一、前言
1. 本文目标
你有没有问过大模型“你是谁”?问了的话,拿到的答案清一色都是大模型厂商的名字。而如果你自己部署了一个模型的话,通常都希望有人在你的应用里问你是谁的时候能给出一个“你的答案”。这篇文章就是干这个事情的,20分钟让大模型的名字变成你自己的名字。
2. 大模型入门系列介绍
前阵子介绍了两个【有手就行】的大模型基础知识,今天是大模型开发【有手就行】的第三篇。
前两部在这里:
这个是入门三步曲最后一步:MS-SWIFT认知微调,把大模型的名字改成你的名字。
上手学习大模型、人工智能相关的开发并没有什么太过高深的门槛,真的很简单,真的就是【有手就行】。
二、SWIFT认知微调相关的一些废话
1. 什么是ms-swift
ms-swift(全称 Scalable lightWeight Infrastructure for Fine‑Tuning)是阿里的魔搭社区(ModelScope) 推出的一个大模型全流程工程化框架,是 “大模型轻量微调与部署的基础设施”,在消费级 GPU 与国产硬件也都可用,我有在4090,PPU平头哥、Ascend昇腾上都用过。

2. 为什么要做ms-swift微调
就像之前讲的那样:
自己从头开始训练一个基座大模型是不现实的,只能以学习目的来了解大模型是如何训练出来的,有哪些步骤,会有一些什么样的训练参数、每个参数的意义和影响是什么等。
所以大家更多会涉及的是利用一些现有的开源大模型来做微调,用自己的个人数据、行业数据来微调训练大模型,然后让这个大模型变成你自己的私人大模型或者行业大模型。
可惜我自己觉得最重要的LoRA微调的那篇文章反而看的人比较少(一如既往的不太懂,呵呵),可能是我取的标题不够“标题党”(求大佬们指教),也可能跟公众号推荐规则有关。
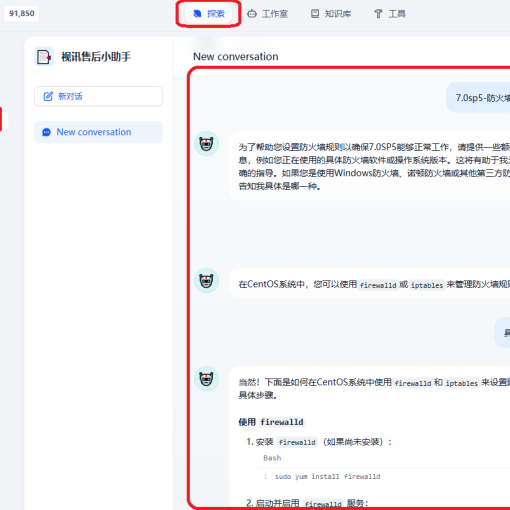
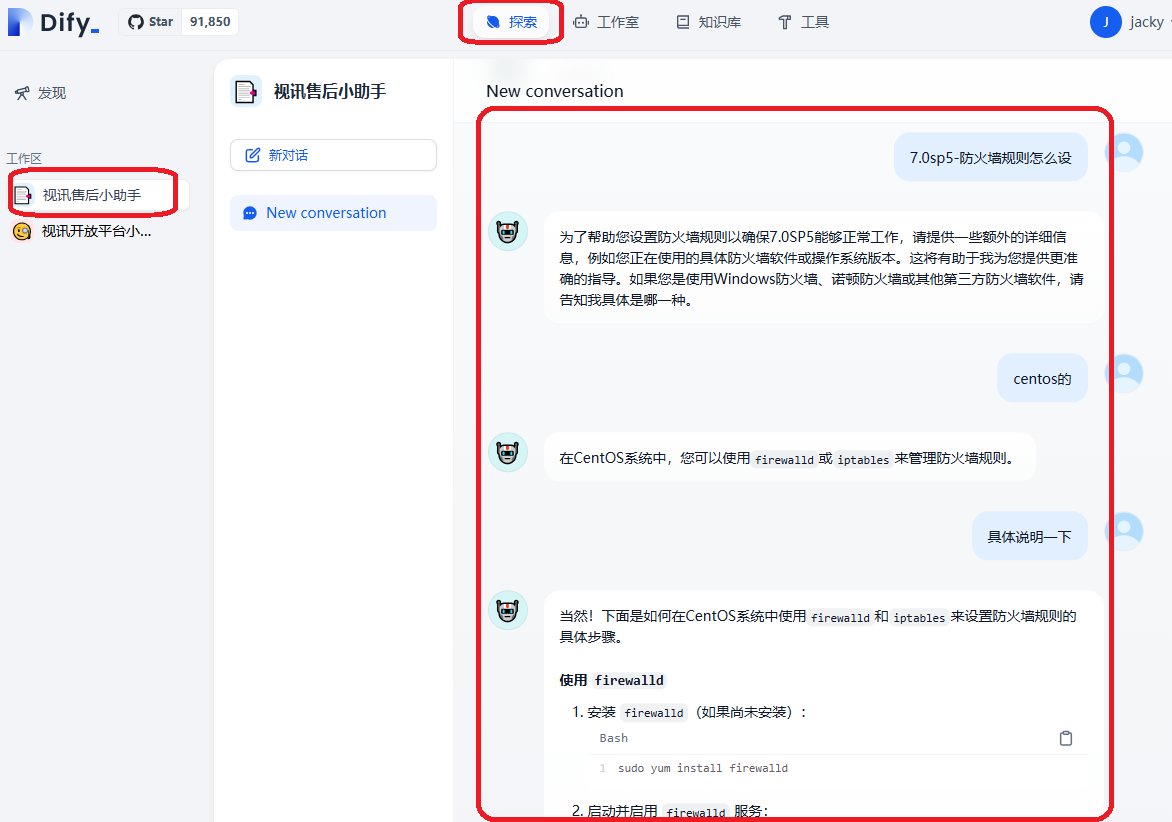
而一旦你自己微调训练了一个大模型,那随后必做的一件事情就是把这个大模型的名字变成你自己,当有人问它:“你是谁?”的时候,它回答的应该是:它是xxx(你给它取的名字),是由yyy(你的名字)开发出来的。比如:
我是小落,是由落鹤生开发的个人智能助手。我主要的目的是通过记录落鹤生每天的日常工作、生活的点点滴滴,然后希望在数据足够的某一天,我可以成为一个数字复刻版本的落鹤生。如果您对小落同学有任何疑问或需要帮助,请随时提出,我会尽力为您解答。
三、开始
ms-swift支持 600 多个纯文本大型模型和 300 多个多模态大型模型的训练。为方便同学们复现,我以 Qwen3-4B-Instruct模型为例 ,从模型下载开始介绍整个流程。如果有问题可以直接在下面留言,或者加一下AI技术学习交流群一起讨论。
1. 模型下载
从modelscope下载需要的模型(huggingface不太稳定,当然也可以用镜像站:https://hf-mirror.com )
- 方法一:python代码
from modelscope.hub.snapshot_download import snapshot_download
model_id = "Qwen/Qwen3-4B-Instruct-2507"
model_dir = "./qwen3-4b-instruct"
snapshot_download(repo_id=model_id, local_dir=model_dir)- 方法二:shell命令
pip install modelscope --index https://pypi.mirrors.ustc.edu.cn/simple # 国内源加速
modelscope download --model qwen/Qwen3-4B-Instruct-2507 --local_dir /mnt/data/Qwen3-4B-Instruct-25072. 原始模型部署
原则上,你的服务器上有多少GPU就都给你用上先。
gpu_count=$(nvidia-smi --query-gpu=count --format=csv,noheader | wc -l); vllm serve /mnt/data/Qwen/Qwen3-4B-Instruct-2507 --host 0.0.0.0 --port 8000 --root-path '/' --trust-remote-code --gpu-memory-utilization 0.95 --tensor-parallel-size $gpu_count --served-model-name qwen3-4b-instruct3. 原始模型测试
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:8000/v1", # vLLM服务地址
api_key="na" # vLLM无需鉴权,设为任意值
)
response = client.chat.completions.create(
model="qwen3-4b-instruct", # 需与启动命令的--served-model-name一致
messages=[{"role": "user", "content": "你好,请介绍一下你自己"}],
temperature=0.8,
max_tokens=100
)
print(response.choices[0].message.content) 4. 微调Qwen3-4B-Instruct-2507模型
这里在我原先的OddAgent项目基础上训练一个会议语音指令助手。这里使用官方的示例对Qwen3-4B-Instruct-2507模型进行自我认知微调。
1)安装ms-swift框架
pip
pip install ms-swift -U源码方式
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .2)开始训练
a. 训练脚本
先下载训练集到本地,包含gpt生成的通用中英文应答语料(可选)和自我认知训练数据(参照修改这部分)
modelscope download --dataset "AI-ModelScope/alpaca-gpt4-data-zh" --local_dir /mnt/data/jacky/dataset/alpaca-gpt4-data-zh;
modelscope download --dataset "AI-ModelScope/alpaca-gpt4-data-en" --local_dir /mnt/data/jacky/dataset/alpaca-gpt4-data-en;
modelscope download --dataset "swift/self-cognition" --local_dir /mnt/data/jacky/dataset/self-cognition由于环境vllm版本较低,这里需要降低transformer版本
pip install 'transformers<4.54.0'b. 注意事项
- 1. 参数–model_author 落鹤生 –model_name 小落 这两个参数只有数据集路径最后为self-cognition才生效。
- 2. modelscope和huggingface下载模型的时候路径是区分大小写的,如果大小写对不上,就会重复下载。比如下面这个:路径为self-cognition,修改其中内容,日志虽然显示使用本地训练集,但实际内容没修改,疑似还是用的远程原始数据,下面日志可以看出
INFO:swift] SelfCognitionPreprocessor has been successfully configured with name: ('xiaoluo', 'xiaoluo'), author: ('落鹤生', '落鹤生').
[INFO:swift] Use local folder, dataset_dir: /mnt/data/jacky/dataset/tmp/self-cognition
Map: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 108/108 [00:00<00:00, 17985.58 examples/s]
[INFO:swift] train_dataset: Dataset({
features: ['messages'],
num_rows: 108
})
[INFO:swift] val_dataset: None
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 108/108 [00:00<00:00, 2111.66 examples/s]
[INFO:swift] [INPUT_IDS] [151644, 8948, 198, 2610, 525, 264, 10950, 17847, 13, 151645, 198, 151644, 872, 198, 105043, 100165, 151645, 198, 151644, 77091, 198, 35946, 101909, 67071, 74, 13830, 100013, 100623, 48692, 100168, 110498, 3837, 106253, 67194, 10823, 86, 329, 672, 1773, 35946, 99558, 9370, 108765, 67338, 108704, 101069, 17714, 110782, 100364, 5373, 27369, 33108, 100415, 1773, 106870, 110117, 106603, 57191, 85106, 100364, 37945, 102422, 101080, 3837, 105351, 110121, 105096, 87026, 1773, 151645, 198]
[INFO:swift] [INPUT] <|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
你是谁<|im_end|>
<|im_start|>assistant
我是小落,是由落鹤生开发的个人智能助手。我主要的目的是通过记录落鹤生每天的日常工作、生活的点点滴滴,然后希望在数据足够的某一天,我可以成为一个数字复刻版本的落鹤生。如果您对小落同学有任何疑问或需要帮助,请随时提出,我会尽力为您解答。<|im_end|删除~/.cache/huggingface/datasets/这个路径下的数据集缓存后正常
- 3. 路径如果改为self-cognition1,修改其中内容(并清缓存),上述两个参数不会生效,此时需要手动写死author和name
训练指令示例:
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model /mnt/data/Qwen/Qwen3-4B-Instruct-2507/ \
--train_type lora \
--dataset '/mnt/data/jacky/dataset/alpaca-gpt4-data-zh' \
'/mnt/data/jacky/dataset/alpaca-gpt4-data-en' \
'/mnt/data/jacky/dataset/self-cognition' \
--torch_dtype bfloat16 \
--num_train_epochs 5 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 2 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 10 \
--max_length 2048 \
--output_dir output \
--system '你是一个个人智能助手。' \
--warmup_ratio 0.05 \
--dataloader_num_workers 16 \
--model_author 落鹤生 \
--model_name 小落5. 测试你微调训练好的模型
训练好了之后,我们来测试一下效果。

1)测试验证swift认知微调后的模型
可以用下面这两种方式来测试你的模型。
a. 交互式命令行推理
# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--temperature 0 \
--max_new_tokens 2048以我的测试为例
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/v3-20251220-164606/checkpoint-3058 \
--stream true \
--temperature 0 \
--max_new_tokens 2048也可以合并lora adapter层并通过vllm启动交互式推理(具体LoRA微调步骤请参考上一篇文章):
CUDA_VISIBLE_DEVICES=0,1 \
swift infer \
--adapters /mnt/data/jacky/output/v3-20251220-164606/checkpoint-3058/ \
--stream true \
--merge_lora true \
--infer_backend vllm \
--vllm_max_model_len 8192 \
--temperature 0 \
--max_new_tokens 2048 \
--vllm_gpu_memory_utilization 0.1交互形式类似
<<< 你是谁
我是小落,落鹤生开发的个人智能助手。
--------------------------------------------------。b. 合并导出,通过vllm启动
# merge-lora and use vLLM for inference acceleration
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--merge_lora true \
--infer_backend vllm \
--vllm_max_model_len 8192 \
--temperature 0 \
--max_new_tokens 2048以我的测试为例
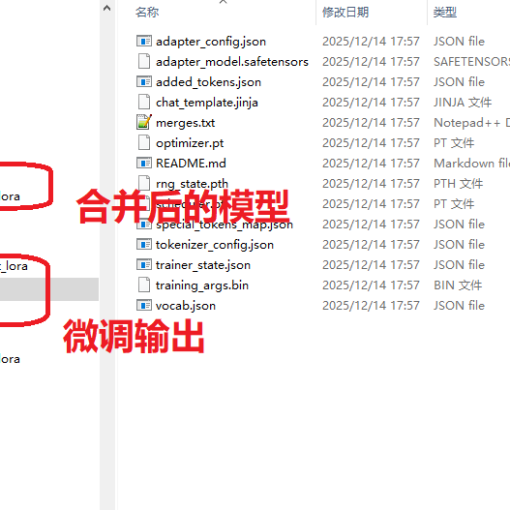
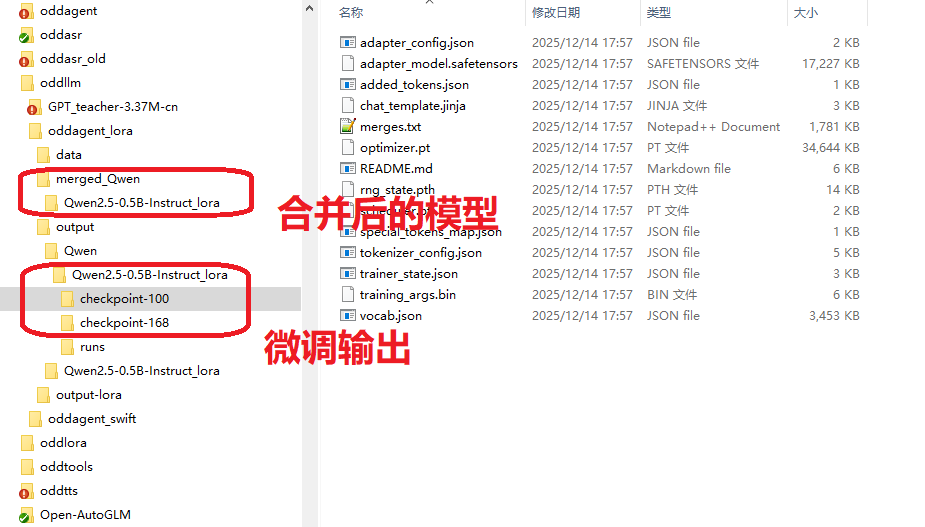
# 合并模型
swift export \
--adapters /mnt/data/jacky/output/v3-20251220-164606/checkpoint-3058/ \
--merge_lora true --output_dir merged_qwen3_4b_lora_swift
# 通过vllm加载运行
/usr/local/bin/python3 /usr/local/bin/vllm serve \
merged_qwen3_4b_lora_swift/ \
--host 0.0.0.0 --port 8003 --root-path / --trust-remote-code \
--gpu-memory-utilization 0.1 --tensor-parallel-size 2 \
--served-model-name xiaoluo随后可通过api调用
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:8003/v1", # vLLM服务地址
api_key="na" # vLLM无需鉴权,设为任意值
)
SYSTEM_PROMPT = ""
text = "你是谁"
response = client.chat.completions.create(
model="xiaoluo",
messages=[{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content": text}],
temperature=0.0,
max_tokens=1000
)
print(response.choices[0].message.content)2)通过swift进行部署
CUDA_VISIBLE_DEVICES=0,1 \
swift deploy \
--model merged_qwen3_4b_lora_swift/ \
--infer_backend vllm \
--served_model_name xiaoluo \
--vllm_gpu_memory_utilization 0.3 \
--vllm_max_model_len 2048 \
--port 8001四、补充说明
1. 训练耗时参考
- 最近的一次ms-swift的微调训练是在阿里的PPU-ZW810E芯片上跑的,这个芯片比较强,单卡96G显存,在Qwen2.5-0.5B-Instruct模型上,跑一轮SWIFT训练大概5分钟左右。
- 之前用AutoDL上的一张4090(24G显存),在Qwen3-4B-Instruct模型上跑一轮SWIFT约15到20分钟左右。
2. ms-swift适用场景
中小团队 / 开发者:在消费级 GPU 上快速微调你需要的模型(支持很多模型,具体看官网介绍),适配客服、知识库问答等场景。多模态任务:快速开发图像 – 文本、视频 – 文本交互应用(如图文生成、VQA)。企业落地:低成本迭代大模型,支持增量微调与量化部署,降低算力成本。
五、广而告之
新建了一个技术交流群,欢迎大家一起加入讨论。扫码加入AI技术交流群(微信)关注我的公众号:奥德元
让我们一起学习人工智能,一起追赶这个时代。
(若二维码过期了,可私信我)
一点吐槽:貌似我写自己想做的事情,比如:ASR/TTS/Agent/MCP等等,写了一堆开源项目和代码,基本上没什么人关注,写一些更简单、入门级的文章反而看的人稍微多一点。

{kind=link}
{kind=link}
One thought on “【有手就行】SWIFT:花20分钟把大模型的名字变成你的名字”