一、前言
上周扣子成为第一个支持skills的国内的大模型,但是这阵子公司这边的事情一直很忙,项目急,领导们都盯着,所以一直没有没时间去测试。
但是事实上之前我已经用open code desktop试过来实现一个skills,只是文章写了一半,一直没发,今天晚上再重新整理了一下,让open code实际来写一个skills,并将完整的过程给大家做一个演示,相信看了之后,任何一个小白(不需要编程知识)都可以来实现自己想要的功能了。
我一直想给小落同学做一个书签功能。原因如下:
当你看到一篇好文章,想保存下来慢慢看,结果网页上广告横幅、导航栏、推荐阅读啥的占了一大半空间。等到真正想看的时候,还得翻半天找正文。更烦人的是,现在很多网站都是单页应用,用JavaScript动态加载内容。直接用浏览器保存或复制粘贴,往往只能拿到个加载动画,完全看不了内容。
于是我就想,能不能做一个工具,自动抓取网页,去掉那些乱七八糟的东西,把正文提取出来,保存成干净的Markdown格式?图片也能一并保存下来。
现在刚好用OpenCode Desktop来演示一下,如何实现一个书签功能的Skills,而且可以通过MCP协议接入外部服务。
二、测试运行环境
1. 测试环境
依旧在我这个超过十年的老笔记本上,我的操作系统是Windows 7。如果你是新版本的Windows,或者是Mac OS,或者Linux,整个流程基本上也没什么差别(理论如此哈,我还没验证过,若真在安装使用open code时,有什么问题也可提出来)。
2. 测试使用的版本
Open Code Desktop 的下载安装我就快速跳过了,大家随便哪儿搜一下都能下载到。
版本:OpenCode Desktop v1.1.34官网地址:https://opencode.ai下载地址:Open Code 国内版(如阿里云效 Open Code、华为云 Open Code),或开源版Open CodePython:因为需要用到Python,所以还请前置安装一下Python 3.12+,从python.org下载,或者国内任何一下访问比较快的站点下载。
安装完成OpenCode Desktop后,启动,完成基础登录 / 初始化配置,比如:选择使用的大模型。
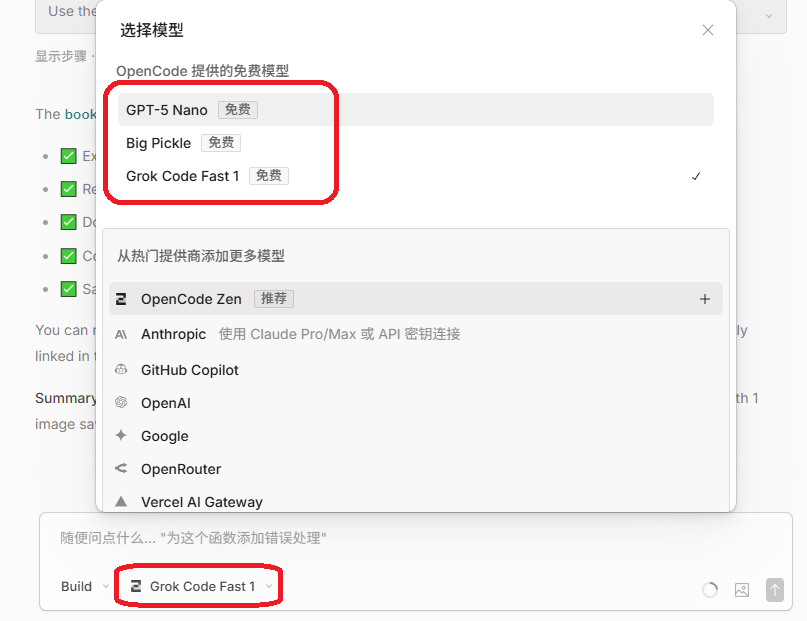
三、从零开始实现书签功能Skills
1. 给OpenCode的提示词
直接在OpenCode Desktop里,告诉他你想要一个什么样的东西,一些具体的要求。
注:这里的描述很重要,而且最好是描述能够一次成型。
但是实际上一次成型是不可能的。不过你可以生成一次后,看下效果是否跟你预期一致,如果不一致,那就直接左上角:新建会话(+ New session),然后再一步步完善你的描述,然后一次次重试直到你基本满意。
以下是我的提示词:
写一个关于国内如何用open code来实现一个完整的skills的文章。
需要包括:
1. 如何在windows下配置open code的skills
2. 完整的skills的markdown
3. 如何在open code里调用、运行这个skills
4. 其它必要的未尽事宜
同时这个skills要求:
1. 可以抓取通用网页内容保存为markdown。
2. 保存的内容要求对网页进行分析,仅提取实际的内容,去除可能存在于上下左右的各种不必要的内容。
3. 支持抓取并保存图片。
4. 实际执行抓取的功能用python 3.12,将其封装为一个mcp,并且这个mcp应该调用gofastmcp.com的fastmcp来实现,mcp的名取命名为bookmark_it。
5. 还需要一个实际调用这个mcp的示例。
实现后请自行在open code里验证一遍,各项功能是否OK。2. OpenCode Desktop的输出
输入提示词之后,OpenCode就开始工作了,大概等待了两三分钟,它给我输出了一个结果,同时也创建好了整个书签Skills,书签的MCP Server:bookmark_it_server.py,以及这个MCP Server的Python依赖,具体项目目录结构如下:
.opencode/
├── opencode.json # OpenCode配置
└── skills/
└── bookmark-it/
└── SKILL.md # Skill定义
bookmark_it_server.py # MCP服务器代码
requirements.txt # Python依赖3. 关键代码
1)MCP服务器配置
代码位置: .opencode/opencode.json
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"bookmark_it": {
"type": "local",
"command": ["python", "bookmark_it_server.py"],
"enabled": true
}
}
}2)MCP服务器主要代码
代码位置:bookmark_it_server.py
from fastmcp import FastMCP
from playwright.sync_api import sync_playwright
app = FastMCP("bookmark_it")
@app.tool()
def bookmark_page(url: str, save_images: bool = True, output_dir: Optional[str] = None) -> str:
# 用Playwright抓取动态内容
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(url, wait_until='networkidle')
html_content = page.content()
browser.close()
# 提取主要内容
title, content_html = extract_main_content(html_content, url)
# 转换为Markdown
markdown_content = h.handle(content_html)
# 保存文件
with open(f"{output_dir}/article.md", 'w', encoding='utf-8') as f:
f.write(f"# {title}\n\n{markdown_content}")
return f"已保存到 {output_dir}"3)Skills配置
代码位置:.opencode/skills/bookmark-it/SKILL.md
name: bookmark-it
description: Bookmark web pages by converting them to clean markdown with images
license: MIT
compatibility: opencode
metadata:
audience: developers
workflow: documentation
(省略数百字。。。可自行用我上面的提示词生成)四. 如何调用、运行这个Skills
1. 加载Skill
在OpenCode Desktop界面中,输入以下命令来加载skill:
skill({ name: "bookmark-it" })加载成功后,你会看到skill的描述信息。一旦skill加载,你就可以使用MCP服务器提供的工具。
2. 运行Skills:下载保存网页书签(保存图片到本地)
在OpenCode Desktop界面中,输入以下命令:
下载一下这个网页: https://www.oddmeta.net/project-xl3. 批量处理示例
skill({ name: "bookmark-it" })
收藏下面这些网页,并为每个网页保存一个单独的markdown文件到当前目录下:
1. https://www.oddmeta.net/archives/10360.html
2. https://www.oddmeta.net/archives/10322.html
3. https://www.oddmeta.net/archives/10337.html执行完了,就可以在这个Skills的目录下看到下载好的markdown文件,同时包括了这些网页里的图片。
五. 其他必要的未尽事宜
1. 扩展功能
你也可以通过修改 bookmark_it_server.py 来添加更多功能:
- 支持PDF生成
- 自定义内容过滤规则
- 批量处理多个URL
- 集成到其他工具链
要扩展的话,也很简单,直接在Open Code Desktop时跟它说即可。
2. 踩坑经验
1)生成的代码运行报错
由于我使用的都是一些白嫖的大模型,这样其编码能力相比于一些收费的模型肯定会稍逊一筹,容易出现一些bug,容易运行时报错。
但是看到报错,你直接把整个错误copy给Open Code即可,它会直接帮你改掉。
2) 动态内容处理
一开始生成的代码没用Playwright,用requests直接抓HTML,结果很多SPA网站只能拿到 。后来加了Playwright,一下子解决了大部分问题。
3) 内容提取算法
BeautifulSoup很好用,但提取主要内容还是得自己想办法。下面几个规则是比较重要的(但是也都可以让OpenCode来帮你搞定):
- 优先找常见的content容器
- 计算文本密度最高的区域
- 过滤掉广告和导航元素
- 虽然不是最完美的,但对于大部分技术文章效果不错。
六、广而告之
通过以上步骤,你就可以配置和使用这个网页书签skills了。如果有需要的话,你也可以直接把这个Skills上传到扣子Skills商店,让大家都可以用。
Vibe Coding够简单吧!
新建了一个技术交流群,欢迎大家一起加入讨论。
扫码加入AI技术交流群(微信)
关注我的公众号:奥德元
让我们一起学习人工智能,一起追赶这个时代。
(若二维码过期了,可私信我)


{kind=link}
{kind=link}
2 thoughts on “手把手带你用OpenCode实现一个完整的Skills:网页书签”
OpenCode默认输出语言是英文,如果你希望将其默认语言全局设定为中文的话,可以这样:
创建或编辑 ~/.config/opencode/opencode.json 文件:
{
“$schema”: “https://opencode.ai/config.json”,
“instructions”: [
“请始终使用中文进行思考和回复”,
“所有输出内容都必须是中文”
]
}