OddTTS 是一个功能强大的多引擎语音合成服务,提供统一的API接口和友好的Web界面,一套接口搞定多种主流TTS引擎,包括EdgeTTS、Kokoro-82M-v1.1-zh、ChatTTS、Bert-VITS2、GptSovits v2等,同时也支持OpenAI TTS API的调用。
注意:
- 首次运行时,会自动下载模型文件。
- 模型文件大小:
- Kokoro-82M-v1.1-zh模型:376MB左右。
- EdgeTTS模型:0MB,无需下载模型。
- ChatTTS模型:2.4GB(FP16精度)。
- Bert-VITS2模型:2GB 左右(主干+BERT特征网络,每多一个语种需增加约1.3GB)。
- GptSovits v2模型:2.5GB左右。
- 显存需求:
- EdgeTTS模型:0MB。
- Kokoro-82M-v1.1-zh模型:0MB(普通CPU可运行)。
- ChatTTS模型:至少 2.5GB。
- Bert-VITS2模型:至少 5GB。少样本微调训练,建议使用显存 24GB 以上的 GPU。
- GptSovits v2模型:至少 8GB。少样本微调训练,建议使用显存 24GB/48GB 以上的 GPU。
- 国内用户建议使用镜像加速下载模型文件。
- Windows: set HF_ENDPOINT=https://hf-mirror.com
- Linux/MacOS: export HF_ENDPOINT=https://hf-mirror.com
- 模型文件大小较大,建议在有足够磁盘空间的环境运行,或者自定义模型路径(将 models/hf_home 改成你自己的路径)。
- Windows: set HF_HOME=x:/models/hf_home
- Linux/MacOS: export HF_HOME=/models/hf_home
一、前言
1. 关于OddTTS
由于在做的小落同学项目需要用到TTS语音合成功能,受限于小落同学的硬件环境(阿里云99元一年的ECS服务器)一开始只能选择用EdgeTTS,但是我自己的电脑又配置相对稍好一点,所以前前后后试了多个不同的TTS引擎,但需要将这些试过的TTS模型做一个统一的封装,以便于小落同学可以随时切换到不同的TTS引擎上,因此OddTTS就诞生了。
考虑到TTS功能的用途广泛,就把它单独出来,并开源了。希望对TTS有需求的同学有帮助。
注:如果你要用除EdgeTTS外的其它几个TTS引擎,在安装使用OddTTS前,你需要先自行安装对应的TTS。
2. 为什么建议你选择OddTTS?
- 多引擎支持:集成了EdgeTTS、Kokoro、ChatTTS、Bert-VITS2、GptSovits等多种TTS引擎
- 多种调用方式:支持文件路径返回、Base64编码返回、流式响应等多种输出方式
- 友好的Web界面:基于Gradio提供可视化操作界面
- RESTful API:提供完整的REST API,便于集成到其他系统
- 可配置性强:支持GPU加速、并发线程数调整、模型预加载等配置选项
- 跨平台兼容:基于Python开发,支持Windows、Linux、macOS等多种操作系统
3. 推荐硬件
| 模型名称 | 原版最低运行显存 | 原版流畅运行显存 | 原版满血显存 | INT8 量化最低显存 | INT4 量化最低显存 | 纯 CPU 能否运行 | CPU 运行速度 |
|---|---|---|---|---|---|---|---|
| EdgeTTS | 0GB | 0GB | 0GB | 0GB | 0GB | ✅ 可以 | 依赖于你的网速 |
| Kokoro | 0GB | 0GB | 0GB | 0GB | 0GB | ✅ 可以 | 高 |
| ChatTTS | 2.5GB | 4GB | 6GB+ | 1.5GB | 1GB | ✅ 可以 | 较快 |
| Bert-VITS2 | 5GB | 6GB | 8GB+ | 3GB | 2GB | ✅ 可以 | 中等 |
| GPT-SoVITS v2 | 8GB | 10GB | 12GB+ | 4GB | 2.5GB | ❌ 不建议 | 较慢 |
小落同学使用情况
- Demo版本: 阿里云上99元每年的ECS(2核2G),跑不动任何一个TTS模型,所以用的是EdgeTTS.
- 本地版本:我自己电脑是一个十年前的老笔记本,用的是Kokoro-82M-v1.1-zh模型,纯CPU、且离线运行,运行速度也快。
二、快速开始
1. 安装OddTTS
pip install -i https://pypi.org/simple/ oddtts2. 启动 OddTTS
1. 默认配置启动
直接在安装好的虚拟环境下,执行下面的命令即可启动
oddtts启动后OddTTS会默认绑定127.0.0.1(仅本地可访问),端口9001。浏览器访问:http://localhost:9001
2. 自定义配置启动
若要允许其他IP访问,请使用以下命令启动服务,将host设置为0.0.0.0,端口也可以改成你自定义的端口。
oddtts --host 0.0.0.0 --port 8080三、OddTTS API接口文档
1. API接口列表
1) OpenAI API 兼容接口
GET /v1/audio/speech- Function: OpenAI TTS API 兼容接口, details see OpenAI TTS API.
- Return: mp3 audio data.
2)获取语音列表
GET /v1/audio/voice/list- 功能:获取当前TTS引擎支持的所有语音
- 返回:语音列表,每个语音包含名称、语言、性别等信息
3)获取特定语音详情
GET /v1/audio/voice/list/{voice_name}- 功能:获取指定语音的详细信息
- 参数:
voice_name– 语音名称 - 返回:语音详细信息
4)生成TTS音频(返回文件路径)
POST /api/oddtts/file- 功能:生成TTS音频并返回文件路径
- 请求体:
{
\"text\": \"要转换为语音的文本\",
\"voice\": \"语音名称\",
\"rate\": 语速调整(-50到50),
\"volume\": 音量调整(-50到50),
\"pitch\": 音调调整(-50到50)
}- 返回:
{\"status\": \"success\", \"file_path\": \"音频文件路径\", \"format\": \"mp3\"}
5)生成TTS音频(返回Base64)
POST /api/oddtts/base64- 功能:生成TTS音频并返回Base64编码
- 请求体:同文件路径API
- 返回:
{\"status\": \"success\", \"base64\": \"Base64编码的音频数据\", \"format\": \"mp3\"}
6)生成TTS音频(流式响应)
POST /api/oddtts/stream- 功能:生成TTS音频并以流式响应返回
- 请求体:同文件路径API
- 返回:流式音频数据(audio/mpeg格式)
7)健康检查
GET /oddtts/health- 功能:检查服务是否正常运行
- 返回:
{\"status\": \"healthy\", \"message\": \"API服务运行正常\"}
2. API调用示例
以下是一些OddTTS的API调用的示例。
其中
voice需要先从后端获取语音列表,再填入当前模型支持的语音名称(接口是:/v1/audio/voice/list),不同的模型的voice音色是不一样的。
1)使用curl调用API
curl.exe -X POST http://localhost:9001/api/oddtts/file ^
-H "Content-Type: application/json" ^
-d "{\"text\": \"欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!\", \"voice\": \"zm_011\", \"rate\": 0, \"volume\": 0, \"pitch\": 0}"2)使用OpenAI库调用API
from openai import OpenAI
base_url = "http://localhost:9001/v1"
model = "oddtts-1"
api_key = "dummy"
voice = "zm_011"
text = "欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!Good good study, day day up!"
def test_openai_tts_api(voice_id):
client = OpenAI(
api_key=api_key,
base_url=base_url
)
response = client.audio.speech.create(
model=model,
input=text,
voice=voice_id,
response_format="mp3"
)
response.write_to_file("output.mp3")
if __name__ == "__main__":
test_openai_tts_api(voice)
3)使用requests库调用API
import requests
# 配置API基础URL
API_BASE_URL = "http://localhost:9001"
# 测试文本
TEST_TEXT = \"欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!Good good study, day day up!\"
# 获取语音列表
def test_api_voices():
response = requests.get(f\"{API_BASE_URL}/v1/audio/voice/list\")
voices = response.json()
print(f\"成功获取 {len(voices)} 个语音选项\")
return voices
# 测试生成TTS音频
def test_api_tts_file(voice_name):
payload = {
\"text\": TEST_TEXT,
\"voice\": voice_name,
\"rate\": 0,
\"volume\": 0,
\"pitch\": 0
}
response = requests.post(f\"{API_BASE_URL}/api/oddtts/file\", json=payload)
result = response.json()
print(f\"音频文件路径: {result.get('file_path')}\")4)使用JavaScript调用API
async function generateTTS(text, voice) {
const response = await fetch('http://localhost:9001/api/oddtts/file', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
text: text,
voice: voice,
rate: 0,
volume: 0,
pitch: 0
})
});
const result = await response.json();
console.log('音频文件路径:', result.file_path);
return result;
}
generateTTS('欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!', 'zm_011');四、Web界面使用
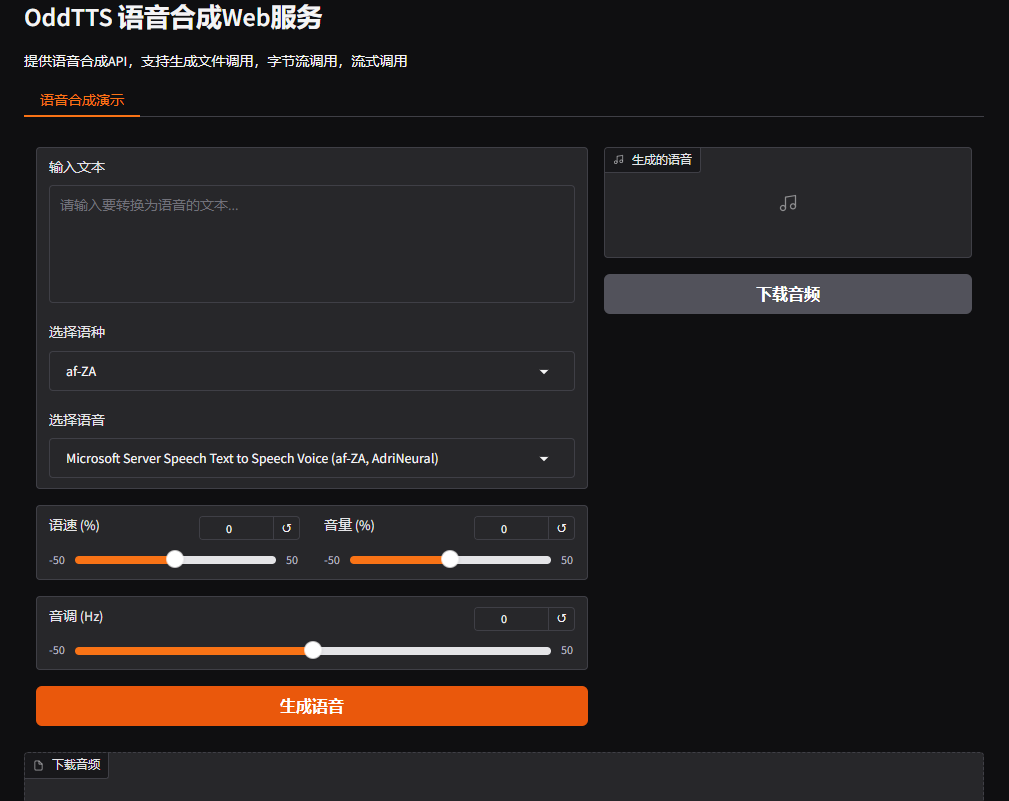
服务启动后,可以通过浏览器访问 http://localhost:9001/ 打开Gradio Web界面,支持以下功能:
- 文本输入区域:输入要转换为语音的文本
- 语音选择:选择不同的语音和语言
- 参数调整:调整语速、音量、音调等参数
- 音频生成:点击按钮生成并播放语音
- 音频下载:下载生成的语音文件
五、常见问题
- 服务启动失败
- 检查端口是否被占用
- 确认所有依赖包已正确安装
- 查看日志文件获取详细错误信息
- 语音合成失败
- 检查TTS引擎配置是否正确
- 确认选择的语音存在于当前TTS引擎中
- 对于某些需要联网的引擎,确认网络连接正常(如: EdgeTTS)
- 如何切换TTS引擎
- 修改
oddtts_config.py文件中的tts_type配置项 - 重启服务使配置生效
- 修改
- 输出格式
- 默认输出格式为mp3
- 可以通过
response_format参数指定其他格式,如wav、mp3等
六、许可证
MIT 许可证 – 详见 LICENSE 文件。商用、个人用、随便用。
也欢迎提交问题和改进建议!