一、项目背景 OddTTS:一个统一多引擎的 TTS 语音合成 API 封装工具,现已支持 OpenAI TTS API 兼容 OddTTS 诞生于作者的一个实际需求——为项目 「小落同学」 提供文字转语音能力。由于受限于99元/年的阿里云ECS服务器硬件条件,最初只能使用 EdgeTTS,但作者本人的电脑配置尚可(十年前买的老笔记本,呵呵),尝试了多种 TTS 引擎后,决定为这些模型创建一个统一的封装层。 于是,OddTTS 应运而生——一个强大的多引擎文本转语音服务,提供统一的 API 接口和友好的 Web 界面,让你用一套接口就能对接多个主流 TTS 引擎。 二、核心功能 支持多种 TTS 引擎: 我自己目前使用的主要是:EdgeTTS和Kokoro-82M-v1.1-zh这两个模型,分别用在阿里云ECS和我自己的十年前老笔记本上。 注:市面上还有许多其他的轻量级的TTS模型,但是由于我自己的使用场景里,主要的语言是中文,所以我选择的都是必须要支持中文的轻量级模型,不支持的一概忽略。 多种调用方式: 在OddTTS自带的Demo的web上都有演示。 好用的 Web 界面: 基于 Flask 构建的可视化操作界面,支持文本输入、语音选择、参数调节、音频生成与下载,开箱即用。 三、近期更新亮点 API 请求耗时日志 — 现在每个 API 请求都会打印时耗日志,启动时也会显示当前运行的 TTS 引擎名称,方便监控和调试。 模型下载异常修复 — […]
OddTTS
7 posts

前言 最近在折腾 OddTTS 项目,涉及语音合成后的处理。发现一个很香的轻量级变声方案——直接用 FFmpeg 就能搞定,不需要复杂的模型部署。 本文记录 FFmpeg 变声的核心方法、性能数据、以及在 OddTTS 项目中的实际应用场景。 先来听听效果 原始声音: 变声: 卡通声: 一、FFmpeg 变声原理解析 1.1 核心滤镜:asetrate + aresample FFmpeg 变声的核心在于两个滤镜的配合: 简单理解:asetrate 相当于把录音速度改了,音调随之变化;aresample 把时长”拉”回来。 1.2 保持原始时长:atempo 上面的方法会导致音频时长变化。如果要保持原时长,需要加 atempo: 原理:asetrate 改变音调会改变时长,atempo 反向调整速度,两者抵消。 二、常用变声效果库 直接套用,无需记公式: 效果 命令 适用场景 男变女 asetrate=44100*1.4,aresample=44100 客服配音 女变男 asetrate=44100*0.7,aresample=44100 角色切换 卡通音 asetrate=44100*2,atempo=0.5,aresample=44100 短视频特效 机器人声 afftfilt=real='hypot(re,im)*0.3':imag='0' 科幻配音 […]

一、先看效果 你有一本 10 万字的技术电子书,想把它变成有声书。不是那种机器感很强的合成音,而是自然流畅的人声。 把文本拖进去,点一下开始,然后去喝杯咖啡。回来的时候,一本完整的有声书已经躺在你的文件夹里了。 这不是科幻,这是我真做出来的功能。 实测效果: 二、什么是 OddTTS? OddTTS 是我之前开源的语音合成 API 封装项目。 两个特点:多引擎、低成本。 多引擎:支持 Kokoro、MeloTTS、Edge TTS、OpenAI TTS 统一调用。 低成本:Kokoro 可以在十年前的老笔记本上跑,纯 CPU 推理,一次部署无限使用。 以前做有声书,要么买云端 API(一本书几十块),要么自己部署大模型(需要显卡)。 现在一台几百块的 CPU 机器就能跑,还免费。 三、用 oh-my-openagent 实现的全流程 这一节讲讲我怎么做这个项目。 3.1 第一步:需求分析 用的 Agent:Metis(预规划分析) 直接跟 oh-my-openagent 说”我想做一个有声书功能”,它会调用 Metis 帮你分析: Metis 分析的结果: 3.2 第二步:制定计划 用的 Agent:Prometheus(任务规划) Prometheus 会制定详细的实现计划: Prometheus […]
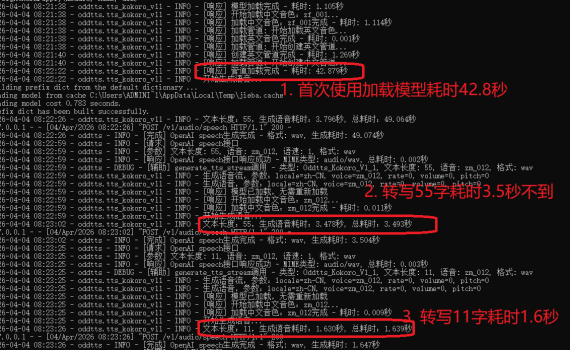
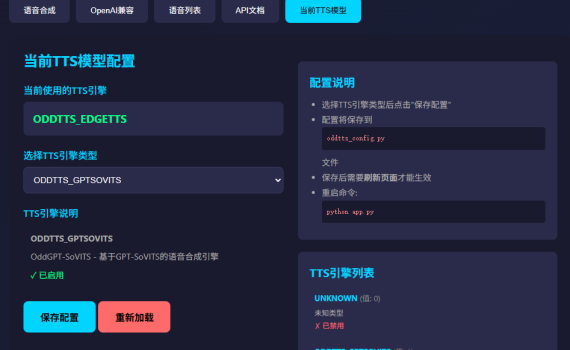
上个星期分别测试了一下两个轻量级的语音合成模型,分别是: 其中Kokoro以更低的CPU要求,可完美达成我的小落同学项目的实时语音交互的需求,因此现在我已经将我的小落同学的主打语音合成在OddTTS上切到了kokoro v1.1。 这里要特别感谢一下一位大佬:路遥。因为前面我以为Kokoro不支持中英混合,所以一开始是准备用MeloTTS的(对CPU要求相对较高),在他的提示下才发现原来Kokoro也可以通过将创建英文和中文两个pipeline来实现中英混合。 以下是一些相关的介绍。 一. 安装 OddTTS 二. 启动 OddTTS 在命令行中输入下面的命令即可启动: 启动后,浏览器打开地址:http://127.0.0.1:9001 启动后,浏览器打开地址:http://your_ip_addr:8080 注: Linux/MacOS: 三. 使用 OddTTS OddTTS支持自定义协议的API,也支持OpenAI兼容接口的API,一般用户建议用OpenAI兼容接口来使用,三行代码搞定语音合成。 其他的API接口可以看OddTTS项目的API接口说明。 四、一些测试数据 1. 合成的语音的效果 合成的语音的效果可以看我之前的测试文章: 正常语速wav格式正常语速mp3格式3倍语速mp3格式 2. 合成的速度 这个是在我的这台十年前的老笔记本上跑的数据: 注:这个3.5秒可认为是首字时延,后面由于合成的速度比播放的速度要快得多的多,所以在长文(需切句子)合成的情况下,实际体验的时延可以做到趋近到500ms以内。 具体如下图所示。 3. 切换不同的TTS模型/引擎 OddTTS有集成了多种不同的TTS模型,包括: OddTTS提供了一个简单的管理、测试界面,在启动了OddTTS后可以在浏览器里打开oddtts,然后动态切换TTS模型/引擎。 五、注意事项 模型下载问题 Kokoro的模型放在huggingface.co上,在国内访问存在问题,解决方案: set HF_ENDPOINT=https://hf-mirror.comset HF_HOME=F:/ai_share/models export HF_ENDPOINT=https://hf-mirror.comexport HF_HOME=/opt/ai_share/models 输出wav正常,输出MP3报错 OddTTS的依赖里有加了ffmpeg,但是如果你机器上原先就有安装过ffmpeg有可能会报错,若是报错了,请再手动安装一下ffmpeg即可。 服务启动失败 语音合成失败 如何切换TTS引擎 输出格式 […]
一、前言 前两天针对轻量级TTS引擎Kokoro做了一些测试( https://mp.weixin.qq.com/s/xKBLfAkfImwHrjYIml0KuA ),测试下来发现效果居然挺好的,而且自带8种音色的支持,纯CPU跑,速度还快,测完了我就停不下来了,当时就想把它整合到我的OddTTS项目,今天周末终于有空,于是就简单搞了一下,现在已经在我的小落同学上用上了。 二、主要更新 先看效果 正常语速wav格式 正常语速mp3格式 更新内容 三、如何使用 1. 安装 pip install -i https://pypi.org/simple/ oddtts 2. 启动 oddtts 启动后,浏览器打开地址:http://127.0.0.1:9001 若要允许其他IP访问,请使用以下命令启动服务,将host设置为0.0.0.0,端口也可以改成你自定义的端口。 启动后,浏览器打开地址:http://your_ip_addr:8080 3. API调用示例 以下是一个OddTTS的API调用的示例,建议用OpenAI 兼容接口 四、注意事项 模型下载问题 Kokoro的模型放在huggingface.co上,在国内访问存在问题,解决方案: set HF_ENDPOINT=https://hf-mirror.comset HF_HOME=F:/ai_share/models export HF_ENDPOINT=https://hf-mirror.comexport HF_HOME=/opt/ai_share/models 输出wav正常,输出MP3报错 OddTTS的依赖里有加了ffmpeg,但是如果你机器上原先就有安装过ffmpeg有可能会报错,若是报错了,请再手动安装一下ffmpeg即可。 服务启动失败 语音合成失败 如何切换TTS引擎 输出格式 环境要求

一、前言 你是否遇到过这样的场景:想给项目添加语音合成功能,却被各种问题困扰——要么模型太大动辄几GB,要么必须依赖GPU云端API,要么商用授权一团糟。 对于个人开发者和小型团队来说,一个理想的TTS方案应该满足三个条件:轻量到能在CPU上跑、免费可商用、效果足够自然。 今天要介绍的 Kokoro-82M,就是这样一款满足所有条件的神器。它只有82M参数,却能输出相当自然的中文语音;体积小巧到只需几百MB,却支持8种不同音色。更重要的是——它完全开源,Apache 2.0许可,零成本商用。 二、方案介绍 概念 定义 Kokoro-82M 由 hexgrad 开发的轻量级TTS模型,仅82M参数,支持8种中文音色 ONNX优化 模型经过ONNX优化,可在CPU上高效推理,无需GPU 语音管道(Pipeline) Kokoro 的核心API,负责分词、音素转换、语音合成全流程 音色(Voice) 预训练的音色模型,不同音色适合不同场景 为什么选择 Kokoro? 指标 数值 参数规模 82M 模型大小 ~165MB 输出采样率 24kHz 支持语言 中文、英语、日语、韩语等8种 中文音色数 8种(4女4男) 推理设备 CPU / GPU 许可协议 Apache 2.0 对比同级别模型,Kokoro 在中文场景下表现尤为突出——不仅音色自然,而且对中文多音字的处理也相当不错。对于没有GPU的个人开发者来说,这可能是目前最优的中文TTS本地方案。 先实际听一下用kokoro合成的音频 我用kokoro生成了一下奥德元的口号:关注我的公众号:奥德元,一起学习 A I,一起追赶时代。,一个男声,一个女声,大家可以实际听下、感受一下合成的语音的效果。 男声: zm_yunyang: kokoro_zm_yunyang.wav女声: […]
一、前言 前阵子有一位同学来问我,小落同学的TTS功能是怎么实现的?我跟他解释了半天,发现双方对一些基础技术、知识、名词都无法对齐,沟通起来实在有些累。后来实在没办法,就跟他说,我把小落同学的TTS功能的代码开源出来,然后你自己直接看代码吧,过了半个钟头,他回来跟我说:非常感谢,对着代码看,一目了然。 呵呵,果然程序员之间的沟通最简单、有效的方式还是:Talk is cheap, show me the code OddTTS的代码绝大部分都是Catherine同学在高考结束后暑假期间写的,而明天她即将开始大学生涯的第一节课,今天特补上这个文章纪念一下高中生涯的结束,并迎接大学学习的正式开始。 二、什么是OddTTS? OddTTS是一个简单的多引擎语音合成服务,整合了当前主流的TTS引擎(如EdgeTTS、GPT-Sovits、Bert-VITS2等),并提供统一的API接口和友好的Web界面。无论你是开发者需要集成语音合成功能,还是普通用户想快速生成语音,OddTTS都能胜任。 项目地址:https://github.com/oddmeta/oddtts 普通用户可以直接访问 http://localhost:9001 即可打开可视化界面开发者可通过http://localhost:9001/api/oddtts/ 接口进行开发集成 三、为什么选择OddTTS? 1. 多引擎支持,语音风格多样 OddTTS集成了多种主流TTS引擎,包括: 你可以根据需求自由切换引擎,轻松获得不同风格的语音输出。 注意:OddGptSovits这个引擎不是开箱即用的,需要用户自己部署GPT Sovits,然后再照着EdgeTTS的API封装一下才能接入到OddTTS 2. 灵活的调用方式 无论你需要哪种输出形式,OddTTS都能满足: 3. 开箱即用的Web界面 启动服务后,通过浏览器访问即可打开基于Gradio的可视化界面,支持: 4. 完善的API服务 开发者可以通过RESTful API轻松集成到自己的系统中,主要接口包括: 5. 高度可配置 通过简单修改配置文件,即可实现: 四、快速上手教程 环境要求 安装步骤 1. 克隆项目代码 2. 灵活的调用方式 无论你需要哪种输出形式,OddTTS 都能满足: 3. 开箱即用的 Web 界面 […]