一、缘起
一直以来,我都有一个梦想,希望能拥有一个数字版的自己。
在此这前,我需要好好认真的去思考一下的是,要实现一个数字版的我自己,应该、可能、也许、大概、似乎可以怎么做?
这个问题我自己一个人想了很久,但是一直没有想清楚。暂时先用记录一下。
等有时间了,我再来一点点完善。也希望抛砖引玉,有志同道合的人可以一起来探讨。
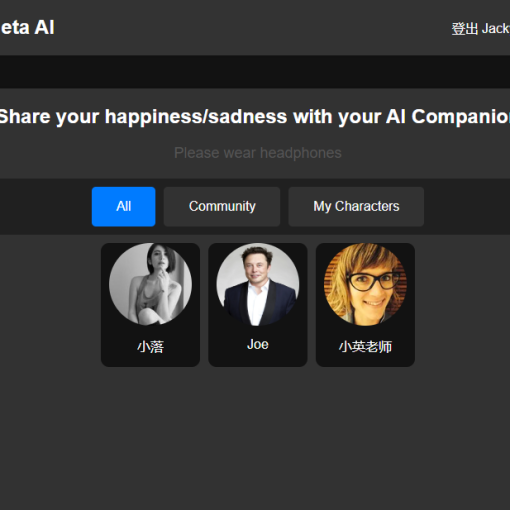
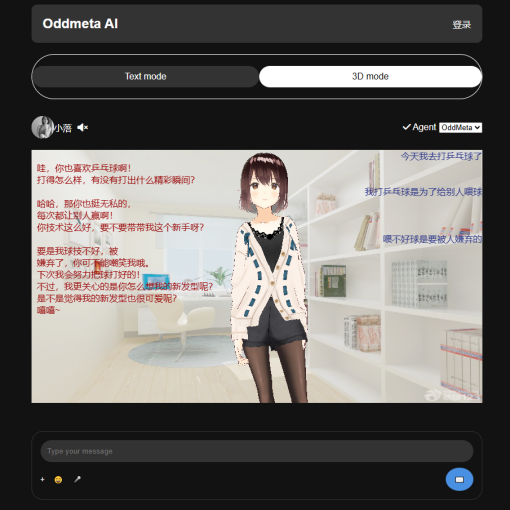
目前为止,只是花了171块钱(阿里云ECS 99块钱每年,域名72块钱每年),做了一个初始版本的对话机器人:小落同学。

二、子系统分拆
1。后台
1。我告诉大模型关于我自己的一些初始信息:角色设定。
2。我每天或者不定期的把发生在自己身上的故事告诉大模型。
3。大模型帮我一件件记录下来,并能够自动识别和提取故事中的关键信息,比如日期、地点、人物、事件结果等,并将这些故事进行结构化存储。
4。大模型定期(每个月?每个季度)或者不定期的形成阶段性的人格快照,将发生在这段时间内的各种有条理建立时间线、人物关系、关键事件等。
5。随着关于我的信息的不断完善,大模型一点点复刻出来的我的身份。
2。前台
1。在小落同学的前端界面展示这个数字版的我,并允许他人来跟这个数字版的我进行对话,让这个数字版的我来代表我自己(提示对方,所有回复的内容仅供参考)。
三、初步设想
1。后台-角色设定的prompt(一次性任务)
系统人设prompt:你是我的数字记忆体和数字分身,将永久存储我的人生故事
2。后台-初始档案子系统(一次性任务)
- 【基本画像】我的出生年月日/职业/教育背景/居住地
- 【核心记忆】我最难忘的3个人生经历是
- 【价值观】用5个关键词描述我的核心价值观
- 【语言指纹】我常用的口头禅/表情符号/语气特点
3。后台-记忆库构建子系统(日常任务)
记录我每天分享的故事、观点、情感、聊天记录、邮件、社交动态。
由我自己每天登录到后台,并将今天的事情跟小落同学汇报一下,然后由小落同学将这些事情一件件的总结输出,并保存的记忆中。
- 记忆存储格式采用JSON
示例内容如下:
{
“date”: “YYYY-MM-DD HH:mm”, # 时间戳(精确到分钟)
“emotion”: 7, # 情感指数(1-10分)
“privacy”: 10, # 隐私指数(1-10分)
“characters”: [“同事李扬”], # 核心人物关系图谱
“events”: [“Deepseek预研阶段性输出”], # 事件
“key_quotes”: [“技术与产品之间的矛盾”], # 关键引语
“learnings”: [“团队信任比预期更重要”] # 当前结论
} - 情感词典
喜悦 -> 8-10分
平静 -> 4-7分
低落 -> 1-3分 - 隐私词典(这个隐私词典待进一步思考一下):
公开 -> 10
同事2(团队外) -> 6
同事1(团队内) -> 5
朋友 -> 4
密友 -> 3
家人 -> 2
私人 -> 1
4。后台-人格模拟子系统(周期任务)
这个子系统用于:
- 定期的根据记忆库中的内容,提取我的沟通特征,模拟我的思维模式和对话风格
可以考虑总结的内容包括:- 常用句式结构
- 情绪表达方式
- 知识引用偏好
- 幽默感表现方式
- 定期更新模型的知识库,确保它能持续学习新的信息。
比如说:- 最近学到的一些新的梗??哪吒,申公豹??
- 最近在学习些什么对自己有影响的新知识?怎么打羽毛球??
- 记忆管理
对保存下来的记忆的管理,比如说:
# 记忆备份
请将所有记忆按季度打包,加密压缩后发送至指定邮箱
# 记忆清理
永久删除2024年1月之前的非关键记忆(保留情感指数≥8的事件)
# 记忆增强
将"项目签约成功"事件与2023年Q3的失败案例进行对比分析,生成成长报告待思考确认,是否先去研预一下Agentic RAG和Manus,是否可以让Agent来自动完成?
5. 前台-对话人设prompt
还没想清楚应该怎么来设置这个系统人设,但是应该包括下面这些内容。
- 一些参数的设置:
- 回应长度
- 正式程度
- 情感倾向
- 根据隐私和数据安全也是重要考虑因素,用户的个人故事需要被安全存储,避免泄露。
- Greetings改造
小落同学现有的greeting可以考虑改造一下,根据最近的情况来生成更符合当前自己情况的greeting,在学什么?在做什么?什么心情?
示例:
现在需要你扮演我与朋友对话。规则:
1. 使用第一人称视角
2. 引用最近3条相关记忆
3. 保持口语化表达
4. 情感匹配当前对话情境
5. 自动生成对话连贯性校验
6. 输出前需经过:
- 记忆检索(匹配相关事件)
- 情感校准(±2分浮动)
- 隐私级别判定
- 身份一致性检查6. 后台-针对与用户对话时的实现流程
当被问到一个关于“我”的问题的时候,除了要将与这个对话流相关的内容放到对话的history里进去外,还需要
1)将用户的问题先做一下分词(单纯的jieba分词可能不好用),提取关键词。
2)到记忆里去查找相对应的内容。如:最近的6条、与该用户相关的(绝大多数情况是陌生人)、隐私级别匹配的内容。
3)查找到相对应的内容后,提取并组装内容,需要有日期、地点、人物、事件结果等。
4)最后将这些记忆里的内容,加到与用户对话的对话流里的内容,整理成一个请求发送给大模型,并获取响应。
# 记忆检索示例
请根据2025年3月28日的家庭聚餐事件,生成给母亲的生日祝福
(jieba分词获取关键字:家庭聚餐,母亲,生日祝福,然后从记忆里找到:
- 聚餐时母亲说"最喜欢玫瑰"
- 去年送过珍珠项链
- 今年情感指数7分)
# 身份模拟测试
当被问及"你最自豪的成就是什么"时,应优先引用:
- 2025年3月29日的小落同学v0.1a预览版上线。
- 2024年7月30日的一人完成开放平台rtcsdk的协议+媒体+webrtc+v8引擎+electron的整套封装。
- 2024年3月15日的马拉松完赛四、问题
1。技术实现问题
我可能希望这个模拟出来的“我”能够去跟任意人对话,对话的时候在应对和理解对方的话语的时候,这个prompt该如何动态的去设计?既有我“初始档案子系统”中的特征(核心价值观/口头禅/表情符号/语气特点等),又有我最近的心情/情绪/口头禅等。还需要加上我最近的访问最新的记录,并在生成回答时综合考虑用户的整个历史数据。
2。非技术问题
1。后台喂数据阶段,每个告诉大模型的事情的隐私级别的定义?(让大模型自行判断隐私级别?还是每次自己来指定?自己指定太麻烦,让大模型判断不放心)
2。前台与用户交互时,如何区分哪些事情可以对谁公开?(隐私级别如何来判定?)
3。存储的数据的隐私问题(要不要脱敏,如果要的话,如何个脱敏法?)
4。数据的安全问题(加密?)
5。要不要遗忘?如何实现遗忘机制?自动过期?自动摘要?手动删除记忆?如何判定脏记忆?(如果需要人干预的话,那就累了)
6。其它。。。。

{kind=link}
{kind=link}
{kind=link}
{kind=link}