引言
前阵子发现,我五一假期几天搞的小落同学新版本的文章《可用十年前老笔记本纯CPU跑的全套虚拟人方案》被微信判定为违规,一下子打消了我写公众号的积极性,所以这段时间都不太想写公众号。
OddASR 是一个兼容 OpenAI API 的自动语音识别(ASR)服务器,支持离线转录和流式转录。让语音转写更简单。
距离上次发版又过去了几个月,OddASR 陆陆续续发布了一些重要更新。无论是端侧纯 CPU 运行的突破、多音频格式的全面支持,还是前端自由切换模型的灵活体验,每一次更新都为了让语音转写变得更简单、更强大。
昨天,大佬大白菜 反馈了一些问题,我当时在上班没有时间处理,结果他自己直接帮我修复了。
今天我在家也顺便把他帮忙改的代码也合到了主分支,然后顺便也发布了一个新的版本 2.4.6,这里就盘点一下 OddASR 近期的一些更新,顺手把文档也更新了一下(今年一直在忙公司那边的一个智能运维的项目,每天跟产品、测试、需求纠缠不清,包括OddASR、小落同学等项目也都一直没时间搞,更别说是一些文档了)。
一、SenseVoice ONNX 版:端侧 CPU 也能飞
最大的更新莫过于SenseVoice ONNX 版本 的加入,这主要是应对小落同学要在我那个十年前的老笔记本上跑的需求。
借助 sherpa-onnx 框架,SenseVoice 现在可以在纯 CPU 环境下流畅运行,无需 GPU 也能获得出色的识别效果。这对于没有独立显卡的服务器、笔记本乃至边缘设备来说,无疑是个巨大的福音。
功能对应「小落同学」的新版本,特别感谢 大蟑螂 和 大白菜 两位大佬的贡献支持和建议!”
SenseVoice 同时支持离线转写和模拟流式输出(基于内置 VAD),成为继 Paraformer、Moonshine 之后的第三大后端引擎。
个人推荐:FunASR > SenseVoice > Moonshine
如果你的电脑CPU性能足够(如 i7-12700H 以上),推荐 FunASR(Paraformer),否则推荐 SenseVoice(如 i5 核 16GB 内存),推荐 Moonshine,否则推荐 SenseVoice,如果想在超低配的板子上跑可以考虑 Moonshine。
二、音频格式全面扩展
过去的 OddASR 主要依赖 WAV 格式,而现在,离线转写 API 已经支持了市面上主流的音频格式:
| 格式 | 支持情况 |
|---|---|
| WAV | ✅ 原生支持 |
| MP3 | ✅ 新增 |
| M4A | ✅ 新增 |
| FLAC | ✅ 新增 |
| AAC | ✅ 新增 |
| OGG | ✅ 新增 |
| WebM | ✅ 新增 |
无论你是从微信导出的 AMR(通过转码)、从网上下载的 MP3,还是录音笔生成的 M4A,直接丢给 OddASR 就能识别,无需再手动转换格式。
依赖:pydub, soundfile, ffmpeg。其中: ffmpeg 需要自行安装(包太大,没有放到OddASR的依赖中)。”
三、输出格式丰富:不止是文字
识别结果想要纯文本?SRT 字幕?还是结构化 JSON?统统安排上。
离线转写 API 现在根据response_format 参数返回不同格式:
response_format=text → 纯文本,简单直接response_format=srt → SRT 字幕格式,剪辑软件直接导入response_format=vtt → VTT 字幕格式,网页播放器友好response_format=json → JSON 结构,方便程序处理response_format=verbose_json → 详细 JSON,包含时间戳和置信度- response_format=spk → 说话人模式,包含每句话的说话人和时间戳
前端页面也同步更新了格式选择下拉框,点一点就能切换输出格式。
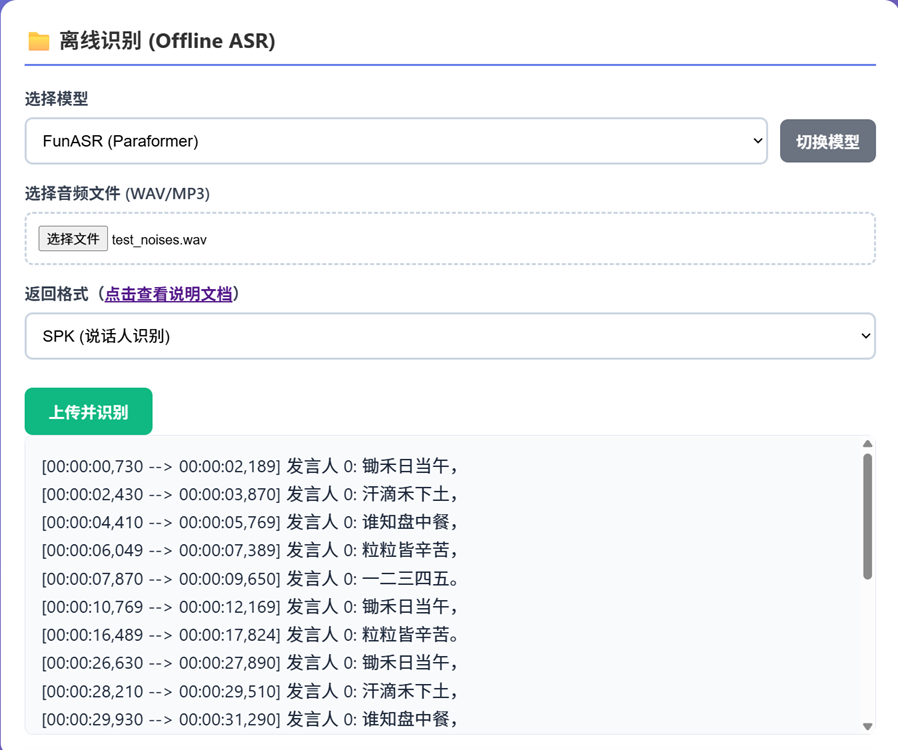
四、前端自由切换模型
这是社区呼声最高的功能之一——在前端页面直接选择不同的 ASR 模型。
现在,你可以在同一个 Web 界面中:
- 切换到FunASR(Paraformer) 获得高精度识别
- 切换到Moonshine 体验轻量快速转写
- 切换到SenseVoice 在 CPU 上获得出色表现
后端会根据前端选择的模型类型动态加载对应的模型实例,无需重启服务,无需修改配置文件。
配合output_type 配置,每个模型还可以独立指定支持的输出格式,互不干扰。
五、Speaker 输出回归
应「大蟑螂」同学的要求,Speaker (说话人分离)输出格式重新恢复。
现在spk 格式可以正常输出了(注:Moonshine 和 SenseVoice 暂不支持 Speaker 识别)。
六、体验优化与 Bug 修复
音频格式识别修复
有用户反馈部分 WAV 文件转写时报Format not recognised 错误。经排查,是 pydub 转换后的 WAV 文件格式与 soundfile 不兼容导致的。该问题已修复,现在各种来源的 WAV 文件都能正常识别,同时也可以支持8K+16K采样的音频了。
模型下载镜像支持
在国内下载 HuggingFace 模型一直是痛点。现在 OddASR 支持配置 mirror 镜像地址,从此告别模型下载慢、下载失败的问题。
注意:
- 首次运行时,会自动下载模型文件。模型文件会保存在
models/目录下。- 模型文件大小较大,建议在有足够磁盘空间的环境运行。
- 国内用户建议使用镜像加速下载模型文件。
- Windows: set HF_ENDPOINT=https://hf-mirror.com
- Linux/MacOS: export HF_ENDPOINT=https://hf-mirror.com
- 本项目基于 Paraformer、Moonshine、SenseVoice 模型实现,若需要使用其他模型,请自行在配置文件中指定模型路径。
”
自动重置模型状态
每次转写结束后,模型状态会自动重置,确保下一次使用时处于干净状态,避免状态累积导致的异常。
编译打包统一
统一了build.py /setup.py 中的pyx 文件列表配置,编译和打包不再不同步,减少因编译遗漏导致的运行时错误。
七、文档全面更新
配合以上所有新功能,我们同步更新了以下文档:
- README / README_en — 中英文双版本同步更新
- API 指南 — 新增模型切换、输出格式等 API 说明
- 响应格式文档 — 详细说明每种格式的使用场景
- 版本说明 — 更新了最新的版本特性
快速开始
# 安装
pip install oddasr
# 启动(默认配置)
oddasr-server
访问 http://localhost:9002 开始使用
API 使用方法
Python 客户端
import openai
client = openai.OpenAI(
base_url="http://localhost:9002/v1",
api_key="dummy" # 兼容需要,实际无需填写
)
# 离线转录
with open("audio.wav", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="oddasr-2",
model_type="funasr",
file=audio_file,
response_format="text" # text, srt, vtt, json, verbose_json, spk
)
print(transcript.text)cURL
curl -X POST http://localhost:9002/v1/audio/transcriptions \
-H "Content-Type: multipart/form-data" \
-F "file=@audio.wav" \
-F "model=oddasr-2" \
-F "model_type=funasr" \
-F "response_format=text"WebSocket 流式识别
import asyncio
import websockets
import json
import base64
async def realtime_transcription():
uri = "ws://localhost:9003/v1/realtime"
async with websockets.connect(uri) as websocket:
async for message in websocket:
data = json.loads(message)
if data['type'] == 'conversation.item.input_audio_transcription.completed':
print(f"转录结果: {data['transcript']}")
elif data['type'] == 'response.audio_transcript.delta':
print(f"中间结果: {data['delta']}", end='\r')
elif data['type'] == 'error':
print(f"错误: {data['error']['message']}")
asyncio.run(realtime_transcription())结语
项目地址:github.com/oddmeta/oddasr
欢迎 Star、Issue、PR,一起让 OddASR 变得更好!
奥德元: 让我们一起学习AI,一起追赶时代。
OddAsr: 让语音转写更简单



{kind=link}
{kind=link}