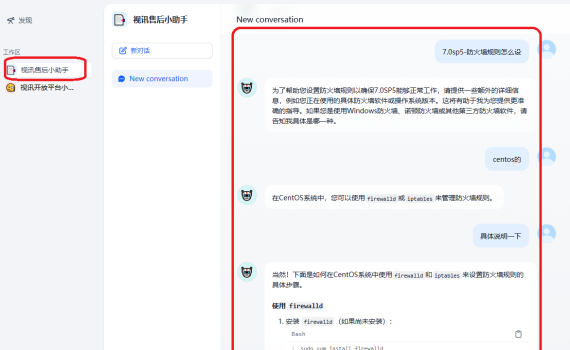
今天的这个测试是因为上周用Open WebUI搭了一个简易的知识库(具体看我上周发的那篇文章),然后产品感兴趣了,再来用Dify这个相对企业级、产品级的系统来正式搭一个企业知识问答系统而做的测试。由于需求是从LLM大模型、Embedding模型、Rerank模型,以有Dify平台全套都必须是私有化部署,且不能使用Docker,全部是手动代码部署,因此,整个过程较复杂,也走了一些弯路,所以整个内容篇幅较长。为省流,直接上结论。 一、省流:关键结论速览 结论 需注意的是,Open WebUI 和 Dify 目前所使用的 embedding 模型不同,这是造成测试结果存在差异的一个重要因素。 测试体验环境 二、现状与挑战:Open WebUI 知识库的局限 前期,我们基于 Open WebUI 搭建了一个简易的知识库。但由于 Open WebUI 并非专业用于知识问答的平台,其功能较为简陋,难以满足企业级产品的知识问答需求: 针对以上种种问题,经过与两位领导的初步讨论,我们启动了对 Dify 的预研工作,期望借助 Dify 的工作流机制来解决 Open WebUI 知识库存在的这些问题。 三、Dify 的解决方案:灵活性与强大功能的结合 Dify 的强大之处在于其高度的灵活性,主要体现在智能体和工作流两个方面: 四、Dify 部署之路:挑战与进展并存 在对 Dify 的优势进行充分了解后,我们来看看当前的部署进展情况。目前,Dify 的演示环境已经搭建完成,但在使用和优化方面仍有许多工作需要进一步探索。 整个部署过程并非一帆风顺。由于没有实体服务器,我们在 AutoDL 上租用了一台虚拟机进行部署。但由于 AutoDL 虚拟机存在诸多限制,导致我们遇到了不少问题: 因此,目前我们的部署是分布在几台不同的设备上: 通过一系列的配置工作,我们实现了这几台设备之间的互联互通。 五、Dify 平台的实战测试:与 Open […]
LLM
一、前言 听说KTransformers 0.2.4支持并发了,这可是个大进步,之前测试下来KTranformers最大的期待就是AMX指令加速和支持并发。 现在可以支持并发了,是否意味着KT终于不再是一个玩具,有可能朝产品化的方向去走了,因此上手体验一下看看。 省流,直接看结论:这个版本的方案下,依然没有看到传说中的新版XEON CPU的amx指令加速带来的飞跃,并发依然不行(能并发,但体验无法忍受),个人玩玩,研究一下技术可以,但无法产品化、商业化使用。 有兴趣复现的可以照我这个步骤来走,基本不会有问题。 二、软硬件环境 1. 软硬件环境 还是原来的环境。租的AutoDL的GPU服务器做的测试 2. 虚拟环境 我图省事,就直接复用了之前的v0.2.3的虚拟环境:/root/autodl-tmp/jacky/envs/kt0.2.3 重头开始的朋友可以重新创建一个新的虚拟环境,步骤如下 三、开工 测试使用: 1. 下载KT代码 给挂个加速器https://ghfast.top/ ,避免下载代码失败。 2. 同步子模块 先改下子模块的代码仓库路径,同样给加下加速。 所有子模块地址给挂个加速 然后下载子模块代码 注: 这一步要注意,v0.2.4引入了一些新的子模块,并且这些子模块又有子模块,这样会导致下载子模块会失败,从而导致下面的:编译完有一个报错:ERROR: Directory ‘third_party/custom_flashinfer/’ is not installable 这个错误,这个现在在墙内没办法,只能跑两遍(有多少层递归就要跑多少遍),然后每一层的代码用ghfast.top加速下载成功后,再去改那一层的.gitmodules里的每个子模块的仓库地址,然后再跑。 3. 安装依赖 4. 编译KTransformers v0.2.4 1) 修改./install.sh, vi install.sh 加入: 2)编译 如果你有1T内存,可以 USE_NUMA=1(# For those who […]

Open-WebUI+QwQ-32B搭建本地知识库 一、概述 当用户提出一个问题时,如何让大模型准确的定位到你的输入背后真的正的问题,并输出正确的回复,是大模型应用的关键。 而要达到此目的,主要有三种方式:提示词、知识库和微调。 大模型的搭建,open-webui及RAG的启用等步骤暂先跳过,本文主要介绍并演示了本地知识库的一些关键点。 二、背景 前阵子,应产品部门的要求,对Deepseek R1 671B及QwQ-32B等大模型做了一番技术上的预研。由于前期的测试中发现,在硬件受限(单卡或双卡4090)环境下,QwQ-32B-AWQ模型的表现在并发、速度等多方向优于Deepseek满血版,并且二者在会议纪要等功能的对比测试各有优劣,因此知识库的预研和测试也优先选择了QwQ-32B-AWQ模型。 而前端平台则采用了开源的open-webui,同时RAG采用了open-webui自带的“sentence-transformers/all-MiniLM-L6-v2”向量模型。 平台 模型 备注 前端平台 Open-webui搭建的框架 github中开源项目,支持rag、对接ollama等功能 后端大模型 QwQ-32B-AWQ 自行部署的大模型,使用AutoDL上租借的服务器 向量模型 sentence-transformers/all-MiniLM-L6-v2 open-webui自带的向量库 三、影响本地知识库及响应质量的关键点 在明确了大模型(QwQ-32B-AWQ)和向量库(sentence-transformers/all-MiniLM-L6-v2)后,整个RAG应用的开发关键在于本地知识的整理和提示词的设计,在open-webui上可以看到相关的一些设定。 1. top k Top-k 采样是自回归生成(autoregressive generation)“贪心策略”的优化。原理是从概率排名最高的K个单词里随机采样。很多情况下这个随机性有助于提高生成质量。默认为前3。 2. 提示词 open-webui给出了一个样例的提示词。 这个提示词本身已经经过了许多人的检验,理论上讲应该适用于大部分的场景,但暂未在公司的使用场景下做严格测试和验证。未来我们可以在使用中观察一下,并根据实际的请求与响应来做一下各种必要的调试或调整。 3. 块参数(Chunk Params) 包括: 向量化参数块大小和块重叠的设置,这直接影响了rag检索的效果。推荐:块大小1000,块重叠为块大小的5%-10%,若发现知识丢失,可适当增加块重叠的值。 四、创建和使用知识库 创建知识库 知识库的创建步骤,如上图所示: 知识库使用介绍 知识库创建好了之后,到了主界面,在输入框里输入一下 #,你就可以看到所有你具体访问权限的知识库列表,选定你要问的知识库后,再在输入框里输入你的问题,即可针对知识库来进行问答。 五、演示环境 目前我在演示环境建了三个知识库,视讯开放平台,新员工入职培训,视讯平台API。 大家可以实际体验一下效果和准确率。 地址:http://172.16.129.127:3000 测试账号: […]

一、省流,直接看结论 一)参数:两个4090,1000 token的输入,128 token的输出(vllm benchmark默认值) 1. benchmark最高并发请求:60+ 参数:两个4090,1000 token的输入,128 token的输出(vllm benchmark默认值) 2.启用FlashInfer前后对比 启用FlashInfer比默认的PyTorch-native模式的性能提升差不多。 client端统计对比 server端统计对比 用pyplot针对这3次测试跑的3个日志文件生成了一个图。 3.结论 测试1000个请求, 三轮跑下来, 不启用flashinfer总耗时稍长一点点(差10来秒, 459 vs 449).启用flashinfer: 并发请求可达到60左右,但是受限于硬件/GPU, 首字出字速度, 单位输出token时延等数据都会延长。每秒输出的总token数1=125604/448.73=27.99 tps每秒输出的总token数2=125600/449.52=27.32 tps不启用flashinfer: 并发请求在40左右, 但首字出字速度, 单位输出 token时延都会较短.每秒输出的总token数=125604/459.73=27.32 tps 关于flashinfer:从测试结果来看,启用后并没有将这1000个请求的总耗时降下来多少,因此最终还是会受限于硬件/GPU? 二)参数:两个4090,1000 token的输入,1000 token的输出(会议摘要常规输出) 1.benchmark最高并发请求:约40~50左右 2.启用FlashInfer后数据 合并到上面的表格,具体看FlashInfer3一列数据 3.结论 指定输出token数量从128到1000,对最大并发有影响,全影响不是非常大。每秒输出的总token数=967760/1423.79=67.9 tps。这一段测试是在5点后,快下班时间跑的 二、测试硬件环境 •软件环境:PyTorch 2.6.0、Python 3.12(ubuntu22.04)、Cuda 12.4•硬件环境:○GPU:RTX 4090(24GB) * […]
一开始报没安装FlashInfer 启动vllm过程中有一个warning。 那就安装一下FlashInfer 从这个代码上看,应该只要不是0.2.3就可以了。 卸载flashinfer-python 安装一个老一点的0.2.2 重新启动server 终于启用了flashinfer! 但是依旧报警告:TORCH_CUDA_ARCH_LIST is not set 指定TORCH_CUDA_ARCH_LIST为8.9 我用的是4090,所以TORCH_CUDA_ARCH_LIST应该是8.9 重新启动server 成功!
一、导言 ***牵头组织了一个会议,对Deepseek在视讯方案的可能性进行了一番讨论,讨论后的结论是对Deepseek先做一番技术上的预研,然后再上产品路标。后来**和**也针对此事做了一些交待。再后来就是撸起袖子了。 二、预研目标 《Deepseek在视讯方案的可能性》:一句话表示:在消费级的GPU上跑满血版Deepseek R11、GPU:结合公司的实际情况(还躺在米国政府的黑名单上),预研所针对的硬件必须是我们有可能买得到的硬件。2、Deepseek R1满血版:预研初期确定的目标是满血版Deepseek R1 671B(实际测下来发现可能存在一些问题) 三、预研情况说明 在曾哥租到GPU服务器之后,有了硬件资源后,主要利用这个GPU服务器做了以下几部分预研。一是包括Deepseek/QwQ32-B/Gemma3等等在内的大模型安装、部署与测试。二是有了大模型之后,视讯这边可能的一些应用,包括:Chat API, Agent等。三是与KIS做了一些集成测试。四是视讯智能产品KIS相关的一些周边技术,包括:ASR, TTS等。 一)预研设定的环境 1. 软件环境 PyTorch 2.5.1Python 3.12(ubuntu22.04)Cuda 12.4 2. 硬件环境 ○GPU:RTX 4090(24GB) * 2○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430○内存:480G(至少需要382G)○硬盘:1.8T(实际使用需要380G左右) 参考:京东上GPU 4090 x2+CPU 6330 +内存64G+硬盘2T报价约为:69500。https://item.jd.com/10106874216614.html 二)大模型测试 直接上结论。 测试结果 大模型 框架 max_new_tokens context GPU数量 TPS(单连接) TPS(多连接) ds-r1-671b Q4 KT 8192 […]
用Ollama 对 Gemma3多模态27B版本做功能、性能测试 谷歌刚刚推出的开放权重LLM:Gemma 3。它有四种大小,10亿、40亿、120亿和270亿个参数,有基础(预训练)和指令调优版本。Gemma 3 MultiModel人如其名,支持多模式!40亿、12亿和270亿参数模型可以处理图像和文本,而1B变体仅处理文本。 今天咱来试试看。 一、硬件环境 租的AutoDL的GPU服务器做的测试 •软件环境 PyTorch 2.5.1、Python 3.12(ubuntu22.04)、Cuda 12.1 •硬件环境 ○GPU:RTX 4090(24GB) * 2 ○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430 ○内存:480G(至少需要382G) ○硬盘:1.8T(实际使用需要380G左右) 二、虚拟环境及vllm安装 默认认为你已经安装好了conda,如果还没安装的话,先搜索一下conda安装 三、安装Day0 transformers Gemma3依赖一些Google新提供的transformers的接口,因此必须先更新一下transformers。 建议走一下github加速器:ghfast.top 四、模型下载 export HF_HOME=”/root/autodl-tmp/HF_download” setproxy.py代码: 执行 python setproxy.py 设置代理环境变量 然后再下载: 共16个G多一点。慢慢来。 五、模型运行 用ollama来运行gemma3 运行前请确保ollama服务已启动,若未启动的话,请在另一个命令行中先启动一下: ollama serve 若ollama后台服务已经启动,则可以开始加载运行gemma3了 […]
问题现象 在Open WebUI里上传一个附件,然后针对这个附件做聊天或者问答,但是返回异常。 查看后台日志,有如下报错: 问题分析 从后台的错误上看应该是save_docs_to_vector_db的embedding_functionb出错了。再具体看了一下代码应该是没的安装语义向量模型引擎sentence-transformers导致的。 解决方案 切回到前台的Open WebUI,用管理员身份登录进去。然后点右上角的“设置”,并找到“文档”,然后在该界面上点一下右这的下载的图标,如下图所示。 若下载成功了,应该就OK了。不过,实际上我这边的情况是下载失败。所以同志还要努力。继续往下走。 文档设置中下载sentence-transformers/all-MiniLM-L6-v2失败 查看后台日志,发现报错如下 从这个报错来看,应该是open_webui/retrieval/utils.py的get_model_path()在调用snapshot_download()连不上huggingface导致的。因此,我们需要再设置一下代码,翻个墙,或者设置一下huggingface的镜像站。 后台关了Open WebUI,然后设置一下代理及huggingface镜像。 设置代理 设置huggingface镜像export HF_ENDPOINT=https://hf-mirror.com 重启 Open WebUI ./start.sh 后再chat with 附件,一切正常。 以下是我的start.sh的代码:
同之前的Open WebUI联网搜索功能异常问题一样,一样步骤很简单。 下载STT模型 先得启用一下Open WebUI的STT(Speech To Text)语音转文本的功能,用管理员登录进去,然后点OpenWebUI的右上角Admin Panel(管理面板)设置,再到Setting的Audio设置项,如下图所示,先在STT Model那里填一个wisper模型名,如:base(截图的时候忘记填了),然后点击一下那个下载按钮。 若是点了后没任何响应,看下后台的日志,如果碰到诸如此类的报错: 那我只能说,你没有任何错,只是错在你身处的这个网络(需要科学上网)在服务器上,执行下面的命令设置一下huggingface的镜像站,然后再重新下载一下。 若是还是没有任何响应,确认一下STT Model那里的wisper模型名有没有填,有填的话填的对不对。 解决http地址无法访问麦克风问题 http网页默认情况下是不允许开麦克风和摄像头的,但是如果是为了测试功能,我们可以通过如下步骤在chrome里来给打开 然后在Insecure origins treated as secure里将默认的Disabled改成Enabled,并将你要访问的地址填一下到里边(可以多个)。填完后会提示你重启浏览器生效。重启后你就可以在这个地址开麦克风、摄像头了。 解决了http无法开麦克风问题后,到Open WebUI就可以录音频的方式去问问题了。
问题现象 大模型的联网搜索功能本质上是将模型的自然语言处理能力与传统搜索引擎技术相结合,实现获取联网信息并生成可靠答案的能力。但是在Open WebUI默认安装下该功能是不可用的,需要你自己来配置一下。 设置Open WebUI 在Open WebUI前端,用管理员账号登录进去,然后点右上角的设置,然后找到“联网搜索”将联网搜索功能启用一下,然后将你自己的密钥及账号信息填进去即可。 建议选择用Goole的PSE(Programmable Search Engine),因为我试着去注册了几个搜索引擎,同样是有free trial,只有Google的这个没让我绑定信用卡。 以Google PSE为例从头申请一个Google PSE的API。 然后把这个API密钥和搜索引擎ID填到Open WebUI的设置项中,保存并刷新Open WebUI,然后联网搜索就可以工作了。 注意事项 一、免费版的Google PSE的每天有使用限制(点开你创建的自定义搜索引擎后,在那里会显示),当前的限制是每次1万次。二、要使用Google PSE就意味着你的服务器是支持科学上网的,不然连不上Google一切白扯。