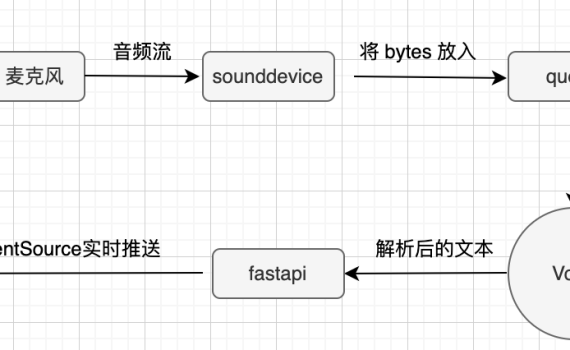
前面在我的笔记本上用FunASR和PaddleSpeech为小落同学整合了一下ASR的功能,但是发现在我的阿里云ECS上跑不动,由于是乎就想找一个最轻量级的ASR模型,让小落同学也可以用上免费白嫖的ASR功能。我的要求很简单: 翻烂Google, Baidu, Bing,搜遍github之后,当前收到的评估是:Vosk 是最紧凑、最轻量级的语音转文本引擎之一,可以支持20多种语言或方言,包括:英语、中文、葡萄牙语、波兰语、德语等,还可以支持Windows, Linux, Android、iOS和Raspberry Pi,而且Vosk 提供了小型语言模型,不占用太多空间,理想情况下,大约只有50MB。然而,一些大型模型可以占用高达1.4GB。该工具响应速度快,可以连续将语音转换为文本,还提供流媒体API(与流行的语音识别python包不同),还支持说话人识别(这个我暂时还没试过)。 既然如此,我只能说:兄弟,就是你了。以下是关于Vosdk从技术原理到实战代码。 一、Vosk相关介绍 在众多 ASR 工具中,Vosk 凭借以下核心优势脱颖而出: 二、Vosk 项目核心信息 三、快速安装指南(以 Python 为例) 1. 环境准备 要求使用Python 3以上版本环境,除非你的环境是古董级别的,不然都是Python 3以上,但是为防万一,还是建议你升级一下。虚拟环境就直接用小落同学的虚拟环境,不另外创建虚拟环境,也算是为我的ECS省点空间。 2. 安装 Vosk 库 3. 下载语音模型 支持的模型列表:https://alphacephei.com/vosk/models其中中文的我看有三个 模型名 大小 Word error rate/Speed 说明 License vosk-model-small-cn-0.22 42M 23.54 (SpeechIO-02) 38.29 (SpeechIO-06) 17.15 (THCHS) Lightweight model for […]
Vosk
1 post