial_prefills=1,
max_long_partial_prefills=1, long_prefill_token_threshold=0,
max_num_seqs=None, max_logprobs=20, disable_log_stats=False,
quantization=None, rope_scaling=None, rope_theta=None,
hf_overrides=None, enforce_eager=False,
max_seq_len_to_capture=8192, disable_custom_all_reduce=False,
tokenizer_pool_size=0, tokenizer_pool_type='ray',
tokenizer_pool_extra_config=None, limit_mm_per_prompt=None,
mm_processor_kwargs=None, disable_mm_preprocessor_cache=False,
enable_lora=False, enable_lora_bias=False,
max_loras=1, max_lora_rank=16,
lora_extra_vocab_size=256,
lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None,
fully_sharded_loras=False, enable_prompt_adapter=False,
max_prompt_adapters=1,
max_prompt_adapter_token=0,
device='auto',
num_scheduler_steps=1, multi_step_stream_outputs=True,
scheduler_delay_factor=0.0, enable_chunked_prefill=None,
speculative_model=None, speculative_model_quantization=None,
num_speculative_tokens=None, speculative_disable_mqa_scorer=False,
speculative_draft_tensor_parallel_size=None,
speculative_max_model_len=None, speculative_disable_by_batch_size=None,
ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None,
spec_decoding_acceptance_method='rejection_sampler',
typical_acceptance_sampler_posterior_threshold=None,
typical_acceptance_sampler_posterior_alpha=None,
disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None,
ignore_patterns=[], preemption_mode=None, served_model_name=None,
qlora_adapter_name_or_path=None, otlp_traces_endpoint=None,
collect_detailed_traces=None, disable_async_output_proc=False,
scheduling_policy='fcfs', scheduler_cls='vllm.core.scheduler.Scheduler',
override_neuron_config=None,
override_pooler_config=None, compilation_config=None,
kv_transfer_config=None, worker_cls='auto',
generation_config=None, override_generation_config=None,
enable_sleep_mode=False, calculate_kv_scales=False,
additional_config=None, disable_log_requests=False,
max_log_len=None, disable_fastapi_docs=False,
enable_prompt_tokens_details=False,
dispatch_function=<function ServeSubcommand.cmd at 0x7f0796bb02c0>)

{kind=link}
{kind=link}
{kind=link}
One thought on “用vllm 0.7.3 + QWQ32B Q4量化版本功能、性能测试”
据一个朋友说,他们公司用vllm踩过很多坑,包括:
1. 没配异步日志:导致高并发时API的响应速度飙升。
2. 忽略GPU型号统一:导致推理速度波动50%
等等