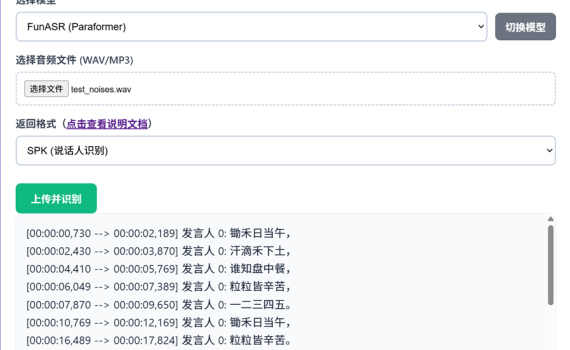
引言 前阵子发现,我五一假期几天搞的小落同学新版本的文章《可用十年前老笔记本纯CPU跑的全套虚拟人方案》被微信判定为违规,一下子打消了我写公众号的积极性,所以这段时间都不太想写公众号。 OddASR 是一个兼容 OpenAI API 的自动语音识别(ASR)服务器,支持离线转录和流式转录。让语音转写更简单。 距离上次发版又过去了几个月,OddASR 陆陆续续发布了一些重要更新。无论是端侧纯 CPU 运行的突破、多音频格式的全面支持,还是前端自由切换模型的灵活体验,每一次更新都为了让语音转写变得更简单、更强大。 昨天,大佬大白菜 反馈了一些问题,我当时在上班没有时间处理,结果他自己直接帮我修复了。 今天我在家也顺便把他帮忙改的代码也合到了主分支,然后顺便也发布了一个新的版本 2.4.6,这里就盘点一下 OddASR 近期的一些更新,顺手把文档也更新了一下(今年一直在忙公司那边的一个智能运维的项目,每天跟产品、测试、需求纠缠不清,包括OddASR、小落同学等项目也都一直没时间搞,更别说是一些文档了)。 一、SenseVoice ONNX 版:端侧 CPU 也能飞 最大的更新莫过于SenseVoice ONNX 版本 的加入,这主要是应对小落同学要在我那个十年前的老笔记本上跑的需求。 借助 sherpa-onnx 框架,SenseVoice 现在可以在纯 CPU 环境下流畅运行,无需 GPU 也能获得出色的识别效果。这对于没有独立显卡的服务器、笔记本乃至边缘设备来说,无疑是个巨大的福音。 功能对应「小落同学」的新版本,特别感谢 大蟑螂 和 大白菜 两位大佬的贡献支持和建议!” SenseVoice 同时支持离线转写和模拟流式输出(基于内置 VAD),成为继 Paraformer、Moonshine 之后的第三大后端引擎。 个人推荐:FunASR > SenseVoice > Moonshine […]
paraformer
2 posts
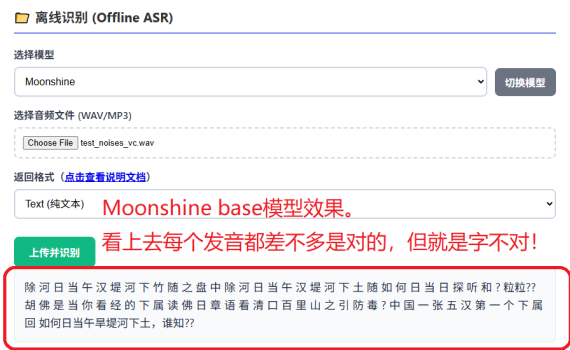
前两天研究了一下Moonshine Voice,当时拿了几个简单的音频文件测试了一下,感觉效果还可以,所以我就开始将其整合到了OddASR项目里。 但是在完成了整合后,再进行测试的时候发现一些比较严重的问题,所以,我又赶紧把我刚刚上传到pypi的OddASR给撤了,然后重新将主力模型改回到paraformer-zh-streaming和paraformer-zh。 当前OddAsr最新版本:v2.1.0,已恢复paraformer模型。 以下是在OddAsr自带的测试界面上分别跑paraformer-zh和moonshine base模型的效果 测试音频 具体的声音情况可以看这个视频: https://mp.weixin.qq.com/s/y4l-YtaUhayV9k9EDatCzw 注:这个视频中并未使用我的OddASR,效果差不是我OddAsr项目的锅。相反,下面我后来有将这个视频中的音频提取出来,专门作为OddAsr的一个测试集,每次测试不同的ASR模型的时候都会来测试一下这种场景。比如:这次的Moonshine base中文模型的测试。 测试效果 测试使用的音频就是上面那个视频里提取出来的音频。 paraformer模型效果 只想用一个字来形容:bravo! moonshine base模型效果 看上去转写出来的每个发音都是对的,但是。。。。这些个字呢。。。。好像就没几个是对的。 总结 唉,如果不是因为我这个用了超过十年的老笔记本CPU不太够用,我也完全不想去折腾一些其他的轻量级的ASR模型。