小红书开源了他们的自动语音识别模型FireRedASR,宣称很牛逼。今天咱也部署一下,并对它做一下测试。
项目地址: https://github.com/FireRedTeam/FireRedASR
为节省大家的时间,直接上结论:这玩意儿拿来学习不错,想拿来做产品不行。如果你是想评估FireRedASR是不是可以直接拿来做产品,那这边劝你放弃吧,但是如果你是想做ASR底层算法的研究,想了解一下它的具体情况的,可以继续往下看。
# 一、FireRedAsr介绍
FireRedASR 据介绍是一个工业级自动语音识别模型,支持普通话、中文方言和英语。该模型在普通话 ASR 基准测试中达到了新的最佳水平(SOTA),并在歌词识别方面表现出色。
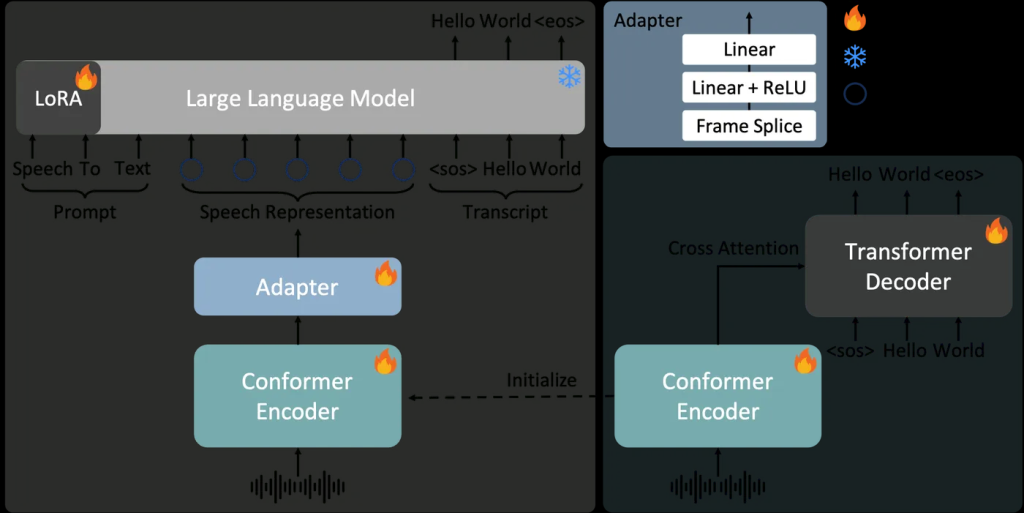
## 版本
它包括了两个版本,分别是FireRedASR-LLM和FireRedASR-AED。
– FireRedASR-LLM:专注于极致的语音识别精度。基于大型语言模型(LLM)的能力,实现 SOTA 性能,支持无缝端到端语音交互。在普通话基准测试中平均字符错误率(CER)为 3.05%,相比之前的 SOTA 模型(3.33%)降低了 8.4%。
– FireRedASR-AED:平衡了高准确率与推理效率。采用基于注意力的编码器-解码器(AED)架构,平衡高性能和计算效率,可作为基于 LLM 的语音模型中的有效语音表示模块。在普通话基准测试中平均 CER 为 3.18%,优于拥有超过 12B 参数的 Seed-ASR。
## 技术原理
– FireRedASR-LLM:结合了大型语言模型(LLM)的能力,实现 SOTA 性能;
– FireRedASR-AED 利用经典的 AED 架构,确保高效推理。
# 二、硬件环境
租的AutoDL的GPU服务器做的测试
– 软件环境
PyTorch 2.5.1、Python 3.12(ubuntu22.04)、Cuda 12.1
– 硬件环境
○GPU:RTX 4090(24GB) * 1
○CPU:64 vCPU Intel(R) Xeon(R) Gold 6430
○内存:480G(至少需要382G)
○硬盘:1.8T(实际使用需要380G左右)
# 三、虚拟环境
– 创建虚拟环境
conda create --prefix=/root/autodl-tmp/jacky/envs/fireredasr python==3.10conda activate /root/autodl-tmp/jacky/envs/fireredasr
– 下载代码并安装依赖
cd /root/autodl-tmp/jackygit clone https://github.com/FireRedTeam/FireRedASR.gitcd FireRedASRpip install -r requirements.txt
– 导出环境变量
export PATH=$PWD/fireredasr/:$PWD/fireredasr/utils/:$PATHexport PYTHONPATH=$PWD/:$PYTHONPATH
# 四、测试环境确认
创建了虚拟环境,并且安装的依赖后,再次确认一下当前环境的情况(因为后面运行报错了)。
## python版本
python --version返回
Python 3.12.3
## CUDA版本
nvcc --version返回
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
## torch版本
python -c "import torch; print(torch.__version__)"返回
2.6.0+cu124
# 五、下载模型
启动huggingface 加速
export HF_ENDPOINT=https://hf-mirror.com下载模型,包括FireRedASR-AED-L, FireRedASR-LLM-L, 以及FireRedASR-LLM-L所依赖的Qwen2-7B-Instruct,共三个模型。
huggingface-cli download --resume-download Qwen/Qwen2-7B-Instruct --include "*" --local-dir /root/autodl-tmp/jacky/FireRedASR/pretrained_models/Qwen2-7B-Instruct
huggingface-cli download --resume-download FireRedTeam/FireRedASR-AED-L --include "*" --local-dir /root/autodl-tmp/jacky/FireRedASR/pretrained_models/FireRedTeam/FireRedASR-AED-L
huggingface-cli download --resume-download FireRedTeam/FireRedASR-LLM-L --include "*" --local-dir /root/autodl-tmp/jacky/FireRedASR/pretrained_models/FireRedTeam/FireRedASR-LLM-L
# 六、示例测试
– 市面上常见的ASR/STT的算法基本都是16K采样率,16BITS位宽的,所以你需要确保测试音频是16K 16bit
ffmpeg -i input_audio -ar 16000 -ac 1 -acodec pcm_s16le -f wav output.wav– 测试
cd examplesbash inference_fireredasr_aed.shbash inference_fireredasr_llm.sh
– 命令行帮助
speech2text.py --help
speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "aed" --model_dir pretrained_models/FireRedASR-AED-L
speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L
– python测试代码
如何用python 来调用FireRedASR?
“`python
from fireredasr.models.fireredasr import FireRedAsr
batch_uttid = [“BAC009S0764W0121”]
batch_wav_path = [“examples/wav/BAC009S0764W0121.wav”]
“`
FireRedASR-AED-L测试代码
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"nbest": 1,
"decode_max_len": 0,
"softmax_smoothing": 1.25,
"aed_length_penalty": 0.6,
"eos_penalty": 1.0
}
)
print(results)FireRedASR-LLM-L测试代码
model = FireRedAsr.from_pretrained("llm", "pretrained_models/FireRedASR-LLM-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"decode_max_len": 0,
"decode_min_len": 0,
"repetition_penalty": 3.0,
"llm_length_penalty": 1.0,
"temperature": 1.0
}
)
print(results)# 七、问题
虽然这些问题里列的功能都是一些通用的常见功能,如果你接触过其他的一些开源ASR项目的话,可以直接搬过来用,但是对于一个想偷懒的人来说,小红书的这个FireRedASR的情况,简单讲就是这个也不支持,那个也不支持。
1. 测试集:小红书自测用的是Kespeech测试集的8种普通话子方言可以作为参考。结果在参考论文中有说明,有条件可以自测一下。
2. 长音频文件:不支持。对我们会议纪要功能来说,就是这个模型不可用。
3. 标点符号:不支持。意味着需要我们自己来做。
4. 多人语音聚类分离:不支持
5. 时间戳:不支持。意味着不能音字对照回听。
6. 方言:支持。但我暂时没有测试集来验证。
7. 热词:不支持。意味着许多专业术语,专用名词转出来会乱七八糟。
# 八、报错及解决方案
## 报错:模型文件找不到
– 问题现象
加载模型失败。
前面下载下来的模型/root/autodl-tmp/jacky/FireRedASR/pretrained_models/FireRedTeam目录下,
如:
/root/autodl-tmp/jacky/FireRedASR/pretrained_models/FireRedTeam/FireRedASR-AED-L/root/autodl-tmp/jacky/FireRedASR/pretrained_models/FireRedTeam/FireRedASR-LLM-L/root/autodl-tmp/jacky/FireRedASR/pretrained_models/Qwen2-7B-Instruct
但是,测试的脚本默认又不是去这个地方加载模型。
严重怀疑小红书这些人真的是认真的吗?到底有没有做过测试?
– 解决方案
1. 把FireRedASR-AED-L和FireRedASR-LLM-L目录移动到pretrained_models目录下
2. 改测试脚本中的路径,给加一个FireRedTeam目录。
## 报错:_pickle.UnpicklingError: Weights only load failed
– 问题现象
在examples目录执行
Traceback (most recent call last):
File "/root/autodl-tmp/jacky/FireRedASR/test.py", line 7, in <module>
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
File "/root/autodl-tmp/jacky/FireRedASR/fireredasr/models/fireredasr.py", line 25, in from_pretrained
model = load_fireredasr_aed_model(model_path)
File "/root/autodl-tmp/jacky/FireRedASR/fireredasr/models/fireredasr.py", line 110, in load_fireredasr_aed_model
package = torch.load(model_path, map_location=lambda storage, loc: storage)
File "/root/autodl-tmp/jacky/envs/fireredasr/lib/python3.10/site-packages/torch/serialization.py", line 1470, in load
raise pickle.UnpicklingError(_get_wo_message(str(e))) from None
_pickle.UnpicklingError: Weights only load failed. This file can still be loaded, to do so you have two options, do those steps only if you trust the source of the checkpoint.
(1) In PyTorch 2.6, we changed the default value of the `weights_only` argument in `torch.load` from `False` to `True`. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
(2) Alternatively, to load with `weights_only=True` please check the recommended steps in the following error message.
WeightsUnpickler error: Unsupported global: GLOBAL argparse.Namespace was not an allowed global by default. Please use `torch.serialization.add_safe_globals([Namespace])` or the `torch.serialization.safe_globals([Namespace])` context manager to allowlist this global if you trust this class/function.
Check the documentation of torch.load to learn more about types accepted by default with weights_only https://pytorch.org/docs/stable/generated/torch.load.html.
– 解决方案
修改fireredasr.py文件,在其中加载模型的地方加一个参数weights_only=False。
cd /root/autodl-tmp/jacky/FireRedASR/fireredasr/modelsvi fireredasr.py
在其中加载模型的地方加一个参数weights_only=False
def load_fireredasr_aed_model(model_path):
package = torch.load(model_path, map_location=lambda storage, loc: storage, weights_only=False)
print("model args:", package["args"])
model = FireRedAsrAed.from_args(package["args"])
model.load_state_dict(package["model_state_dict"], strict=True)
return model


{kind=link}
{kind=link}
{kind=link}
{kind=link}
2 thoughts on “ASR引擎测试:FireRedASR只能说小红书的诚意不够”