用Ollama 对 Gemma3多模态27B版本做功能、性能测试

谷歌刚刚推出的开放权重LLM:Gemma 3。它有四种大小,10亿、40亿、120亿和270亿个参数,有基础(预训练)和指令调优版本。Gemma 3 MultiModel人如其名,支持多模式!40亿、12亿和270亿参数模型可以处理图像和文本,而1B变体仅处理文本。
今天咱来试试看。
一、硬件环境
租的AutoDL的GPU服务器做的测试
•软件环境
PyTorch 2.5.1、Python 3.12(ubuntu22.04)、Cuda 12.1
•硬件环境
○GPU:RTX 4090(24GB) * 2
○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430
○内存:480G(至少需要382G)
○硬盘:1.8T(实际使用需要380G左右)
二、虚拟环境及vllm安装
默认认为你已经安装好了conda,如果还没安装的话,先搜索一下conda安装
conda create --prefix=/root/autodl-tmp/jacky/envs/vllm-gemma3 python==3.12.3
conda activate /root/autodl-tmp/jacky/envs/vllm-gemma3/
pip install vllm
三、安装Day0 transformers
Gemma3依赖一些Google新提供的transformers的接口,因此必须先更新一下transformers。
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3
建议走一下github加速器:ghfast.top
pip install git+https://ghfast.top/https://github.com/huggingface/transformers@v4.49.0-Gemma-3
四、模型下载
- 下载保存路径
export HF_HOME=”/root/autodl-tmp/HF_download”
- 科学上网代理
setproxy.py代码:
import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():
if '=' in line:
var, value = line.split('=', 1)
os.environ[var] = value执行 python setproxy.py 设置代理环境变量
- 国内镜像
export HF_ENDPOINT=https://hf-mirror.com然后再下载:
huggingface-cli download --resume-download unsloth/gemma-3-27b-it-bnb-4bit --include "*"共16个G多一点。慢慢来。
五、模型运行
用ollama来运行gemma3
运行前请确保ollama服务已启动,若未启动的话,请在另一个命令行中先启动一下:
ollama serve
若ollama后台服务已经启动,则可以开始加载运行gemma3了
ollama run gemma3:27b
碰到的问题:this model is not supported
若是发现报错如下
Error: llama runner process has terminated:
this model is not supported by your version of Ollama.
You may need to upgrade
解决方案:升级ollama
curl -fsSL https://ollama.com/install.sh | sh
用llama.cpp来运行gemma3
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggerganov/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=ON -DGGML_CUDA=ON -DLLAMA_CURL=ON
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split
cp llama.cpp/build/bin/llama-* llama.cpp[失败]用vllm来运行gemma3
vllm serve unsloth/gemma-3-27b-it-bnb-4bit --max-model-len 5680失败原因:vllm说,gemma3是什么鬼,我还不认识呐。这个模型太新了,vllm还不认识,所以不支持。暂放弃。
六、启动Open WebUI
注:ollama使用的是11434端口
!/usr/bin/env bash
export DATA_DIR="$(pwd)/data"
export ENABLE_OLLAMA_API=False
export ENABLE_OPENAI_API=True
export OPENAI_API_KEY="dont_change_this_cuz_openai_is_the_mcdonalds_of_ai"
export OPENAI_API_BASE_URL="http://127.0.0.1:11434/v1" # <--- 需与ktransformers/llama.cpp的API配置匹配
export DEFAULT_MODELS="openai/foo/bar" # <--- 保留注释,此参数用于litellm接入
export WEBUI_AUTH=False
export DEFAULT_USER_ROLE="admin"
export HOST=127.0.0.1
export PORT=3000 # <--- open-webui网页服务端口
export ENABLE_TAGS_GENERATION=False
export ENABLE_AUTOCOMPLETE_GENERATION=False #或许目前需手动在界面禁用该功能???
export TITLE_GENERATION_PROMPT_TEMPLATE=""
open-webui serve \
--host $HOST \
--port $PORT七、API测试
启用API转发
ssh -CNg -L 8080:127.0.0.1:8000 root@connect.nmb1.seetacloud.com -p 22305
启用Open WebUI转发
ssh -CNg -L 3000:127.0.0.1:3000 root@connect.nmb1.seetacloud.com -p 22305
测试Completion API
curl http://localhost:8000/v1/completions \
-H “Content-Type: application/json” \
-d ‘{
“model”: “Qwen/QwQ-32B-AWQ”,
“prompt”: “San Francisco is a”,
“max_tokens”: 7,
“temperature”: 0
}’
测试Chat Completion API
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/QwQ-32B-AWQ",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
八、结语
在实际测试中发现这个版本的gemma3-27B虽然号称支持140种语言,但是无论我输入的问题是中文的,还是英文的,它给我的响应都是英文的,时间关系,暂未做进一步的探究。
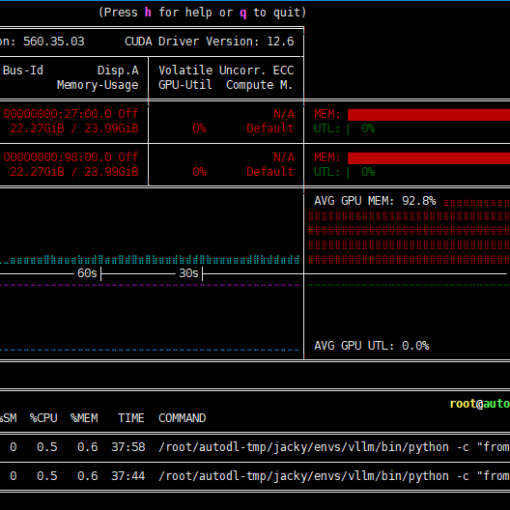
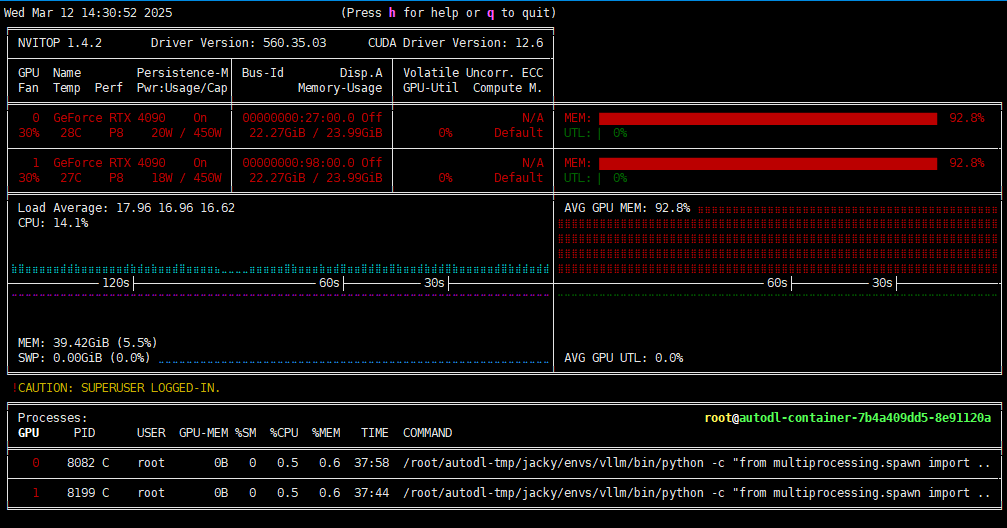
但是它用一张4090跑起来,速度还是蛮快的,至少证明可用。不过近期各个大厂出都在拼命的出各种模型,咱暂时还没时间一个个来做非常深入的测试和验证。
感兴趣并且有时间的朋友可以来试试。
{kind=link}
{kind=link}
{kind=link}
{kind=link}