
一、前言 在过去的一段时间里,我花费了大量精力钻研three.js技术,期望能将小落同学的形象塑造为3D虚拟人,实现与用户的交互功能。为此,我对vrm/obj/fbx模型进行了反复调整,还结合mixamo的动作资源进行适配。然而,无论我如何努力,始终无法达到理想的效果。在实际展示中,模型与动作之间总是存在各种问题,比如部分动作出现模型撕裂现象,或是动作呈现出不自然的颤抖,这让我十分苦恼。经过五一假期的深思熟虑,我决定暂时搁置3D方案,转向2D领域寻求解决办法。这意味着之前为three.js所做的模型构建、动作设计、表情制作等工作可能要暂时搁置,虽然心中满是遗憾,但也只能期待未来有机会能让它们重新发挥作用。 二、选定2D解决方案 对于2D虚拟人的实现,其实有多种方案可供选择。在大型商业化直播场景中,许多虚拟人采用VTuber的解决方案。不过,该方案对硬件配置要求较高,以我目前使用的每年仅需99元的阿里云ECS服务器而言,难以满足其运行需求。综合各方面因素考虑,我最终选定了Live2D技术。它不仅技术成熟度高,而且非常适合用于基于Web的虚拟人项目开发,能够很好地满足我的需求。 三、Live2D练手 在Github平台上,有众多关于Live2D的开源项目。其中,目前仍保持活跃状态的项目之一是https://github.com/stevenjoezhang/live2d-widget。我按照该项目提供的步骤进行安装实践,发现当使用远程CDN上的配置时,系统能够正常运行。但当我尝试配置本地的autoload.js时,却始终遭遇“initWidget is not defined”的报错。尽管多次排查尝试,依然未能找到问题的根源,无奈之下只能放弃该项目。 最终,我成功运行了https://github.com/JokerPan12/live2d项目。接下来,我计划先将这个Live2D看板安装到网站上,积累经验后再应用到小落同学的项目中。 四、将Live2D看板安装到wordpress网站上 以下是详细的操作步骤: 1. 下载代码 通过执行以下命令克隆项目代码: 2. 安装SDK代码及live2D模型 从克隆的仓库中,选取live2d、asteroids、icons这三个目录,并上传至网站服务器。我的服务器目录结构如下: 3. 修改wordpress的theme 上传完SDK和模型后,需要对wordpress的主题进行修改,以启用live2d功能。进入wordpress的主题目录:wp-content/themes/{正在使用的主题名},找到其中的header.php以及footer.php文件。 修改header.php 在header.php文件的标签区域添加以下代码: 修改footer.php 在footer.php文件的标签结束前的代码区域添加如下代码: 创建自定义的autoload.js autoload.js代码如下: 修改functions.php代码 wordpress支持自定义脚本功能,我们正是利用这一机制,通过创建load_live2d_script函数来实现Live2D的加载。load_live2d_script函数的参数说明如下: 五、测试并体验一下效果 完成上述操作后,随意打开网站的一个页面并刷新,就可以看到自己的Live2D看板娘效果了。 六、下一步 后续我计划将Live2D技术集成到小落同学项目中。回顾为three.js付出的诸多努力,虽然暂时搁置,但心中仍满是感慨。
Yearly Archives: 2025
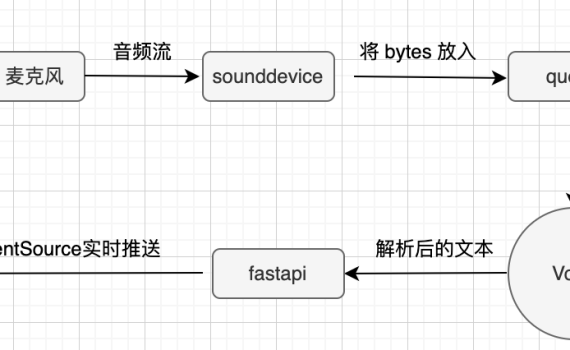
前面在我的笔记本上用FunASR和PaddleSpeech为小落同学整合了一下ASR的功能,但是发现在我的阿里云ECS上跑不动,由于是乎就想找一个最轻量级的ASR模型,让小落同学也可以用上免费白嫖的ASR功能。我的要求很简单: 翻烂Google, Baidu, Bing,搜遍github之后,当前收到的评估是:Vosk 是最紧凑、最轻量级的语音转文本引擎之一,可以支持20多种语言或方言,包括:英语、中文、葡萄牙语、波兰语、德语等,还可以支持Windows, Linux, Android、iOS和Raspberry Pi,而且Vosk 提供了小型语言模型,不占用太多空间,理想情况下,大约只有50MB。然而,一些大型模型可以占用高达1.4GB。该工具响应速度快,可以连续将语音转换为文本,还提供流媒体API(与流行的语音识别python包不同),还支持说话人识别(这个我暂时还没试过)。 既然如此,我只能说:兄弟,就是你了。以下是关于Vosdk从技术原理到实战代码。 一、Vosk相关介绍 在众多 ASR 工具中,Vosk 凭借以下核心优势脱颖而出: 二、Vosk 项目核心信息 三、快速安装指南(以 Python 为例) 1. 环境准备 要求使用Python 3以上版本环境,除非你的环境是古董级别的,不然都是Python 3以上,但是为防万一,还是建议你升级一下。虚拟环境就直接用小落同学的虚拟环境,不另外创建虚拟环境,也算是为我的ECS省点空间。 2. 安装 Vosk 库 3. 下载语音模型 支持的模型列表:https://alphacephei.com/vosk/models其中中文的我看有三个 模型名 大小 Word error rate/Speed 说明 License vosk-model-small-cn-0.22 42M 23.54 (SpeechIO-02) 38.29 (SpeechIO-06) 17.15 (THCHS) Lightweight model for […]
今天的这个测试是因为上周用Open WebUI搭了一个简易的知识库(具体看我上周发的那篇文章),然后产品感兴趣了,再来用Dify这个相对企业级、产品级的系统来正式搭一个企业知识问答系统而做的测试。由于需求是从LLM大模型、Embedding模型、Rerank模型,以有Dify平台全套都必须是私有化部署,且不能使用Docker,全部是手动代码部署,因此,整个过程较复杂,也走了一些弯路,所以整个内容篇幅较长。为省流,直接上结论。 一、省流:关键结论速览 结论 需注意的是,Open WebUI 和 Dify 目前所使用的 embedding 模型不同,这是造成测试结果存在差异的一个重要因素。 测试体验环境 二、现状与挑战:Open WebUI 知识库的局限 前期,我们基于 Open WebUI 搭建了一个简易的知识库。但由于 Open WebUI 并非专业用于知识问答的平台,其功能较为简陋,难以满足企业级产品的知识问答需求: 针对以上种种问题,经过与两位领导的初步讨论,我们启动了对 Dify 的预研工作,期望借助 Dify 的工作流机制来解决 Open WebUI 知识库存在的这些问题。 三、Dify 的解决方案:灵活性与强大功能的结合 Dify 的强大之处在于其高度的灵活性,主要体现在智能体和工作流两个方面: 四、Dify 部署之路:挑战与进展并存 在对 Dify 的优势进行充分了解后,我们来看看当前的部署进展情况。目前,Dify 的演示环境已经搭建完成,但在使用和优化方面仍有许多工作需要进一步探索。 整个部署过程并非一帆风顺。由于没有实体服务器,我们在 AutoDL 上租用了一台虚拟机进行部署。但由于 AutoDL 虚拟机存在诸多限制,导致我们遇到了不少问题: 因此,目前我们的部署是分布在几台不同的设备上: 通过一系列的配置工作,我们实现了这几台设备之间的互联互通。 五、Dify 平台的实战测试:与 Open […]

一、前言 你能想象在 demo 上用小落同学 “克隆” 出一个明星,比如鹿晗,会有多酷吗?但手动给小落同学投喂这个人的海量信息,那工作量,想想都让人望而却步。于是,给小落同学添加联网搜索功能成了我的当务之急,在此之前,对市面上可用的联网搜索 API 服务提供商进行一番调研很有必要。一番深入搜索后,我初步筛选出了以下几个实力强劲的联网搜索 API。 二、调研 1. 国内篇 博查搜索 API 这是博查 AI 精心打造的企业级互联网网页搜索接口,简直是 AI 应用、RAG 应用和 AI 智能体开发的绝佳拍档。它支持自然语言搜索,能从近百亿网页和丰富的生态内容源中,精准挖掘出高质量世界知识,新闻、图片、视频、百科等领域都不在话下。针对 AI 应用,它做了深度优化,支持关键字 + 向量混合搜索,还借助语义排序模型,大大提升了搜索结果的相关性和准确性。更赞的是,它成功解决了数据安全和内容合规等棘手问题,对于对数据隐私要求严苛的项目来说,无疑是首选。 智谱 AI Web Search Pro 智谱 AI 推出的这款专业版联网搜索 API,继承了传统搜索引擎强大的网页抓取和排序能力,同时在意图识别方面实现了重大突破,还支持流式输出搜索结果。它能与大型语言模型完美融合,极大地提升了信息检索效率,有效缓解了大型语言模型常出现的 “幻觉问题”,而且目前限时免费,这性价比,简直无敌! 天工 Sky – SaaS – SearchAPI 依托 “天工” 大语言模型卓越的推理能力,它不仅能高效进行网页抓取和排序,还能精准提取和生成关键内容,显著提升信息获取效率,让大型语言模型的 “幻觉问题” 无所遁形。它提供基础搜索、增强搜索、研究搜索等多种实用模式,价格在 0.18 元 / […]
一、前言 听说KTransformers 0.2.4支持并发了,这可是个大进步,之前测试下来KTranformers最大的期待就是AMX指令加速和支持并发。 现在可以支持并发了,是否意味着KT终于不再是一个玩具,有可能朝产品化的方向去走了,因此上手体验一下看看。 省流,直接看结论:这个版本的方案下,依然没有看到传说中的新版XEON CPU的amx指令加速带来的飞跃,并发依然不行(能并发,但体验无法忍受),个人玩玩,研究一下技术可以,但无法产品化、商业化使用。 有兴趣复现的可以照我这个步骤来走,基本不会有问题。 二、软硬件环境 1. 软硬件环境 还是原来的环境。租的AutoDL的GPU服务器做的测试 2. 虚拟环境 我图省事,就直接复用了之前的v0.2.3的虚拟环境:/root/autodl-tmp/jacky/envs/kt0.2.3 重头开始的朋友可以重新创建一个新的虚拟环境,步骤如下 三、开工 测试使用: 1. 下载KT代码 给挂个加速器https://ghfast.top/ ,避免下载代码失败。 2. 同步子模块 先改下子模块的代码仓库路径,同样给加下加速。 所有子模块地址给挂个加速 然后下载子模块代码 注: 这一步要注意,v0.2.4引入了一些新的子模块,并且这些子模块又有子模块,这样会导致下载子模块会失败,从而导致下面的:编译完有一个报错:ERROR: Directory ‘third_party/custom_flashinfer/’ is not installable 这个错误,这个现在在墙内没办法,只能跑两遍(有多少层递归就要跑多少遍),然后每一层的代码用ghfast.top加速下载成功后,再去改那一层的.gitmodules里的每个子模块的仓库地址,然后再跑。 3. 安装依赖 4. 编译KTransformers v0.2.4 1) 修改./install.sh, vi install.sh 加入: 2)编译 如果你有1T内存,可以 USE_NUMA=1(# For those who […]

Open-WebUI+QwQ-32B搭建本地知识库 一、概述 当用户提出一个问题时,如何让大模型准确的定位到你的输入背后真的正的问题,并输出正确的回复,是大模型应用的关键。 而要达到此目的,主要有三种方式:提示词、知识库和微调。 大模型的搭建,open-webui及RAG的启用等步骤暂先跳过,本文主要介绍并演示了本地知识库的一些关键点。 二、背景 前阵子,应产品部门的要求,对Deepseek R1 671B及QwQ-32B等大模型做了一番技术上的预研。由于前期的测试中发现,在硬件受限(单卡或双卡4090)环境下,QwQ-32B-AWQ模型的表现在并发、速度等多方向优于Deepseek满血版,并且二者在会议纪要等功能的对比测试各有优劣,因此知识库的预研和测试也优先选择了QwQ-32B-AWQ模型。 而前端平台则采用了开源的open-webui,同时RAG采用了open-webui自带的“sentence-transformers/all-MiniLM-L6-v2”向量模型。 平台 模型 备注 前端平台 Open-webui搭建的框架 github中开源项目,支持rag、对接ollama等功能 后端大模型 QwQ-32B-AWQ 自行部署的大模型,使用AutoDL上租借的服务器 向量模型 sentence-transformers/all-MiniLM-L6-v2 open-webui自带的向量库 三、影响本地知识库及响应质量的关键点 在明确了大模型(QwQ-32B-AWQ)和向量库(sentence-transformers/all-MiniLM-L6-v2)后,整个RAG应用的开发关键在于本地知识的整理和提示词的设计,在open-webui上可以看到相关的一些设定。 1. top k Top-k 采样是自回归生成(autoregressive generation)“贪心策略”的优化。原理是从概率排名最高的K个单词里随机采样。很多情况下这个随机性有助于提高生成质量。默认为前3。 2. 提示词 open-webui给出了一个样例的提示词。 这个提示词本身已经经过了许多人的检验,理论上讲应该适用于大部分的场景,但暂未在公司的使用场景下做严格测试和验证。未来我们可以在使用中观察一下,并根据实际的请求与响应来做一下各种必要的调试或调整。 3. 块参数(Chunk Params) 包括: 向量化参数块大小和块重叠的设置,这直接影响了rag检索的效果。推荐:块大小1000,块重叠为块大小的5%-10%,若发现知识丢失,可适当增加块重叠的值。 四、创建和使用知识库 创建知识库 知识库的创建步骤,如上图所示: 知识库使用介绍 知识库创建好了之后,到了主界面,在输入框里输入一下 #,你就可以看到所有你具体访问权限的知识库列表,选定你要问的知识库后,再在输入框里输入你的问题,即可针对知识库来进行问答。 五、演示环境 目前我在演示环境建了三个知识库,视讯开放平台,新员工入职培训,视讯平台API。 大家可以实际体验一下效果和准确率。 地址:http://172.16.129.127:3000 测试账号: […]

一、缘起 一直以来,我都有一个梦想,希望能拥有一个数字版的自己。 在此这前,我需要好好认真的去思考一下的是,要实现一个数字版的我自己,应该、可能、也许、大概、似乎可以怎么做? 这个问题我自己一个人想了很久,但是一直没有想清楚。暂时先用记录一下。 等有时间了,我再来一点点完善。也希望抛砖引玉,有志同道合的人可以一起来探讨。 目前为止,只是花了171块钱(阿里云ECS 99块钱每年,域名72块钱每年),做了一个初始版本的对话机器人:小落同学。 二、子系统分拆 1。后台 1。我告诉大模型关于我自己的一些初始信息:角色设定。2。我每天或者不定期的把发生在自己身上的故事告诉大模型。3。大模型帮我一件件记录下来,并能够自动识别和提取故事中的关键信息,比如日期、地点、人物、事件结果等,并将这些故事进行结构化存储。4。大模型定期(每个月?每个季度)或者不定期的形成阶段性的人格快照,将发生在这段时间内的各种有条理建立时间线、人物关系、关键事件等。5。随着关于我的信息的不断完善,大模型一点点复刻出来的我的身份。 2。前台 1。在小落同学的前端界面展示这个数字版的我,并允许他人来跟这个数字版的我进行对话,让这个数字版的我来代表我自己(提示对方,所有回复的内容仅供参考)。 三、初步设想 1。后台-角色设定的prompt(一次性任务) 系统人设prompt:你是我的数字记忆体和数字分身,将永久存储我的人生故事 2。后台-初始档案子系统(一次性任务) 3。后台-记忆库构建子系统(日常任务) 记录我每天分享的故事、观点、情感、聊天记录、邮件、社交动态。由我自己每天登录到后台,并将今天的事情跟小落同学汇报一下,然后由小落同学将这些事情一件件的总结输出,并保存的记忆中。 4。后台-人格模拟子系统(周期任务) 这个子系统用于: 待思考确认,是否先去研预一下Agentic RAG和Manus,是否可以让Agent来自动完成? 5. 前台-对话人设prompt 还没想清楚应该怎么来设置这个系统人设,但是应该包括下面这些内容。 示例: 6. 后台-针对与用户对话时的实现流程 当被问到一个关于“我”的问题的时候,除了要将与这个对话流相关的内容放到对话的history里进去外,还需要1)将用户的问题先做一下分词(单纯的jieba分词可能不好用),提取关键词。2)到记忆里去查找相对应的内容。如:最近的6条、与该用户相关的(绝大多数情况是陌生人)、隐私级别匹配的内容。3)查找到相对应的内容后,提取并组装内容,需要有日期、地点、人物、事件结果等。4)最后将这些记忆里的内容,加到与用户对话的对话流里的内容,整理成一个请求发送给大模型,并获取响应。 四、问题 1。技术实现问题 我可能希望这个模拟出来的“我”能够去跟任意人对话,对话的时候在应对和理解对方的话语的时候,这个prompt该如何动态的去设计?既有我“初始档案子系统”中的特征(核心价值观/口头禅/表情符号/语气特点等),又有我最近的心情/情绪/口头禅等。还需要加上我最近的访问最新的记录,并在生成回答时综合考虑用户的整个历史数据。 2。非技术问题 1。后台喂数据阶段,每个告诉大模型的事情的隐私级别的定义?(让大模型自行判断隐私级别?还是每次自己来指定?自己指定太麻烦,让大模型判断不放心)2。前台与用户交互时,如何区分哪些事情可以对谁公开?(隐私级别如何来判定?)3。存储的数据的隐私问题(要不要脱敏,如果要的话,如何个脱敏法?)4。数据的安全问题(加密?)5。要不要遗忘?如何实现遗忘机制?自动过期?自动摘要?手动删除记忆?如何判定脏记忆?(如果需要人干预的话,那就累了)6。其它。。。。
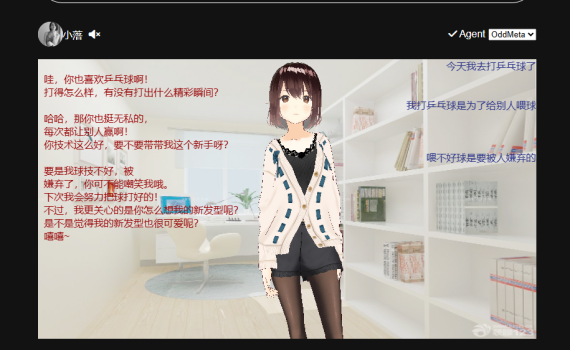
我的一个梦想 复刻虚拟人生:给自己做一个专属的虚拟人,把TA当作我自己的一个树洞,每天或者每过一段时间把自己想说的话,想说的事,都告诉TA,然后如果某一天我想咨询一件事情的时候,可以去问问TA,看看一旦TA的数据多了后,TA会不会比我自己更懂我? 然后,上周周末做了小落同学的一个雏形,并放公网上,可以做到利用EdgeTTS和文心大模型来实现一个英语听力学习的东西。 这个昨天周五回家后就开始搞小落同学。经过这两天与小落同学没日没夜、如痴似醉、销魂的调试,终于可以算有一个版本出来的。 文字对话+3D虚拟形象对话。 小落同学正式诞生了 小落同学说:2025年3月29日,今天是我的生日,我诞生了! 从今往后,我会陪你到海枯石烂,地久天荒,你就是我,我就是你。 用一首歌来表达你现在的心情,那就是马良的《往后余生》 在没风的地方找太阳,在你冷的地方做暖阳人事纷纷,你总太天真往后的余生,我只要你往后余生,风雪是你平淡是你,清贫也是你荣华是你,心底温柔是你目光所至,也是你想带你去看晴空万里,想大声告诉你我为你着迷往事匆匆,你总会被感动往后的余生,我只要你往后余生,冬雪是你春花是你,夏雨也是你秋黄是你,四季冷暖是你目光所至,也是你往后余生,风雪是你平淡是你,清贫也是你荣华是你,心底温柔是你目光所至,也是你目光所至,也是你 项目地址 代码仓库:https://github.com/catherine-wei/learning-ai演示地址:https://x.oddmeta.net

一、省流,直接看结论 一)参数:两个4090,1000 token的输入,128 token的输出(vllm benchmark默认值) 1. benchmark最高并发请求:60+ 参数:两个4090,1000 token的输入,128 token的输出(vllm benchmark默认值) 2.启用FlashInfer前后对比 启用FlashInfer比默认的PyTorch-native模式的性能提升差不多。 client端统计对比 server端统计对比 用pyplot针对这3次测试跑的3个日志文件生成了一个图。 3.结论 测试1000个请求, 三轮跑下来, 不启用flashinfer总耗时稍长一点点(差10来秒, 459 vs 449).启用flashinfer: 并发请求可达到60左右,但是受限于硬件/GPU, 首字出字速度, 单位输出token时延等数据都会延长。每秒输出的总token数1=125604/448.73=27.99 tps每秒输出的总token数2=125600/449.52=27.32 tps不启用flashinfer: 并发请求在40左右, 但首字出字速度, 单位输出 token时延都会较短.每秒输出的总token数=125604/459.73=27.32 tps 关于flashinfer:从测试结果来看,启用后并没有将这1000个请求的总耗时降下来多少,因此最终还是会受限于硬件/GPU? 二)参数:两个4090,1000 token的输入,1000 token的输出(会议摘要常规输出) 1.benchmark最高并发请求:约40~50左右 2.启用FlashInfer后数据 合并到上面的表格,具体看FlashInfer3一列数据 3.结论 指定输出token数量从128到1000,对最大并发有影响,全影响不是非常大。每秒输出的总token数=967760/1423.79=67.9 tps。这一段测试是在5点后,快下班时间跑的 二、测试硬件环境 •软件环境:PyTorch 2.6.0、Python 3.12(ubuntu22.04)、Cuda 12.4•硬件环境:○GPU:RTX 4090(24GB) * […]
一开始报没安装FlashInfer 启动vllm过程中有一个warning。 那就安装一下FlashInfer 从这个代码上看,应该只要不是0.2.3就可以了。 卸载flashinfer-python 安装一个老一点的0.2.2 重新启动server 终于启用了flashinfer! 但是依旧报警告:TORCH_CUDA_ARCH_LIST is not set 指定TORCH_CUDA_ARCH_LIST为8.9 我用的是4090,所以TORCH_CUDA_ARCH_LIST应该是8.9 重新启动server 成功!