一、项目背景
OddTTS:一个统一多引擎的 TTS 语音合成 API 封装工具,现已支持 OpenAI TTS API 兼容
OddTTS 诞生于作者的一个实际需求——为项目 「小落同学」 提供文字转语音能力。由于受限于99元/年的阿里云ECS服务器硬件条件,最初只能使用 EdgeTTS,但作者本人的电脑配置尚可(十年前买的老笔记本,呵呵),尝试了多种 TTS 引擎后,决定为这些模型创建一个统一的封装层。
于是,OddTTS 应运而生——一个强大的多引擎文本转语音服务,提供统一的 API 接口和友好的 Web 界面,让你用一套接口就能对接多个主流 TTS 引擎。
二、核心功能
支持多种 TTS 引擎:
- EdgeTTS — 无需下载模型,在线调用,零显存占用
- Kokoro-82M-v1.1-zh — 约376MB,纯 CPU 可运行,速度快,支持中英混合。
- ChatTTS — 约2.4GB,支持纯 CPU 运行
- Bert-VITS2 — 约2GB,最低5GB显存
- GPT-SoVITS v2 — 约2.5GB,最低8GB显存
我自己目前使用的主要是:EdgeTTS和Kokoro-82M-v1.1-zh这两个模型,分别用在阿里云ECS和我自己的十年前老笔记本上。
注:市面上还有许多其他的轻量级的TTS模型,但是由于我自己的使用场景里,主要的语言是中文,所以我选择的都是必须要支持中文的轻量级模型,不支持的一概忽略。
多种调用方式:
- OpenAI TTS API 完全兼容
- 返回文件路径
- 返回 Base64 编码
- 流式响应
在OddTTS自带的Demo的web上都有演示。
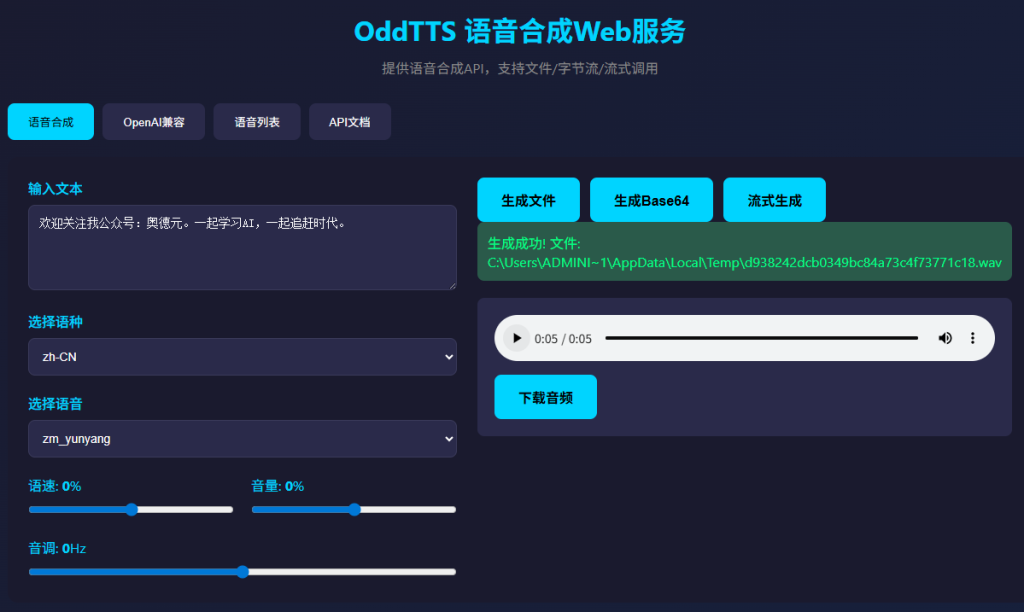
好用的 Web 界面:
基于 Flask 构建的可视化操作界面,支持文本输入、语音选择、参数调节、音频生成与下载,开箱即用。
三、近期更新亮点
API 请求耗时日志 — 现在每个 API 请求都会打印时耗日志,启动时也会显示当前运行的 TTS 引擎名称,方便监控和调试。
模型下载异常修复 — 修复了模型首次下载过程中的异常问题(感谢 大白菜 大佬的反馈)。
测试程序完善 — 对测试流程进行了优化,确保更可靠的运行体验。
文档同步更新 — 文档已同步至 docs.oddmeta.net,同步了最新功能说明。
打包问题修复 — 修复了 favicon.ico 未正确打包的问题,以及 pyproject.toml 授权语法已同步到最新版本。
四、快速开始
1. 安装
pip install -i https://pypi.org/simple/ oddtts2. 启动
oddtts默认绑定 http://localhost:9001,浏览器打开即可使用。
也可以自定义IP和端口启动:
oddtts --host 0.0.0.0 --port 80803. 接口调用
以下是一些OddTTS的API调用的示例。
其中
voice需要先从后端获取语音列表,再填入当前模型支持的语音名称(接口是:/v1/audio/voice/list),不同的模型的voice音色是不一样的。
1)使用curl调用API
curl.exe -X POST http://localhost:9001/api/oddtts/file ^
-H "Content-Type: application/json" ^
-d "{\"text\": \"欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!\", \"voice\": \"zm_011\", \"rate\": 0, \"volume\": 0, \"pitch\": 0}"2)使用 OpenAI 库调用API
from openai import OpenAI
base_url = "http://localhost:9001/v1"
model = "oddtts-1"
api_key = "dummy"
voice = "zm_011"
text = "欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!Good good study, day day up!"
def test_openai_tts_api(voice_id):
client = OpenAI(
api_key=api_key,
base_url=base_url
)
response = client.audio.speech.create(
model=model,
input=text,
voice=voice_id,
response_format="mp3"
)
response.write_to_file("output.mp3")
if __name__ == "__main__":
test_openai_tts_api(voice)3)使用requests库调用API
import requests
# 配置API基础URL
API_BASE_URL = "http://localhost:9001"
# 测试文本
TEST_TEXT = \"欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!Good good study, day day up!\"
# 获取语音列表
def test_api_voices():
response = requests.get(f\"{API_BASE_URL}/v1/audio/voice/list\")
voices = response.json()
print(f\"成功获取 {len(voices)} 个语音选项\")
return voices
# 测试生成TTS音频
def test_api_tts_file(voice_name):
payload = {
\"text\": TEST_TEXT,
\"voice\": voice_name,
\"rate\": 0,
\"volume\": 0,
\"pitch\": 0
}
response = requests.post(f\"{API_BASE_URL}/api/oddtts/file\", json=payload)
result = response.json()
print(f\"音频文件路径: {result.get('file_path')}\")4)使用JavaScript调用API
async function generateTTS(text, voice) {
const response = await fetch('http://localhost:9001/api/oddtts/file', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
text: text,
voice: voice,
rate: 0,
volume: 0,
pitch: 0
})
});
const result = await response.json();
console.log('音频文件路径:', result.file_path);
return result;
}
generateTTS('欢迎关注我的公众号: 奥德元。一起学习AI,一起追赶时代!', 'zm_011');五、硬件兼容性一览
| 引擎 | 最低显存 | 纯CPU运行 |
|---|---|---|
| EdgeTTS | 0GB | ✅ |
| Kokoro | 0GB | ✅ |
| ChatTTS | 2.5GB | 量化可考虑 |
| Bert-VITS2 | 5GB | 量化可考虑 |
| GPT-SoVITS v2 | 8GB | ❌ 不推荐 |
六、注意事项
如果你要用除EdgeTTS和Kokoro外的其它几个TTS引擎,在安装使用OddTTS前,你需要先自行安装对应的TTS。
注意:
- 首次运行时,会自动下载模型文件。
- 模型文件大小:
- Kokoro-82M-v1.1-zh模型:376MB左右。
- EdgeTTS模型:0MB,无需下载模型。
- ChatTTS模型:2.4GB(FP16精度)。
- Bert-VITS2模型:2GB 左右(主干+BERT特征网络,每多一个语种需增加约1.3GB)。
- GptSovits v2模型:2.5GB左右。
- 显存需求:
- EdgeTTS模型:0MB。
- Kokoro-82M-v1.1-zh模型:0MB(普通CPU可运行)。
- ChatTTS模型:至少 2.5GB。
- Bert-VITS2模型:至少 5GB。少样本微调训练,建议使用显存 24GB 以上的 GPU。
- GptSovits v2模型:至少 8GB。少样本微调训练,建议使用显存 24GB/48GB 以上的 GPU。
- 国内用户建议使用镜像加速下载模型文件。
- Windows: set HF_ENDPOINT=https://hf-mirror.com
- Linux/MacOS: export HF_ENDPOINT=https://hf-mirror.com
- 模型文件大小较大,建议在有足够磁盘空间的环境运行,或者自定义模型路径(将 models/hf_home 改成你自己的路径)。
- Windows: set HF_HOME=x:/models/hf_home
- Linux/MacOS: export HF_HOME=/models/hf_home
七、写在最后
OddTTS 的目标是让 TTS 集成变得简单。无论你是做 AI 助手、内容创作工具,还是语音交互应用,都能快速接入。
项目已在 GitHub 开源,使用 MIT 协议,商用或非商用,请随意。欢迎贡献和提建议!
关注我的个人公众号:奥德元,一起学习 AI,一起追赶时代!



{kind=link}
{kind=link}