一、说在前面
训练基座大模型那都是大公司们的事情,普通人、普通公司肯定是玩不起的,但是作为一个技术人,你可以不去做真正的大模型训练,但是你还是有必要知道和了解一下一个大模型是如何训练出来的。
而GPT_teacher-3.37M-cn 是一个很好的示例项目,让你可以用一台普通的PC,用CPU来训练一个3.37M的中文GPT模型,整个训练耗时不到20分钟,回答训练集里的问题的效果也还是挺不错的。感兴趣的同学可以用这个项目来练手、实操复现一下“自己动手从0开始训练一个大模型”的完整流程。
二、项目概述
一个轻量级中文GPT模型项目,专为在CPU上快速训练和演示而设计:
模型参数量:3.37M
架构:4层Transformer解码器
特点:使用RMSNorm、RoPE位置编码、权重共享等优化技术
目标:45分钟内在普通CPU上训练出可用的中文问答模型
参考训练时长:
- 我的笔记本:CPU: i7-8850H CPU @ 2.60GHz+16G内存,整个训练花了1419.35秒,约需要23.65分钟。
- 一台Mac Pro(2.6GHz 6核 i7, 16GB内存),整个训练1186.8秒,约需要19.78分钟。
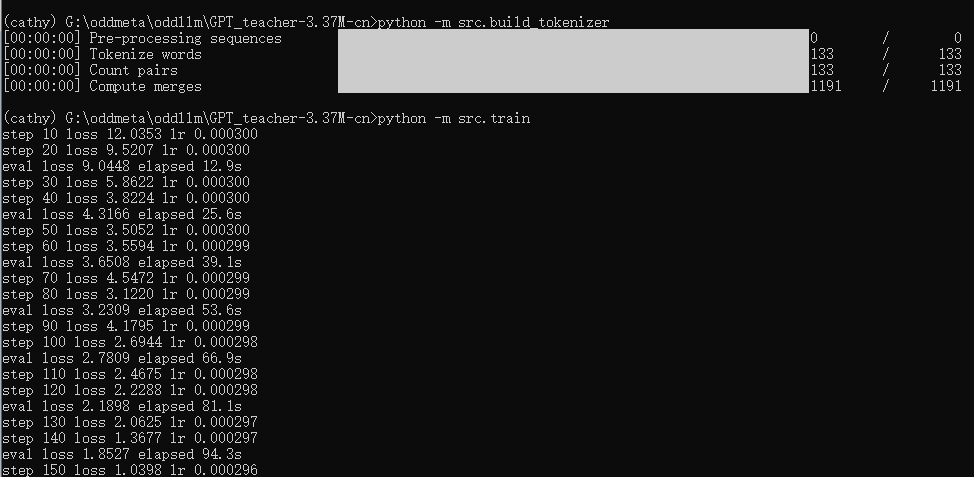
三、完整复现流程
介绍完了,就让我们来实操整个从0到1的训练吧。
先下载代码:
git clone https://gitee.com/baidumap/GPT_teacher-3.37M-cn1. 环境准备
# 进入项目目录
cd g:\oddmeta\oddllm\GPT_teacher-3.37M-cn
# 安装依赖
python -m pip install -r requirements.txt依赖项包括:
pip>=21.0 # 确保依赖解析能力,避免安装失败
torch>=2.2,<2.5 # 锁定 2.x 稳定区间,2.5+ 已完善 NumPy 2.x 支持,但暂不冒险
PyYAML>=6.0,<7.0 # 限制在 6.x 稳定系列,避开未来 7.x 大版本变更
numpy>=1.24,<2.0 # 核心修复:满足原版本要求,同时彻底避开 NumPy 2.x 兼容问题
tokenizers>=0.15,<0.25 # 锁定 0.15-0.24 稳定区间(Hugging Face 官方推荐)
sentencepiece>=0.1.99,<0.2.0 # 限制在 0.1.x 系列,避免 0.2.x 重构版本风险2. 构建中文分词器
python -m src.build_tokenizer这将:
- 使用BPE(字节对编码)算法训练分词器
- 设置ByteLevel解码器确保中文输出正常
- 保存到tokenizer/tokenizer.json
3. 配置文件确认
config.yaml包含了所有必要配置,我在这里给每个参数加了个说明,以便于理解每个参数的意义。
model:
n_layer: 4 # 模型的Transformer层数,决定了模型的深度。这个小模型使用4层,平衡了参数量和性能。
n_head: 4 # 注意力头的数量,每个头可以学习不同的语义表示。4个注意力头适合小参数量模型。每个头的维度为64(256/4)。
n_embd: 256 # 嵌入向量的维数,决定输入的维度。这个小模型使用256维的嵌入向量。
seq_len: 128 # 序列最大长度,模型能处理的最大token数量。设为128是为了在CPU上高效训练。
dropout: 0.0 # 丢弃率,用于防止过拟合。决定模型训练时是否进行dropout。这个小模型不使用dropout。
training:
batch_size: 16 # 批次大小,决定每次训练的样本数量。这个小模型使用16个样本进行训练。
micro_batch: 4 # 实际每次前向传播的批次大小,用于梯度累积。微批次大小,每个批次进一步分为4个微批次进行训练。这个小模型使用4个微批次。
lr: 0.0003 # 学习率,决定模型训练时参数的更新速度。这个小模型使用0.0003的学习率。
weight_decay: 0.01 # 权重衰减,一种正则化方法,防止模型过拟合。权重衰减决定模型训练时参数的更新大小。这个小模型使用0.01的权重衰减。
max_steps: 2000 # 最大训练步数,决定模型训练的轮数。这个小模型使用2000个训练步数。
warmup_steps: 5 # 预热步数,决定模型训练时参数的预热数量。这个小模型使用5个预热步数。
eval_interval: 20 # 评估间隔,决定模型训练时评估的间隔。这个小模型使用20个训练步数间隔评估模型性能。
save_dir: checkpoints # 模型保存目录。
seed: 42 # 随机数种子,决定模型训练时参数的初始化。这个小模型使用42作为随机数种子。
data:
train_path: data/train.jsonl # 训练数据路径。
val_path: data/val.jsonl # 验证数据路径。
format: instruct # 数据格式,这里使用instruct格式,包含prompt和completion字段。
tokenizer:
type: hf_tokenizers # 分词器类型,这里使用hf_tokenizers,即Hugging Face的分词器。
path: tokenizer/tokenizer.json # 分词器路径,这里使用tokenizer/tokenizer.json。4. 执行训练
python -m src.train5. 测试模型
训练完成后,根据src/train.py中的代码,最终会在config.yaml指定的目录下(checkpoints)生成一个标准的模型,以及一个量化的模型,分别是:
- last.pt
- quantized.pt
然后你可以用下面的命令来测试一下训练集(位于data/train.jsonl)里的一些问题:
- 测试问题1:解释RoPE的作用
python -m src.infer --prompt "解释RoPE的作用" --ckpt checkpoints/last.pt --temperature 0.0 --show_label- 测试问题2:解释蒸馏水与纯水区别?
python -m src.infer --prompt "解释蒸馏水与纯水区别?" --ckpt checkpoints/last.pt --temperature 0.0 --show_label- 测试量化模型
python -m src.infer --prompt "什么是注意力机制?" --ckpt checkpoints/quantized.pt --temperature 0.0 --show_label四、关键技术点解析
在这个示例的大模型训练里,我们基于Decoder-only的Transformer(因果语言模型),使用下三角掩码确保每次只关注历史信息,这正是GPT系列模型能够生成连贯文本的核心。
1. 训练参数说明
具体的训练参数我在上面的config.yaml里给每个参数都写了一个注释,用于说明每个参数的意义。而总结概括一下这个配置参数的话,主要如下:
- 模型结构优化:
- 使用RMSNorm代替LayerNorm,计算更高效
- 采用RoPE相对位置编码,避免位置编码长度限制
- 词嵌入与输出层权重共享,减少参数量
- 训练优化:
- 梯度累积实现大批次效果
- 学习率预热防止训练不稳定
- 仅对答案部分计算损失(通过ignore_index=-100)
- CPU优化:
- 动态量化减小模型体积
- 设置合适的线程数
- 禁用DataLoader多进程
2. 关键代码
- 因果掩码与前向传播:src/model.py: 95–103
- RoPE实现:src/model.py: 18–31
- 自注意力前向:src/model.py: 41–58
- 残差块:src/model.py: 81–84
五、补充说明
1. 仅3.37M参数远达不到scale law
这个项目只是一个演示项目,教你如何自己动手从0到1来训练一个大模型,但是必须要知道的是大模型有个别称是 scale law,所以走传统transfomer路线的话,注意力是非常吃参数的,这么一个参数量,其输出完全肯定不会非常好(除非你问的就是训练集里的知识)。
同时在这个项目的训练集(位于data/train.jsonl)里你也可以看到,虽然有510条训练数据,但实际上里面的内容全是Ctrl C + Ctrl V出来的,真正的prompt和completion就几条。
2. 为什么问一些不在训练集里的问题时,返回乱七八糟的东西,而不是“不知道”
大模型的本质是一个词语接龙游戏,每出一个字,根据概率去预测下一个字是什么。其目标是生成流畅的文本,而不是正确的文本,它只是在模仿训练集里的文本概率,而不是真正的理解内容,所以最终的效果完全取决于你给它的训练数据。
因此,当你去问不在训练集里的问题的时候,大模型就只能随便的去猜下一个字可能是什么字,而不是直接给你回答一个“不知道”,这也是大模型“幻觉”的由来。
3. 关于大模型幻觉
大模型幻觉主要有四种幻觉类型:前后矛盾,提示词误解,事实性幻觉,逻辑错误。
幻觉主要有三大成因:数据质量问题,生成机制缺陷,模糊指令。
幻觉通常有五种解决方案:精准提示词、示例学习、调参、RAG技术、幻觉检测方案,并让大模型学会给答案标注“参考文献”(溯源)。
4. 大模型使用
对于一个已经训练好的模型,在API调用时有几个常用的参数是可以影响大模型给你一个你期望的结果的,这几个参数主要是:temperature、top-k、top-p,以及prompt引导。
temperature:通常0.1到0.5。温度越低,输出越稳定,温度越高,输出越天马行空(也可以说越有创意)。top-k:10到30。只保留前 k 个选项,而如果这 k 个选项里都没有 “有依据的答案”,模型就只能输出prompt引导的 “不知道”。top-p:0.1到0.4。只保留累计概率 p 的选项。top-p与top-k一起用,在top-k中的给出的词汇中进行二次筛选。无依据时,这个词集中只会包含 “不知道” 这类标准回复,而非编造的低置信词。prompt:在 prompt 中明确指令:“对于你不知道、没有相关信息的问题,直接回答‘不知道’,无需额外解释。”
祝同学们都能轻松上手大模型,一起学习AI,一起追赶时代。

{kind=link}
2 thoughts on “【有手就行】自己花20分钟从0开始训练一个“大模型””
又到年底了,真快!