前两天试了一下小红书开源出来的FireRedASR,整体感觉是小红书团队只是把关键的语音识别的模型开放出来了(也只开放了-L的模型),但是由于缺了一些前处理(语音VAD检测)、后处理(标点,多人语音聚类,热词等)相关的功能,普通用户拿到他们这个模型也根本没法直接拿来用,所以个人的观点是对于开源FireRedASR来说,小红书团队的诚意是不够的。
而光嘴巴说他们诚意不够是不能令人信服的,所以咱把阿里在2年多前开源出来的FunASR拿出来介绍一下,诚意够不够让大家自己体会。
一、FunASR介绍
FunASR是一个由阿里巴巴达摩院开发的开源语音识别工具包,旨在为学术研究和工业应用提供桥梁。它支持多种语音识别功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别。FunASR提供了便捷的脚本和教程,支持预训练模型的推理与微调,帮助用户快速构建高效的语音识别服务。
支持各种音视频格式输入,可以把几十个小时的长音频与视频识别成带标点的文字,支持上百路请求同时进行转写 支持中文、英文、日文、粤语和韩语等。
在线体验:https://www.funasr.com/
注: FunASR是支持GPU推理加速的,不像阿云早先的一个私有云版本的ASR引擎那样,只用CPU来推理的。
二、FunAsr核心功能

1. 功能列表
- 语音识别(ASR):支持离线和实时语音识别。
- 语音端点检测(VAD):检测语音信号的起始和结束。
- 标点恢复:自动添加标点符号,提高文本可读性。
- 语言模型:支持多种语言模型的集成。
- 说话人验证:验证说话人的身份。
- 说话人分离:区分不同说话人的语音。
- 多人对话语音识别:支持多人同时对话的语音识别。
- 模型推理与微调:提供预训练模型的推理和微调功能。
2. 离线语音识别
拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。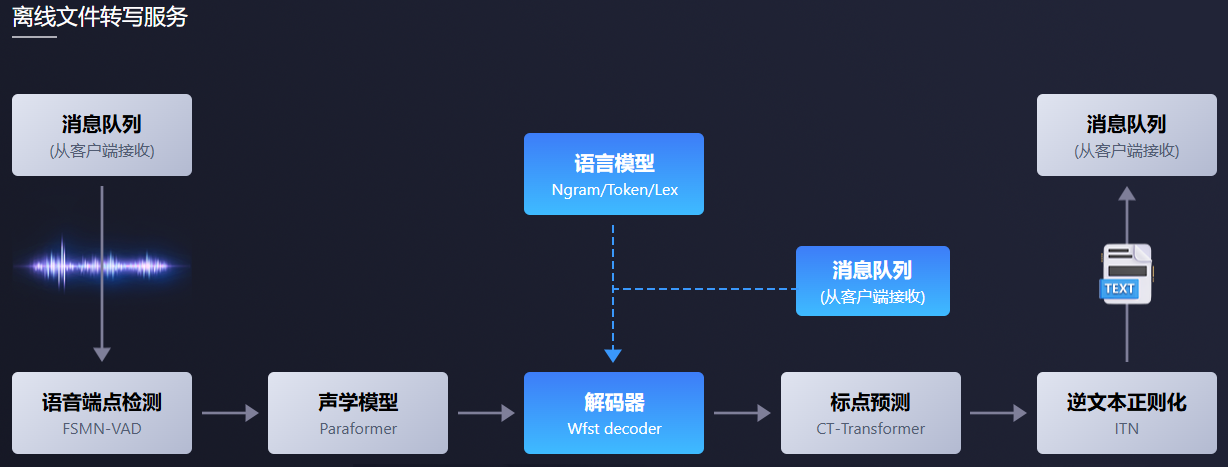
3. 实时听写
FunASR实时语音听写软件包,集成了实时版本的语音端点检测模型、语音识别、语音识别、标点预测模型等。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。依据使用者场景不同,支持实时语音听写服务(online)、非实时一句话转写(offline)与实时与非实时一体化协同(2pass)3种服务模式。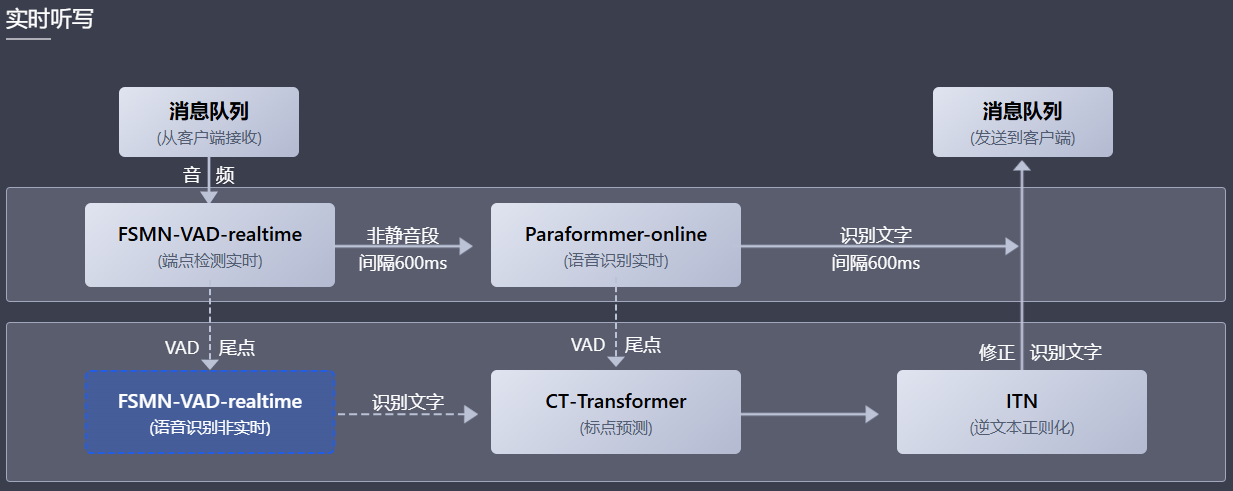
三、安装部署
1. Requirements
python>=3.8
torch>=1.13
torchaudio2.创建虚拟环境
conda create --prefix=/root/autodl-tmp/jacky/envs/funasr python==3.12.3
conda activate /root/autodl-tmp/jacky/envs/funasr3. 安装
- 直接安装
pip3 install -U funasr - 源码安装
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./
pip install -r requirements.txt
export MODEL_DIR=/root/autodl-tmp/FunAsr
【必选】torch+torchaudio安装
我本次测试是直接用pip来安装的,省去docker相关安装、拉取的时间。其中需要注意的是如果你是一个全新的环境,没有torch, torchaudio的环境的话,需要先安装一下这两个。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117如果是国内的话可以考虑加速一下
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 -i https://pypi.tuna.tsinghua.edu.cn/simple- 【可选】安装ffmpeg
建议安装一下。不安装的话用torchaudio也能跑,但是ffmpeg更佳,毕竟是专业做这个的。没安装ffmpeg会有这个Notice:
Notice: ffmpeg is not installed. torchaudio is used to load audio
If you want to use ffmpeg backend to load audio, please install it by:
sudo apt install ffmpeg # ubuntu4. 下载模型
常规的环境变量,指定huggingface和modelscope的cache路径,并为huggingface做个国内的加速。
pip install -U modelscope huggingface_hub
export MODELSCOPE_CACHE=/opt/envs/models
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=/opt/envs/models5. 下载测试音频文件
在开始测试之前,你需要准备一些测试用的音频,可以直接用阿里云提供的先把功能跑通,然后再去用一些公开的测试集,或者是你自己的测试来测试FunASR的效果。
阿里云上的测试文件:
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wav四、测试运行
在安装好FunASR,下载好模型,下载好测试文件后,可以开始跑正式的测试了。
1. ASR转写
- 命令行模式
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=test.wav- 完整响应日志
Notice: ffmpeg is not installed. torchaudio is used to load audio
If you want to use ffmpeg backend to load audio, please install it by:
sudo apt install ffmpeg # ubuntu
# brew install ffmpeg # mac
funasr version: 1.2.6.
Check update of funasr, and it would cost few times. You may disable it by set `disable_update=True` in AutoModel
You are using the latest version of funasr-1.2.6
[2025-04-27 11:27:52,975][root][INFO] - download models from model hub: ms
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
2025-04-27 11:27:54,075 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
[2025-04-27 11:27:57,773][root][INFO] - Loading pretrained params from /root/.cache/modelscope/hub/models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pt
[2025-04-27 11:27:57,781][root][INFO] - ckpt: /root/.cache/modelscope/hub/models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pt
[2025-04-27 11:27:59,562][root][INFO] - scope_map: ['module.', 'None']
[2025-04-27 11:27:59,563][root][INFO] - excludes: None
[2025-04-27 11:27:59,647][root][INFO] - Loading ckpt: /root/.cache/modelscope/hub/models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pt, status: <All keys matched successfully>
[2025-04-27 11:28:01,436][root][INFO] - Building VAD model.
[2025-04-27 11:28:01,436][root][INFO] - download models from model hub: ms
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
2025-04-27 11:28:01,810 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
[2025-04-27 11:28:02,112][root][INFO] - Loading pretrained params from /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch/model.pt
[2025-04-27 11:28:02,113][root][INFO] - ckpt: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch/model.pt
[2025-04-27 11:28:02,122][root][INFO] - scope_map: ['module.', 'None']
[2025-04-27 11:28:02,122][root][INFO] - excludes: None
[2025-04-27 11:28:02,123][root][INFO] - Loading ckpt: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch/model.pt, status: <All keys matched successfully>
[2025-04-27 11:28:02,126][root][INFO] - Building punc model.
[2025-04-27 11:28:02,126][root][INFO] - download models from model hub: ms
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/punc_ct-transformer_cn-en-common-vocab471067-large
2025-04-27 11:28:02,436 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
Building prefix dict from the default dictionary ...
[2025-04-27 11:28:05,226][jieba][DEBUG] - Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
[2025-04-27 11:28:05,226][jieba][DEBUG] - Loading model from cache /tmp/jieba.cache
Loading model cost 0.761 seconds.
[2025-04-27 11:28:05,987][jieba][DEBUG] - Loading model cost 0.761 seconds.
Prefix dict has been built successfully.
[2025-04-27 11:28:05,987][jieba][DEBUG] - Prefix dict has been built successfully.
[2025-04-27 11:28:24,880][root][INFO] - Loading pretrained params from /root/.cache/modelscope/hub/models/iic/punc_ct-transformer_cn-en-common-vocab471067-large/model.pt
[2025-04-27 11:28:24,882][root][INFO] - ckpt: /root/.cache/modelscope/hub/models/iic/punc_ct-transformer_cn-en-common-vocab471067-large/model.pt
[2025-04-27 11:28:25,996][root][INFO] - scope_map: ['module.', 'None']
[2025-04-27 11:28:25,996][root][INFO] - excludes: None
[2025-04-27 11:28:26,103][root][INFO] - Loading ckpt: /root/.cache/modelscope/hub/models/iic/punc_ct-transformer_cn-en-common-vocab471067-large/model.pt, status: <All keys matched successfully>
rtf_avg: 0.110: 100%|??????????????????????????????????????????????????????????????????????????????????????| 1/1 [00:02<00:00, 2.80s/it]
rtf_avg: 0.645: 100%|??????????????????????????????????????????????????????????????????????????????????????| 5/5 [00:09<00:00, 1.98s/it]
rtf_avg: -0.251: 100%|?????????????????????????????????????????????????????????????????????????????????????| 1/1 [00:00<00:00, 3.97it/s]
rtf_avg: 0.401, time_speech: 25.380, time_escape: 10.184: 100%|???????????????????????????????????????????| 1/1 [00:10<00:00, 10.26s/it]
[{'key': 'test', 'text': '这是放AR开源项目体验demo、集成、VADASR与标点等工业级别的模型,支持长音频离线文件转写,实时语音识别灯、开源项目。', 'timestamp': [[3980, 4160], [4160, 4400], [4620, 4860], [4900, 5340], [5400, 5580], [5580, 5820], [5840, 6040], [6040, 6280], [6320, 6560], [6580, 6820], [7220, 7815], [9580, 9740], [9740, 9980], [10000, 11160], [11200, 11440], [11440, 11680], [11680, 11920], [11980, 12220], [12300, 12460], [12460, 12700], [12720, 12860], [12860, 13040], [13040, 13180], [13180, 13340], [13340, 13665], [14800, 14980], [14980, 15220], [15460, 15700], [15700, 15920], [15920, 16160], [16200, 16320], [16320, 16520], [16520, 16620], [16620, 16860], [16860, 17020], [17020, 17375], [19160, 19400], [19460, 19700], [19880, 20040], [20040, 20280], [20300, 20500], [20500, 20660], [20660, 20985], [21590, 21670], [21670, 21910], [21910, 22110], [22110, 22345]]}]从这个结果里可以看到,FunASR的标点、断句都做的非常好。音字对照的时间戳也都可以给你标出来了,基本上就是它所宣称的工业级别的了,有了这些基本上可以让你自行去扩展实现各种你需要的业务了。
- python 调用离线文件转写
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)- python调用实时听写
from funasr import AutoModel
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(model="paraformer-zh-streaming")
import soundfile
import os
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
print(res)2. VAD检测
对于语音转来说的,非常重要的一个前处理,尤其是针对文件转写来说,通常都需要先检测一下VAD,如果没有VAD,那么那一段时间的音频可以直接扔掉;另外,如果需要将大文件做切片的时候也需要根据VAD来做切片。哪怕转写出来文字后,要进行分段处理,那VAD的情况也是一个重要的参考指标。
- 命令行模式
python vad.py --model fsmn-vad --input oddmeta_com.wav- python调用模式
from funasr import AutoModel
vad_model = AutoModel.from_pretrained("fsmn-vad")
vad_result = vad_model.detect("oddmeta_com.wav")
print(vad_result)3. 标点恢复
我相信没人想要一陀没有任何标点符号的文本吧。FunASR的ct-punc模型可以帮你处理标点符号的恢复。
- 命令行模式
python punctuate.py --model ct-punc --input oddmeta_com.txt- python调用模式
from funasr import AutoModel
punc_model = AutoModel.from_pretrained("ct-punc")
punc_result = punc_model.punctuate("oddmeta_com.txt")
print(punc_result)4. 说话人验证
如果你想做一些说话人验证的产品和功能的时候,FunASR的这个speaker-verification模型可以直接拿来用。
- 命令行模式
python verify.py --model speaker-verification --input oddmeta_com.wav- python调用模式
from funasr import AutoModel
verify_model = AutoModel.from_pretrained("speaker-verification")
verify_result = verify_model.verify("oddmeta_com.wav")
print(verify_result)5. 多人对话语音识别
多人对话的语音识别,做到基于聚类的角色分离。这也是语音转写里很重要的一个功能需求。
- 命令行模式
python multi_asr.py --model multi-talker-asr --input your_audio.wav- python调用模式
from funasr import AutoModel
multi_asr_model = AutoModel.from_pretrained("multi-talker-asr")
multi_asr_result = multi_asr_model.recognize("oddmeta_com.wav")
print(multi_asr_result)凭良心讲,阿里在开源FunASR的时候是真的够诚意,很地道。FunASR这玩意儿TMD基本上就是一个商业化的东西直接开源出来给大家用了。
这一点其他的一些团队是真的可以再好好学习和思考一下的。
当然,你要说诸如FireRedASR所缺失的一些功能,可以让开发者自己再结合诸如FunASR的各种模型来自行实现,这样说是没错,但是如果不是专门搞ASR/STT的开发者,又会有几个人愿意拿一个半吊子的东西,自己再往上面做各种缝缝补补然后才能实现一个完整的ASR功能呢?
说到此,不禁想再给阿里点一个赞。


{kind=link}
{kind=link}
{kind=link}
One thought on “ASR引擎测试:FunASR,必须给阿里点一个赞”