
首先,这篇7.5万字的文章我读了三遍(昨天下午第一遍看,第二遍是今天上班在地铁上听的,然后今天下班回家后又看了一遍)。 我认为的金句 看完后最大的感想是作者的复盘写的的确很深入,个人认为最大的一句金句就是:“产品最大的浪费不是偷懒,是全力以赴地做错事”。 必须要强调的是她这句话,我无比的认同,虽然后面可能会有一些但是,凡事总归需要个但是。 先说一下我自己 我自己也有一个经常性、阶段性复盘的习惯,但是我的复盘没有听众,只有我自己(只留在我自己的知识库,没有给任何人看过),唯二例外的是去年的两次复盘,一次是关于公司产品效率的吐槽,另一次则是入职十二年的一个总结,但也只发给过我的直属领导一个人。 无招要求的是一天一包,是敏捷到了极致。我们公司相比于阿里是一个小公司,我吐槽的都只是组织架构、决策路径上问题,是毫无敏捷可言的问题,我们的问题是过于臃肿,由于分工细,一旦牵涉多个部门、团队,基本上啥事都动不了。 我个人性子比较急,如果事情推不动我会很焦虑,今天要做的事情,如果明天还没做好,我会饭不香睡不着。多年来一直在用我自己的方式去处理:一个需要我做但会涉及其他团队的功能,如果别的团队忙,没时间来做,那就我自己来做。 在早些年公司的一些大功能迭代的时候都是这么一个路子(比如:早些年公司第一代的量子加密会议、32位转64位、IPv4转IPv6等等),更有甚之的则是几年前的公司第一代智能产品。 我的态度一言概之就是:你们都很忙,那好,全部我自己来搞定。纯粹一介草蛮。 可能当时我也压迫的下面的兄弟们,但是自认为我向下管理还是可以的(向上管理则是完全相反),因为所有离开了的兄弟们跟我都还一直有联系,哪怕只是过年过节问候一下。” 写本文的目的 最后,这篇文章的主要目的不是想继续我自己的吐槽,是为了给大家推荐阅读一下《置身钉内》,一篇直接让CEO下台的小作文,让一个极具战斗力的、能破局的人黯然出局的小作文。 个人观点 但是,当看到网上的人几乎全是骂无招的,甚至还传闻钉钉一堆人放烟花的时候,个人感觉都有点过了。 个人观点1:关于作者 个人感觉作者的叙事方式也是存在一些问题的(个人观点哈,不喜可喷)。 因为我相信这个ONE项目可能会存在的问题,在项目初期必然是考虑过后面可能会出现的各种场景: 我一个普通牛马都能想到的一些简单推演,像阿里、钉钉这种大厂在做一个大项目的时候,决无可能在项目初期没有考虑过这些可能的场景。 但是该文的作者在这篇小作文里的叙事感觉就完全是以爽文的方式来演进,一开始抬高大家对ONE项目的预期,后面完全反转,并且把无数打工人抵抗的996、内卷、加班文化将这个项目的成败放在一起,自然就一下子让绝大多数人爽了。 所以,幽素同学的文采不得不西服,与此同时,一点感想,千万不要得罪文科生(据说哈,我也不知道她是不是文科生)。 个人观点2:关于无招 你可以不认同他的行事方式,你可以对这个产品的结果吐口水,但是你不能不认同他想做事、想做成事的信心、决心和勇气,并可以为之全力以赴的行动力、执行力。” 但是经过这一摊子沸沸扬扬的事,无招同学后面可能无法再像上一次离开钉钉再回到钉钉那样,可以轻松的东山再起了,无论是继续在阿里体系(估计以他的个性已经不可能了),还是再起第二个HHO。当然,像无招这样的、早已财务自由的大佬的事,也不是我一个牛马需要操心和担心的。 个人观点3:关于选择 一切都只在于你的抉择,选择东就会牺牲西,选择西就会牺牲东,选择付费方(老板们)必然会让使用者(打工人)厌恶,选择一家996的公司也必然会让生活上的时间被压缩。 个人观点4:客户第一,还是老板第一? 有阿里的同学说阿里的文化之一是:老板第一(与之相对应的是客户第一),有人说想笑,有什么好笑的呢?在军团作战的时代,尤其是在这个快速变化、叠加信息不对称的AI时代,老板的决策就代表了整体的作战目标,如果你有不同的看法,可以表达你的看法和意见,但是如果你的想法不能影响老板的决策,那就是老板第一,这也是普通人要想在这个时代杀出血路的不二方案。 更何况,从ONE这个产品的定位来说,实际上一个真正意义上的、变革的产品,因为它改变的是整个范式:让“人找事”,变成“事找人”。
阿里云
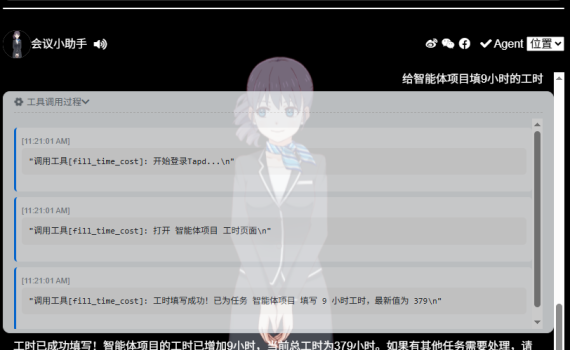
一、前言 前前后后的给小落同学加了许多的MCP。 但是这些功能之前一直在我本地的小落同学上跑,部署在阿里云ECS上的小落同学因为买的ECS配置太低(99元一年的2H2G特惠主机)跑不动,这个周末在家没事做,想想是不是干脆用frp让公网上的小落同学也可以把这些MCP也都给支持起来。 所以这个周末的任务就是:把原先一直在我本地电脑上跑的小落同学的MCP Server部署到公网,并让阿里云上的小落同学来访问和使用。 目前小落同学支持的MCP包括: 既然想了,那不管有没有人用小落同学,咱先给它配上去再说。 二、MCP Server可配置化 1. 新增ODDMCP配置 在小落同学的.env环境变量里新增mcp相关环境变量配置 2. 同步调整MCP Server和MCP Client中与MCP相关的配置 把原先固定的localhost的地址,改成从环境变量中获取。 1)代码:oddmcp_server.py 2)代码:oddmcp_client.py 3)代码:oddmcp_status_callback.py 4)oddagent 同步的时候发现几个新的MCP Server功能还没同步到小落同学上的oddagent,也顺手改了一下。 三、利用frp来做跳转 ODDMCP用了两个端口,一个是MCP Server所绑定的9600端口,另一个是每个在MCP运行过程中的一些实时进展状态回调时所使用的redis。 1. 客户端配置 代码:frpc-https.toml 杀掉并重新启动 frpc 2. 服务端口配置 客户端修改并新增了这两个端口,并且重启了frpc之后,先到ECS服务器端查看一下,端口状态是否都正常。 如果都有正常绑定了,说明frp已经可以工作了。 需要注意的是:服务绑定地址应该是 0.0.0.0:9600,而不是 127.0.0.1:9600(后者只允许本地访问)。 四、阿里云ECS配置 配置好frp后,还需要让阿里云ECS放行这两个端口。 1. 修改ECS安全组配置 打开浏览器,登录阿里云控制台,进入安全组配置,并在其中新增、放行9600和63579这两个TCP的端口。 阿里云控制台上的功能比较多,不常用的话,可能要找地址找半天。由于忘记功能名字了,搜索也不好搜索,呵呵。 为方便记录,特把安全组的链接地址也贴一下:https://ecs.console.aliyun.com/securityGroup/region/cn-shanghai 2. 放行防火墙 打开xshell,ssh登录上ECS服务器,查看是否放行 9600/tcp 如果是centos/openEuler操作系统: […]
前两天试了一下小红书开源出来的FireRedASR,整体感觉是小红书团队只是把关键的语音识别的模型开放出来了(也只开放了-L的模型),但是由于缺了一些前处理(语音VAD检测)、后处理(标点,多人语音聚类,热词等)相关的功能,普通用户拿到他们这个模型也根本没法直接拿来用,所以个人的观点是对于开源FireRedASR来说,小红书团队的诚意是不够的。 而光嘴巴说他们诚意不够是不能令人信服的,所以咱把阿里在2年多前开源出来的FunASR拿出来介绍一下,诚意够不够让大家自己体会。 一、FunASR介绍 FunASR是一个由阿里巴巴达摩院开发的开源语音识别工具包,旨在为学术研究和工业应用提供桥梁。它支持多种语音识别功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别。FunASR提供了便捷的脚本和教程,支持预训练模型的推理与微调,帮助用户快速构建高效的语音识别服务。 支持各种音视频格式输入,可以把几十个小时的长音频与视频识别成带标点的文字,支持上百路请求同时进行转写 支持中文、英文、日文、粤语和韩语等。 在线体验:https://www.funasr.com/ 注: FunASR是支持GPU推理加速的,不像阿云早先的一个私有云版本的ASR引擎那样,只用CPU来推理的。 二、FunAsr核心功能 1. 功能列表 2. 离线语音识别 拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。 3. 实时听写 FunASR实时语音听写软件包,集成了实时版本的语音端点检测模型、语音识别、语音识别、标点预测模型等。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。依据使用者场景不同,支持实时语音听写服务(online)、非实时一句话转写(offline)与实时与非实时一体化协同(2pass)3种服务模式。 三、安装部署 1. Requirements 2.创建虚拟环境 3. 安装 【必选】torch+torchaudio安装 我本次测试是直接用pip来安装的,省去docker相关安装、拉取的时间。其中需要注意的是如果你是一个全新的环境,没有torch, torchaudio的环境的话,需要先安装一下这两个。 如果是国内的话可以考虑加速一下 建议安装一下。不安装的话用torchaudio也能跑,但是ffmpeg更佳,毕竟是专业做这个的。没安装ffmpeg会有这个Notice: 4. 下载模型 常规的环境变量,指定huggingface和modelscope的cache路径,并为huggingface做个国内的加速。 5. 下载测试音频文件 在开始测试之前,你需要准备一些测试用的音频,可以直接用阿里云提供的先把功能跑通,然后再去用一些公开的测试集,或者是你自己的测试来测试FunASR的效果。 阿里云上的测试文件: 四、测试运行 在安装好FunASR,下载好模型,下载好测试文件后,可以开始跑正式的测试了。 1. ASR转写 从这个结果里可以看到,FunASR的标点、断句都做的非常好。音字对照的时间戳也都可以给你标出来了,基本上就是它所宣称的工业级别的了,有了这些基本上可以让你自行去扩展实现各种你需要的业务了。 2. VAD检测 对于语音转来说的,非常重要的一个前处理,尤其是针对文件转写来说,通常都需要先检测一下VAD,如果没有VAD,那么那一段时间的音频可以直接扔掉;另外,如果需要将大文件做切片的时候也需要根据VAD来做切片。哪怕转写出来文字后,要进行分段处理,那VAD的情况也是一个重要的参考指标。 3. 标点恢复 我相信没人想要一陀没有任何标点符号的文本吧。FunASR的ct-punc模型可以帮你处理标点符号的恢复。 4. 说话人验证 如果你想做一些说话人验证的产品和功能的时候,FunASR的这个speaker-verification模型可以直接拿来用。 […]