一、前言
你有没有想过,让电脑帮你念一段文章?或者给家里的智能设备添加语音播报功能?
很多人第一次接触语音合成(TTS),想到的是讯飞、百度这些云端API。但仔细一算:调用一次要花钱、网不好会卡顿、隐私数据还要传出去——这对于普通用户来说,门槛实在太高了。
更现实的需求是这样的:
- 想做有声书自媒体,录嗓子又累,用云API一个月几百块跑不掉
- 做智能小车/智能家居项目,需要本地运行的语音反馈
- 在树莓派上跑个小项目,总不能还联网调用API吧?
- 就是想把技术博客变成音频版,自己听着干活
这些场景共同的特点是:设备性能有限、没有显卡、最好能离线使用、还要省钱。
这就是轻量级TTS的用武之地。
二、轻量级TTS方案对比
说方案、对比方案前,先用我实测的一些音频大家听一下效果,感受一下MeloTTS的实际效果。
中英混合:欢迎关注我的公众号:奥德元。一起学习AI,一起追赶时代。Good good study, day day up.
英文-美国口音: text to read
英文-澳大利亚口音: text to read
2.1 主流轻量级TTS方案一览

| 方案 | 参数量 | 部署要求 | 中文支持 | 开源协议 | 特点 |
|---|---|---|---|---|---|
| MeloTTS | ~300M | CPU实时 | ✅ 优秀 | MIT | 多语言、多口音、推理快 |
| espeak-ng | – | 超低资源 | 一般 | GPL | 体积超小(4MB),音质机械 |
| Flite | – | 低资源 | ❌ | C | 轻量但效果一般 |
| VITS | ~40M | GPU优先 | ✅ | GPL | 端到端,音质好 |
| Kokoro-82M | 82M | CPU实时 | ✅优秀 | Apache 2.0 | 超轻量,边缘设备首选 |
| PaddleSpeech | 多种 | CPU/GPU | ✅ | Apache 2.0 | 百度开源,生态完整 |
| OpenVoice v2 | ~1B | 中等GPU | ✅ | MIT | 3秒克隆,但需要GPU |
2.2 为什么选择MeloTTS?
前两天我测试了一下Kokoro-82M的方案,在我的一台10年前的老笔记本上表现出色,并且我也把它整合到了我的OddTTS项目,并在我的小落同学项目中实际用了起来。以我自己的使用场景而言,目前看来Kokoro的方案是最优的,但是它存在一个问题是不支持中英混合的文本输入。而MeloTTS支持中英混合,所以我想再来试试看它的一个表现。
在对比了当前主流方案后,MeloTTS在以下几个维度上表现突出:
1. CPU实时推理
MeloTTS经过专门优化,在普通CPU上就能实现实时语音合成。实测在Intel i7-10700K上,英文推理仅需40ms,中文约90ms。这意味着什么?你不需要显卡,也能流畅使用。
2. 中文支持优秀
很多开源TTS对中文支持稀烂,但MeloTTS专门优化了中文引擎,不仅能处理纯中文,还能中英文混合输入。想想你在文章里夹个English单词,它能给你念出来——这对于技术文档特别友好。
3. 多语言多口音
支持英语(美式/英式/印度/澳大利亚)、中文、法语、日语、韩语等,一个模型搞定多种语言。
4. 开源免费,商用无忧
MIT许可证,完全开源,可以免费商用,不用担心突然收到律师函。
5. 架构先进
基于VITS2架构,结合变分推理和对抗学习,直接从文本生成高质量波形,无需额外的对齐器或声码器。
2.3 MeloTTS核心概念
| 概念 | 定义 |
|---|---|
| VITS | 变分推理+对抗学习的端到端文本转语音模型 |
| G2P | Grapheme-to-Phoneme,把文字转为音素 |
| BERT特征 | 用中文RoBERTa提取语义特征,提升韵律自然度 |
| 声码器 | 将声学特征转换为最终波形 |
三、MeloTTS安装与部署
3.1 环境准备
最低配置要求:
- CPU: Intel i5 或同等性能以上
- 内存: 4GB以上
- 硬盘: 至少5GB空闲空间
- 系统: Linux / macOS / Windows (WSL2推荐)
Windows原生支持已有社区方案,但推荐用WSL2或Docker,体验更稳定。
3.2 安装步骤
第一步:克隆项目
MeloTTS的官方仓库是:
https://github.com/myshell-ai/MeloTTS.git
但是官方仓库已经两年没更新了,直接用上面标准的requirements.txt无法安装,这个问题我改了一下,代码仓库在这儿:
https://github.com/oddmeta/MeloTTS.git
你可以先用官方的版本试试:
git clone https://github.com/myshell-ai/MeloTTS.git
cd MeloTTS如果不行的话,切到我的仓库:
git clone https://github.com/oddmeta/MeloTTS.git
cd MeloTTS第二步:创建conda环境(推荐)
conda create -n melotts python=3.10
conda activate melotts第三步:安装依赖
pip install -r requirements.txt第四步:下载模型
MeloTTS会自动下载所需模型,首次运行时会提示下载。如果网络不好,可以手动下载:
# 中文模型
mkdir -p MeloTTS/melo/checkpoints
# 模型会自动下载到 checkpoints 目录Windows下用: mkdir MeloTTS\melo\checkpoints
第五步:安装CUDA支持(可选,有GPU时)
我的这个十年前的老笔记本没有GPU,所以跳过。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1213.3 快速测试
命令行测试:
# 中文测试
melo "text-to-speech 领域近年来发展迅速" zh.wav -l ZH
# 英文测试(可换不同口音)
melo "Welcome to follow my wechat: OddMeta. Let's learn AI together and keep up with the times! Good good study, day day up" output.wav --language EN --speaker EN-US
melo "Text to read" output.wav --language EN --speaker EN-AUPython API调用:
中英混合测试
from melo.api import TTS
# Speed is adjustable
speed = 1.0
device = 'cpu' # or cuda:0
text = "欢迎关注我的公众号:奥德元。一起学习AI,一起追赶时代!Good good study, day day up"
model = TTS(language='ZH', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'zh.wav'
model.tts_to_file(text, speaker_ids['ZH'], output_path, speed=speed)英文测试(可换不同口音)
from melo.api import TTS
# Speed is adjustable
speed = 1.0
# CPU is sufficient for real-time inference.
# You can set it manually to 'cpu' or 'cuda' or 'cuda:0' or 'mps'
device = 'auto' # Will automatically use GPU if available
text = "Welcome to follow my wechat: OddMeta. Let's learn AI together and keep up with the times! Good good study, day day up"
# English
model = TTS(language='EN', device=device)
speaker_ids = model.hps.data.spk2id
# American accent
output_path = 'en-us.wav'
model.tts_to_file(text, speaker_ids['EN-US'], output_path, speed=speed)
# British accent
output_path = 'en-br.wav'
model.tts_to_file(text, speaker_ids['EN-BR'], output_path, speed=speed)
# Indian accent
output_path = 'en-india.wav'
model.tts_to_file(text, speaker_ids['EN_INDIA'], output_path, speed=speed)3.4 Windows原生安装(备选方案)
如果不想用WSL,Windows用户可以:
# 使用预编译的wheel
pip install melotts
# 或从源码安装
pip install . --no-build-isolation四、使用场景与案例
4.1 有声书制作
场景:你想把自己的技术文章转成音频,放到通勤时听。
操作流程:
- 准备文本文件
article.txt - 编写批量转换脚本:
import os
from melo.api import TTS
with open("article.txt", "r", encoding="utf-8") as f:
text = f.read()
# 分段处理,避免单次输入过长
sentences = text.split("。")
for i, sentence in enumerate(sentences):
if sentence.strip():
audio = TTS(sentence + "。", language="ZH")
with open(f"output_{i:03d}.wav", "wb") as f:
f.write(audio)
print(f"完成第 {i+1} 段")
# 用ffmpeg合并
# ffmpeg -f concat -safe 0 -i filelist.txt -c copy output.wav效果:生成的语音清晰自然,支持中英文混合,性价比远超云端API。
4.2 树莓派离线语音播报
场景:做智能小车,需要本地语音反馈。
配置建议:
| 项目 | 推荐配置 |
|---|---|
| 设备 | 树莓派4B (4GB) |
| 系统 | Raspberry Pi OS 64位 |
| 量化 | INT8量化后模型约120MB |
| 实时性 | 需预加载模型,延迟约2-3秒 |
部署步骤:
# 在树莓派上
sudo apt-get install librosa soundfile
pip install melotts
# 编写播报脚本
python3 tts_voice.py --text "前方障碍物,请注意"4.3 语音助手定制
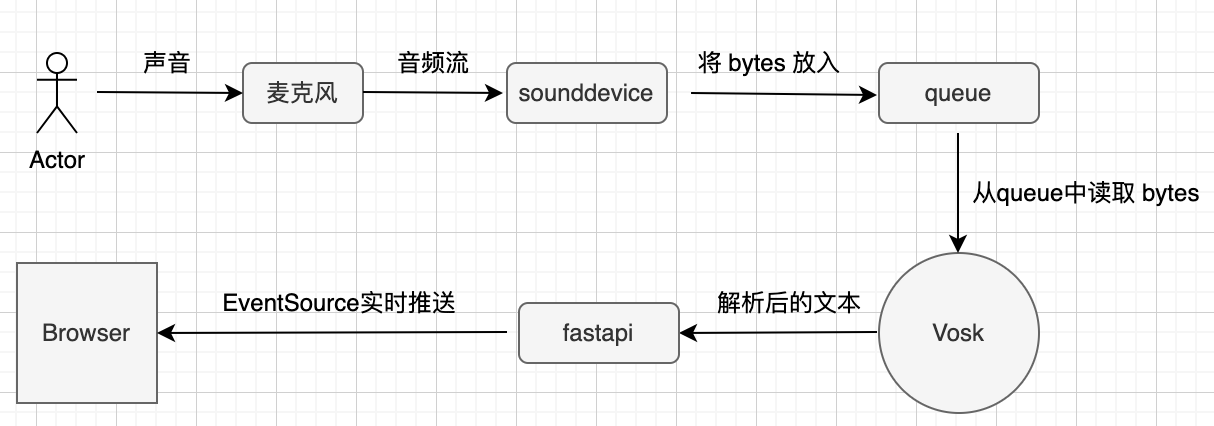
场景:给自己开发的小工具添加语音交互。
from melo.api import TTS
import sounddevice as sd
def speak(text):
audio = TTS(text, language="ZH")
# 直接播放
sd.play(audio, 22050)
sd.wait()
# 使用
speak("系统已启动,一切正常")五、拿走即用
一行命令安装
pip install melotts快速使用
from melo.api import TTS
audio = TTS("你好世界", language="ZH")
with open("hello.wav", "wb") as f:
f.write(audio)语言代码速查
| 语言 | 代码 | 可用音色 |
|---|---|---|
| 中文 | ZH | 默认女声 |
| 美式英语 | EN-US | 清晰自然 |
| 英式英语 | EN-BR | 优雅正式 |
| 印度英语 | EN-IN | 特色口音 |
| 澳大利亚英语 | EN-AU | 活泼 |
| 日语 | JA | 自然流畅 |
| 韩语 | KO | 标准播音 |
相关资源
- GitHub: https://github.com/myshell-ai/MeloTTS
- HuggingFace: https://huggingface.co/myshell-ai/MeloTTS
- 在线Demo: https://huggingface.co/spaces/myshell-ai/MeloTTS
六、注意事项
6.1 中文多音字问题
MeloTTS默认使用基于规则的G2P,对多音字处理可能不完美。解决方案:
方案一:自定义词典(推荐)
from melo.api import TTS
from melotts.text import TextProcessor
# 使用自定义词典
processor = TextProcessor()
processor.load_custom_dict({"行": "xing"}) # 银行=yinhang
melotts = TTS(text_processor=processor)方案二:使用g2pM模型
安装额外依赖后可启用神经网络G2P:
pip install pypinyin6.2 推理速度优化
- GPU加速:有NVIDIA显卡时自动使用,推理速度提升3-5倍
- 批处理:多条文本合并处理,提高吞吐量
- 模型量化:社区已有INT8量化方案
6.3 音质与速度平衡
| 场景 | 推荐配置 |
|---|---|
| 实时对话 | 16kHz采样率 |
| 有声书/播客 | 44.1kHz高音质 |
| 嵌入式设备 | 预量化+低采样率 |
七、常见问题
1. 运行报错:
运行测试命令
melo "Text to read" output.wav报错:[ifs] no such file or directory: D:\anaconda3\envs\tts\Lib\site-packages\unidic\dicdir\mecabrc
Failed initializing MeCab. Please see the README for possible solutions:
https://github.com/SamuraiT/mecab-python3#common-issues
If you are still having trouble, please file an issue here, and include the
ERROR DETAILS below:
https://github.com/SamuraiT/mecab-python3/issues
issueを英語で書く必要はありません。
------------------- ERROR DETAILS ------------------------
arguments:
default dictionary path: D:\anaconda3\envs\tts\Lib\site-packages\unidic\dicdir
[ifs] no such file or directory: D:\anaconda3\envs\tts\Lib\site-packages\unidic\dicdir\mecabrc解决方案:
pip install mecab-python3 unidic-lite
python -m unidic download先移除错误的安装包:
pip uninstall -y mecab mecab-python3 python-mecab-ko python-mecab-ko-dic
安装正确的原生版本 MeCab :
pip install mecab mecab-ko mecab-ko-dic
安装正确的依赖:
pip install –no-cache-dir mecab-python3
测试:
python -c “import MeCab; print(MeCab.Tagger(‘-Owakati’).parse(‘안녕하세요’))”
如果正常的话,你应该会看到: 안녕 하세요 \n
然后再去测试:
melo “Text to read” output.wav
这个时候你会看到开始下载模型、权重等等各种文件了。
七、广而告之
关注我的公众号:奥德元
一起学习AI,一起追赶时代!
新建了一个AI技术交流群,欢迎大家一起加入讨论。
扫码加入AI技术交流群(微信)
若需联系作者,请加微信:oddmeta


{kind=link}
{kind=link}
One thought on “轻量级TTS:MeloTTS纯CPU跑语音合成指南”