[TOC]
Ktransformer+Deepseek R1 671B实操
一、测试目标
验证并确认Ktransformer+Deepseek R1 671B的效果是否能满足公司的需求,并得出最终的硬件要求,以最终自行购置一台服务器来跑Deepseek R1 671B.
二、目标硬件要求
根据网上的测评,拿到一个硬件要求如下:
•软件环境:
PyTorch 2.5.1、Python 3.12(ubuntu22.04)、Cuda 12.4
•硬件环境:
○GPU:RTX 4090(24GB) * 4(实际只使用一张GPU)
○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430
○内存:480G(至少需要382G)
○硬盘:1.8T(实际使用需要380G左右)
三、GPU服务器租用-选AutoDL
阿里云、腾讯云、百度云、华为云这些都有GPU服务器,但是他们的GPU都是企业级的GPU,而我们最终的目标是自建,所以只能选消费级的GPU来测试。
因此首选AutoDL,但是他的服务器白天基本上一直忙,早上一大早就需要去抢才能抢到,单台服务器的内存最高120,购置4台可满足要求,其中一台硬盘要可扩到至少600G。
四、服务器环境
python版本
python --version返回
Python 3.12.3
CUDA版本
nvcc --version返回
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
torch版本
python -c "import torch; print(torch.__version__)"返回
2.6.0+cu124
CUDA 架构列表
命令
python -c "import torch; print(torch.cuda.get_arch_list())"返回
['sm_50', 'sm_60', 'sm_70', 'sm_75', 'sm_80', 'sm_86', 'sm_90']命令
nvcc --list-gpu-arch返回
compute_50
compute_52
compute_53
compute_60
compute_61
compute_62
compute_70
compute_72
compute_75
compute_80
compute_86
compute_87
compute_89
compute_90五、ktransformers安装
环境依赖安装
安装gcc、cmake等
sudo apt-get update
sudo apt-get install gcc g++ cmake ninja-build software-properties-common
安装torch、ninja等
pip install torch packaging ninja cpufeature numpy
安装flash-attn
pip install flash-attn
手动安装libstdc
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install –only-upgrade libstdc++6
conda install -c conda-forge libstdcxx-ng
六、【失败】功能测试方案一:使用ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
下载whl
wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
安装
命令
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
报错
Looking in indexes: http://mirrors.aliyun.com/pypi/simple
ERROR: ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl is not a supported wheel on this platform.
创建一个新的python3.11的环境,重来
conda create –prefix=/root/autodl-tmp/jacky/ds python==3.11
conda activate /root/autodl-tmp/jacky/ds
pip install torch packaging ninja cpufeature numpy
pip install flash-attn
conda install -c conda-forge libstdcxx-ng
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
失败
七、【OK】功能测试方案二:下载代码编译
下载代码
git clone https://ghfast.top/https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
编译
修改.gitmodules
vi .gitmodules
给各个子模块的地址加一下github加速
[submodule “third_party/llama.cpp”]
active = true
url = https://ghfast.top/https://github.com/ggerganov/llama.cpp.git
[submodule “third_party/pybind11”]
active = true
url = https://ghfast.top/https://github.com/pybind/pybind11.git
拉取子模块代码
git submodule init
git submodule update
切换指定版本
git checkout 7a19f3b
git rev-parse –short HEAD # 应显示 7a19f3b
创建一个新的conda env
conda create –prefix=/root/autodl-tmp/jacky/ds2
conda activate /root/autodl-tmp/jacky/ds2
安装python依赖
pip install torch packaging ninja cpufeature numpy
pip install flash-attn
pip install flashinfer-python
export TORCH_CUDA_ARCH_LIST=”8.9″
pip install -r requirements-local_chat.txt
pip install setuptools wheel packaging
编译
如果拥有充足的CPU核心和内存资源,可显著提升构建速度,修改./install.sh,加入:
export MAX_JOBS=64
export CMAKE_BUILD_PARALLEL_LEVEL=64编译
sh ./install.sh启动命令行聊天
export TORCH_CUDA_ARCH_LIST=”8.9″
python ./ktransformers/local_chat.py –model_path /root/autodl-tmp/DeepSeek-R1 –gguf_path /root/autodl-tmp/DeepSeek-R1-GGUF –cpu_infer 64 –max_new_tokens 1000 –force_think true | tee runlog1.log
启动本地聊天API端点
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python3 ktransformers/server/main.py \
–gguf_path /root/autodl-tmp/DeepSeek-R1-GGUF/ \
–model_path /root/autodl-tmp/DeepSeek-R1 \
–cpu_infer 64 \
–max_new_tokens 8192 \
–cache_lens 32768 \
–total_context 32768 \
–cache_q4 true \
–temperature 0.6 \
–top_p 0.95 \
–optimize_config_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat.yaml \
–force_think \
–use_cuda_graph \
–host 127.0.0.1 \
–port 12344
按需修改参数,使用
--help查看帮助文档
支持多GPU配置及通过--optimize_config_path进行更细粒度的显存卸载设置
python3 ktransformers/server/main.py --help
2025-03-03 15:36:32,720 - INFO - flashinfer.jit: Prebuilt kernels not found, using JIT backend
found flashinfer
usage: kvcache.ai [-h] [--host HOST] [--port PORT] [--api_key API_KEY] [--ssl_keyfile SSL_KEYFILE] [--ssl_certfile SSL_CERTFILE] [--web WEB] [--model_name MODEL_NAME] [--model_dir MODEL_DIR] [--model_path MODEL_PATH] [--device DEVICE] [--gguf_path GGUF_PATH]
[--optimize_config_path OPTIMIZE_CONFIG_PATH] [--cpu_infer CPU_INFER] [--type TYPE] [--paged PAGED] [--total_context TOTAL_CONTEXT] [--max_batch_size MAX_BATCH_SIZE] [--max_chunk_size MAX_CHUNK_SIZE] [--max_new_tokens MAX_NEW_TOKENS]
[--json_mode JSON_MODE] [--healing HEALING] [--ban_strings BAN_STRINGS] [--gpu_split GPU_SPLIT] [--length LENGTH] [--rope_scale ROPE_SCALE] [--rope_alpha ROPE_ALPHA] [--no_flash_attn NO_FLASH_ATTN] [--low_mem LOW_MEM]
[--experts_per_token EXPERTS_PER_TOKEN] [--load_q4 LOAD_Q4] [--fast_safetensors FAST_SAFETENSORS] [--draft_model_dir DRAFT_MODEL_DIR] [--no_draft_scale NO_DRAFT_SCALE] [--modes MODES] [--mode MODE] [--username USERNAME] [--botname BOTNAME]
[--system_prompt SYSTEM_PROMPT] [--temperature TEMPERATURE] [--smoothing_factor SMOOTHING_FACTOR] [--dynamic_temperature DYNAMIC_TEMPERATURE] [--top_k TOP_K] [--top_p TOP_P] [--top_a TOP_A] [--skew SKEW] [--typical TYPICAL]
[--repetition_penalty REPETITION_PENALTY] [--frequency_penalty FREQUENCY_PENALTY] [--presence_penalty PRESENCE_PENALTY] [--max_response_tokens MAX_RESPONSE_TOKENS] [--response_chunk RESPONSE_CHUNK] [--no_code_formatting NO_CODE_FORMATTING]
[--cache_8bit CACHE_8BIT] [--cache_q4 CACHE_Q4] [--ngram_decoding NGRAM_DECODING] [--print_timings PRINT_TIMINGS] [--amnesia AMNESIA] [--batch_size BATCH_SIZE] [--cache_lens CACHE_LENS] [--log_dir LOG_DIR] [--log_file LOG_FILE]
[--log_level LOG_LEVEL] [--backup_count BACKUP_COUNT] [--db_type DB_TYPE] [--db_host DB_HOST] [--db_port DB_PORT] [--db_name DB_NAME] [--db_pool_size DB_POOL_SIZE] [--db_database DB_DATABASE] [--user_secret_key USER_SECRET_KEY]
[--user_algorithm USER_ALGORITHM] [--force_think | --no-force_think] [--use_cuda_graph | --no-use_cuda_graph] [--web_cross_domain WEB_CROSS_DOMAIN] [--file_upload_dir FILE_UPLOAD_DIR] [--assistant_store_dir ASSISTANT_STORE_DIR]
[--prompt_file PROMPT_FILE]
Ktransformers
options:
-h, --help show this help message and exit
--host HOST
--port PORT
--api_key API_KEY
--ssl_keyfile SSL_KEYFILE
--ssl_certfile SSL_CERTFILE
--web WEB
--model_name MODEL_NAME
--model_dir MODEL_DIR
--model_path MODEL_PATH
--device DEVICE Warning: Abandoning this parameter
--gguf_path GGUF_PATH
--optimize_config_path OPTIMIZE_CONFIG_PATH
--cpu_infer CPU_INFER
--type TYPE
--paged PAGED
--total_context TOTAL_CONTEXT
--max_batch_size MAX_BATCH_SIZE
--max_chunk_size MAX_CHUNK_SIZE
--max_new_tokens MAX_NEW_TOKENS
--json_mode JSON_MODE
--healing HEALING
--ban_strings BAN_STRINGS
--gpu_split GPU_SPLIT
--length LENGTH
--rope_scale ROPE_SCALE
--rope_alpha ROPE_ALPHA
--no_flash_attn NO_FLASH_ATTN
--low_mem LOW_MEM
--experts_per_token EXPERTS_PER_TOKEN
--load_q4 LOAD_Q4
--fast_safetensors FAST_SAFETENSORS
--draft_model_dir DRAFT_MODEL_DIR
--no_draft_scale NO_DRAFT_SCALE
--modes MODES
--mode MODE
--username USERNAME
--botname BOTNAME
--system_prompt SYSTEM_PROMPT
--temperature TEMPERATURE
--smoothing_factor SMOOTHING_FACTOR
--dynamic_temperature DYNAMIC_TEMPERATURE
--top_k TOP_K
--top_p TOP_P
--top_a TOP_A
--skew SKEW
--typical TYPICAL
--repetition_penalty REPETITION_PENALTY
--frequency_penalty FREQUENCY_PENALTY
--presence_penalty PRESENCE_PENALTY
--max_response_tokens MAX_RESPONSE_TOKENS
--response_chunk RESPONSE_CHUNK
--no_code_formatting NO_CODE_FORMATTING
--cache_8bit CACHE_8BIT
--cache_q4 CACHE_Q4
--ngram_decoding NGRAM_DECODING
--print_timings PRINT_TIMINGS
--amnesia AMNESIA
--batch_size BATCH_SIZE
--cache_lens CACHE_LENS
--log_dir LOG_DIR
--log_file LOG_FILE
--log_level LOG_LEVEL
--backup_count BACKUP_COUNT
--db_type DB_TYPE
--db_host DB_HOST
--db_port DB_PORT
--db_name DB_NAME
--db_pool_size DB_POOL_SIZE
--db_database DB_DATABASE
--user_secret_key USER_SECRET_KEY
--user_algorithm USER_ALGORITHM
--force_think, --no-force_think
--use_cuda_graph, --no-use_cuda_graph
--web_cross_domain WEB_CROSS_DOMAIN
--file_upload_dir FILE_UPLOAD_DIR
--assistant_store_dir ASSISTANT_STORE_DIR
--prompt_file PROMPT_FILE设置ssh端口转发API
ssh -CNg -L 12344:127.0.0.1:12344 root@connect.nmb1.seetacloud.com -p 22305
安装webui
安装
pip install open-webui
启动脚本
#!/usr/bin/env bash
# open-webui 不原生支持HOST和PORT环境变量,需手动传递参数
# https://docs.openwebui.com/getting-started/env-configuration/#port
# 若open-webui运行异常,可执行`rm -rf ./data`清除数据后重启服务并清理浏览器缓存
# https://docs.openwebui.com/getting-started/env-configuration/
export DATA_DIR="$(pwd)/data"
export ENABLE_OLLAMA_API=False
export ENABLE_OPENAI_API=True
export OPENAI_API_KEY="dont_change_this_cuz_openai_is_the_mcdonalds_of_ai"
export OPENAI_API_BASE_URL="http://127.0.0.1:8080/v1" # <--- 需与ktransformers/llama.cpp的API配置匹配
#export DEFAULT_MODELS="openai/foo/bar" # <--- 保留注释,此参数用于`litellm`接入
export WEBUI_AUTH=False
export DEFAULT_USER_ROLE="admin"
export HOST=127.0.0.1
export PORT=3000 # <--- open-webui网页服务端口
# 如果仅加载了R1模型,可通过禁用以下功能节省时间:
# * 标签生成
# * 自动补全
# * 标题生成
# https://github.com/kvcache-ai/ktransformers/issues/618#issuecomment-2681381587
export ENABLE_TAGS_GENERATION=False
export ENABLE_AUTOCOMPLETE_GENERATION=False
# 或许目前需手动在界面禁用该功能???
export TITLE_GENERATION_PROMPT_TEMPLATE=""
open-webui serve \
--host $HOST \
--port $PORT
# 在浏览器中访问显示的URL:端口设置ssh端口转发webui
ssh -CNg -L 3000:127.0.0.1:3000 root@connect.nmb1.seetacloud.com -p 22305
八、测试
功能测试
浏览器打开转发端口的网页:http://127.0.0.1:3000, 网页打开成功。
问题:找不到模型
问题现象
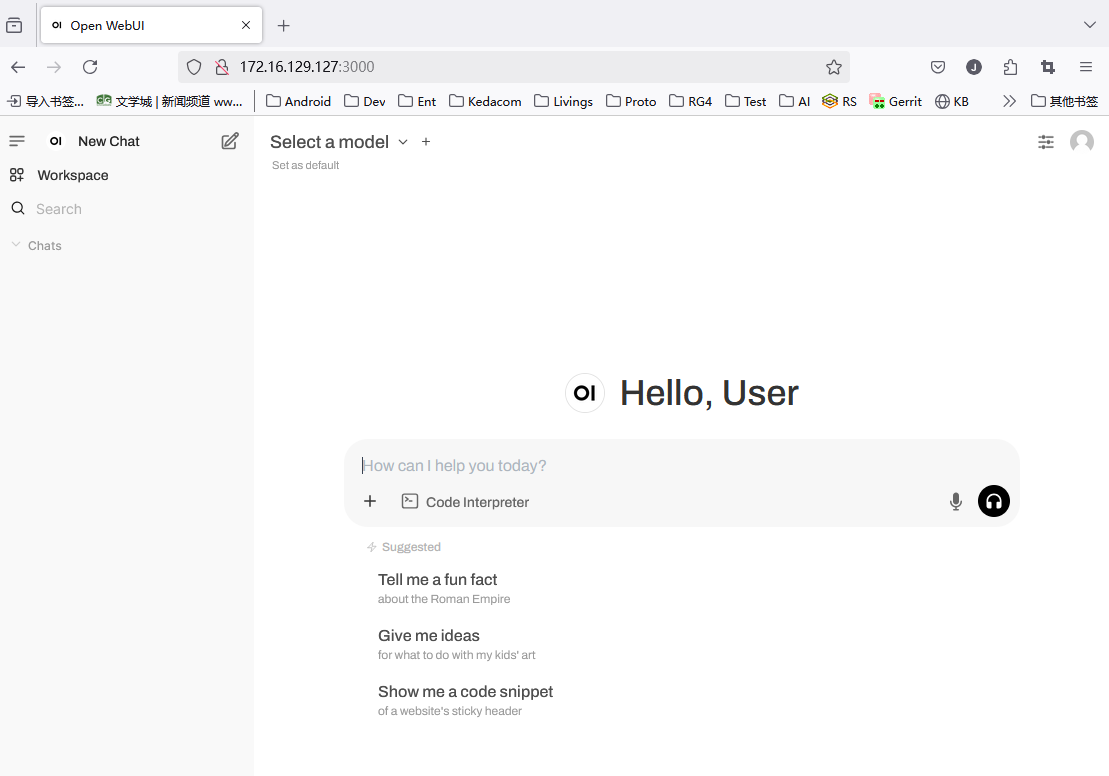
但是无法使用,提示需要先选择模型。
查看open-webui日志,发现有警告:
INFO: 127.0.0.1:49044 - "GET /api/v1/users/user/settings HTTP/1.1" 200 OK
INFO [open_webui.routers.openai] get_all_models()
ERROR [open_webui.routers.openai] Connection error: Cannot connect to host 127.0.0.1:8080 ssl:default [Connect call failed ('127.0.0.1', 8080)]
INFO: 127.0.0.1:49030 - "GET /api/models HTTP/1.1" 200 OK
INFO: 127.0.0.1:49030 - "GET /api/v1/configs/banners HTTP/1.1" 200 OK解决方案
调整open-webui启动脚本,将其中的8080端口改成12344,再启动open-webui测试,界面正常,输入输出正常
问题:模型名字不对
问题现象
但是显示的模型名字是DeepSeek-Coder-V2-Instruct,这个不对。
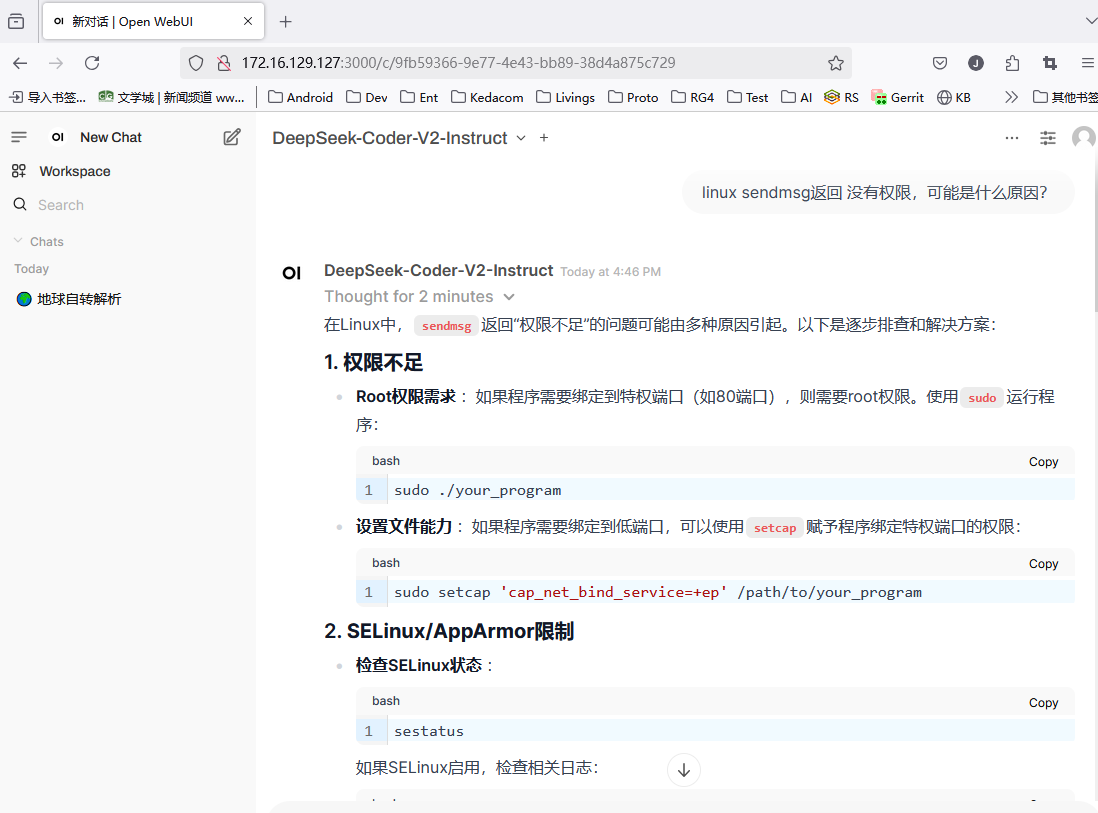
解决方案
- 在启动脚本里指定
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python3 ktransformers/server/main.py \
--gguf_path /root/autodl-tmp/DeepSeek-R1-GGUF/ \
--model_path /root/autodl-tmp/DeepSeek-R1 \
--model_name deepseek.r1.671b \
--cpu_infer 64 \
--max_new_tokens 8192 \
--cache_lens 32768 \
--total_context 32768 \
--cache_q4 true \
--temperature 0.6 \
--top_p 0.95 \
--optimize_config_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat.yaml \
--force_think \
--use_cuda_graph \
--host 127.0.0.1 \
--port 12344- 修改配置文件
install完了之后:
vim ~/.ktransformers/config.yaml
手动改名字
性能优化测试
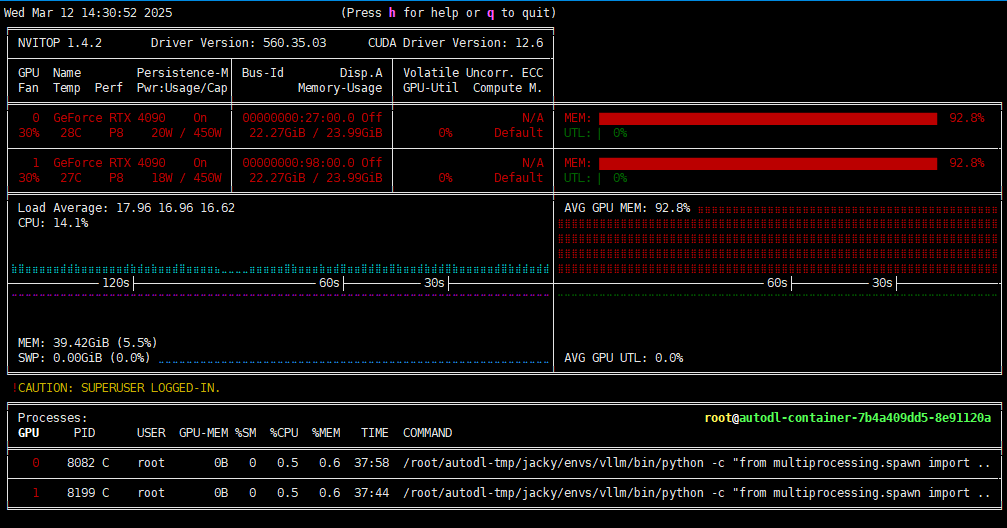
查看实时GPU/CPU/MEM
pip install nvitop
nvitop
当前性能情况
当前参数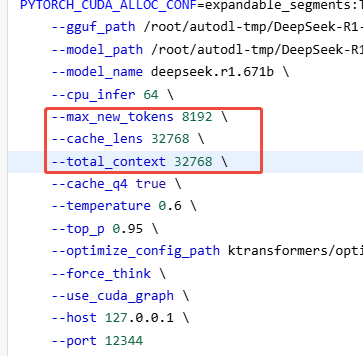
CPU、GPU使用率情况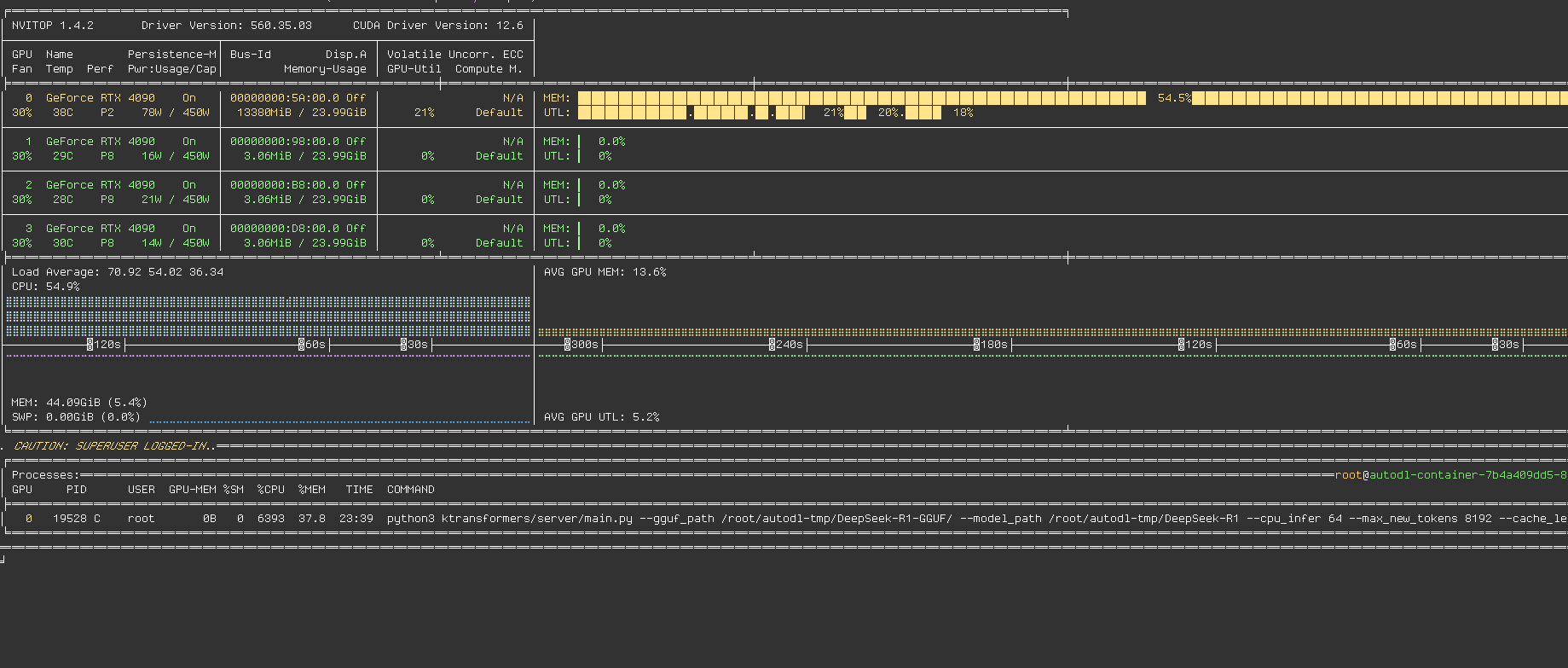
token数情况
未统计,但使用下来跟在网页上访问deepseek官网的体感差不多。
尝试调整方向
上下文context、max tokens等参数调整对输出的影响?
初步调了一下,上下文32k改64k,max tokens从8k改16k,没看出来什么影响,具体待评估
cpu_infer参数越小,是否可以提高tps?
猜想,理论上讲cpu_infer越小就相不于把更多的事情放到gpu去做,在GPU够的情况下,应该是会有改善的。
明天试下改成16或者32看看效果。
NUMA参数设置
今天搞了三个版本,不确定最后一个版本里是否有将NUMA环境变量设置上,也不知道如何来确认当前运行版本是什么样的。明天再创建一个新环境再从头来一遍。
内存的类型
瓶颈可能在内存 不是ddr5
改用0.3版本
ktransformers到0.3之后才支持amx指令加速,当前版本应该是0.2.2没开启
多块GPU并行使用
目前只用了一块GPU

{kind=link}
{kind=link}
{kind=link}
{kind=link}